KI-Dokumentenkategorisierung: Wie BetterRegulation 50% der redaktionellen Zeit einsparte
Wir haben eine AI-gesteuerte Dokumentenkategorisierungsmaschine für BetterRegulation gebaut, die den redaktionellen Aufwand halbiert, indem sie die Extraktion und Klassifizierung von Feldern in rechtlichen Dokumenten automatisiert. Angetrieben durch Drupal Automatoren und AI, verwandelt das System stundenlanges manuelles Tagging in einen schnellen, zuverlässigen Workflow, der komplexen rechtlichen Inhalt perfekt strukturiert und durchsuchbar hält.
Schlüsselergebnisse
![]() 50% Zeitersparnis
50% Zeitersparnis
Die Bearbeitungszeit von Dokumenten wurde halbiert.
![]() 1 FTE-Äquivalent gespart
1 FTE-Äquivalent gespart
Freigesetzte Redaktionskapazität für Wachstum.
![]() 10s-2min Bearbeitungszeit
10s-2min Bearbeitungszeit
KI-Bearbeitung gegenüber 15 Minuten
bis mehreren Stunden manueller Arbeit.
![]() 2-350 Seiten bearbeitet
2-350 Seiten bearbeitet
Bearbeitet Dokumente aller Größen.
![]() Sehr hohe Genauigkeit
Sehr hohe Genauigkeit
Minimale Korrekturen erforderlich, <5% der Felder benötigen eine Anpassung.
![]() Reduzierung der kognitiven Belastung
Reduzierung der kognitiven Belastung
KI entfernt die Notwendigkeit des vollständigen Lesens von Dokumenten.
Über BetterRegulation
Herausforderung: der redaktionelle Engpass

Manuelle Dokumentenverarbeitung im großen Maßstab
Die Abwicklung von Rechtsdokumenten für eine Compliance-Plattform erfordert äußerste Genauigkeit. Jedes Gesetz, jede Verordnung oder Leitdokument muss gelesen, kategorisiert und mit Schlagworten versehen werden, und das in etwa 15 verschiedenen Bereichen – vom Dokumententyp und Gerichtsbarkeit bis zum Jahr der Verabschiedung und Organisation.
Für das Redaktionsteam von BetterRegulation hat dieser manuelle Prozess einen erheblichen operationellen Engpass geschaffen.

Der zweistufige manuelle Arbeitsablauf
Vor der Implementierung von KI durchlief jedes Dokument einen arbeitsintensiven Prozess:
Schritt 1: Lesen und Kategorisieren von Dokumenten
Der Redakteur:
- erhält ein neues Rechtsdokument (zwischen 2 und 350 Seiten lang),
- liest das gesamte Dokument sorgfältig durch, um seinen Inhalt zu verstehen,
- extrahiert manuell wichtige Informationen: Dokumenttyp, Titel, Jahr, Gerichtsbarkeit, Organisation,
- vergleicht diese mit bestehenden Taxonomiesystemen, um eine konsistente Kategorisierung zu gewährleisten,
- füllt etwa 15 verschiedene Felder im Content-Management-System aus.
Zeitbedarf: 15 Minuten bis mehrere Stunden pro Dokument, abhängig von Länge und Komplexität.
Schritt 2: Qualitätsüberprüfung
Der zweite Redakteur:
- überprüft alle Kategorisierungen,
- überprüft die Genauigkeit der Feldzuweisungen,
- überprüft die Übereinstimmung mit den Plattformstandards.
Die Schmerzpunkte
Lösung: KI-gestützter redaktioneller Arbeitsablauf
Der Ansatz: Erweitern, nicht ersetzen
Droptica näherte sich dieser Herausforderung, indem sie untersuchte, wie KI den redaktionellen Workflow ergänzen - nicht ersetzen - könnte. Durch gemeinschaftliche Discovery-Sitzungen mit BetterRegulation konzentrierten wir uns auf ein klares Ziel: die zeitaufwändige manuelle Lektüre und Dateneingabe zu eliminieren, während menschliche Editoren die Kontrolle über Qualität und Entscheidungsfindung behalten.
Die Philosophie war einfach: Lassen Sie KI die mühsamen, sich wiederholenden Arbeiten erledigen und lassen Sie den Menschen das Urteil, die Überprüfung und die Qualitätskontrolle übernehmen.
Entdeckungs- und Testphase
Anstatt direkt zur Implementierung überzugehen, führte das Droptica-Team gründliche Tests verschiedener Ansätze durch, um sicherzustellen, dass die Lösung zuverlässig, genau und einsatzbereit sein würde.

Methoden zur PDF-Verarbeitung
Rechtliche PDFs sind bekanntermaßen komplex. Sie enthalten oft:
- mehrere Spalten und komplexe Layouts,
- Kopf- und Fusszeilen sowie Seitenzahlen überall,
- eingebettete Bilder und Grafiken,
- Tabellen und strukturierte Daten,
- verschiedene Schriftarten und Formatierungsstile.
Wir haben mehrere Methoden zur Extraktion von sauberem, nutzbarem Text bewertet:
- Direkte PDF zu ChatGPT API - zeigte Einschränkungen bei komplexer Formatierung und Größenbeschränkungen von Dateien auf.
- Traditionelle PDF-Parsing-Bibliotheken - hatten Schwierigkeiten mit inkonsistenten Dokumentstrukturen und erzeugten einen störenden Output.
- Unstructured.io - erwies sich als der klare Gewinner.
Die Wahl von Unstructured.io erwies sich als entscheidend. Das Team stellte fest, dass sie keine Kontrolle über die PDF-Erstellung hatten – rechtliche Dokumente enthalten oft zahlreiche Formatierungsmarker und Metadaten, die das Kontextfenster verstopfen und die KI verwirren können. Mit Unstructured.io konnten sie diese während der Extraktionsphase herausfiltern. Das Team stellte auch eine deutlich bessere Genauigkeit und schnellere Verarbeitungsgeschwindigkeiten im Vergleich zu anderen Methoden fest.
Auswahl des Sprachmodells
Das Team testete mehrere große Sprachmodelle und bewertete sie anhand von drei Schlüsselkriterien:
- Genauigkeit: Konnte das Modell Dokumentinformationen korrekt identifizieren und kategorisieren?
- Geschwindigkeit: Wie schnell konnte es Dokumente von 2 bis 350 Seiten verarbeiten?
- Kosten: Wie hoch waren die Token-Kosten pro Dokument bei erwarteten Mengen?
Nach umfangreichen Tests mit echten BetterRegulation-Dokumenten stellte sich GPT-4o-mini als optimale Wahl heraus. Das Team testete andere Modelle, einschließlich einiger größerer Varianten, bemerkte jedoch keinen Qualitätsanstieg, der die Leistungseinbußen rechtfertigte. GPT-4o-mini bot die richtige Balance zwischen Geschwindigkeit, Genauigkeit und einem großen genug Kontextfenster (128K Tokens), um selbst die längsten Dokumente zu bewältigen.
Prompt-Engineering
Ein erheblicher Aufwand floss in die Erstellung von Prompts, die Informationen zuverlässig extrahieren und kategorisieren würden. Dieser iterative Prozess umfasste:
- Definieren von klaren, eindeutigen Anweisungen zur Feldextraktion.
- Bereitstellung vollständiger Taxonomielisten innerhalb des Prompt-Kontextes.
- Spezifizierung exakter JSON-Ausgabeformate für konsistentes Parsing.
- Hinzufügen von Validierungsregeln und Behandlung von Randfällen.
- Testen mit Hunderten von echten Dokumenten zur Verbesserung der Genauigkeit.
Wie es funktioniert
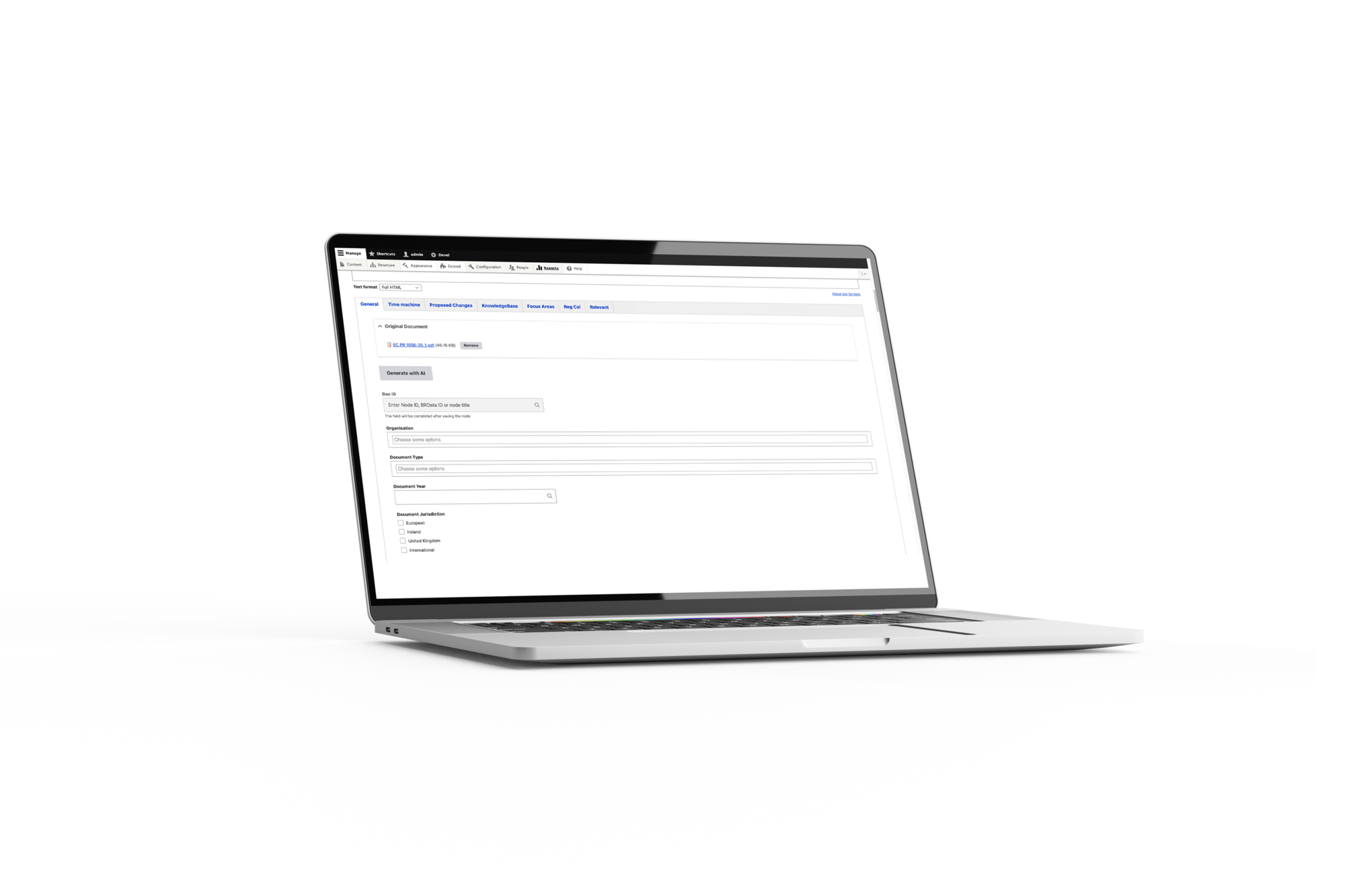
Die Auto-Vervollständigungsfunktion
Die Lösung integriert sich nahtlos in den bestehenden Drupal 11 Redaktionsworkflow von BetterRegulation.
Aus Sicht eines Editors:
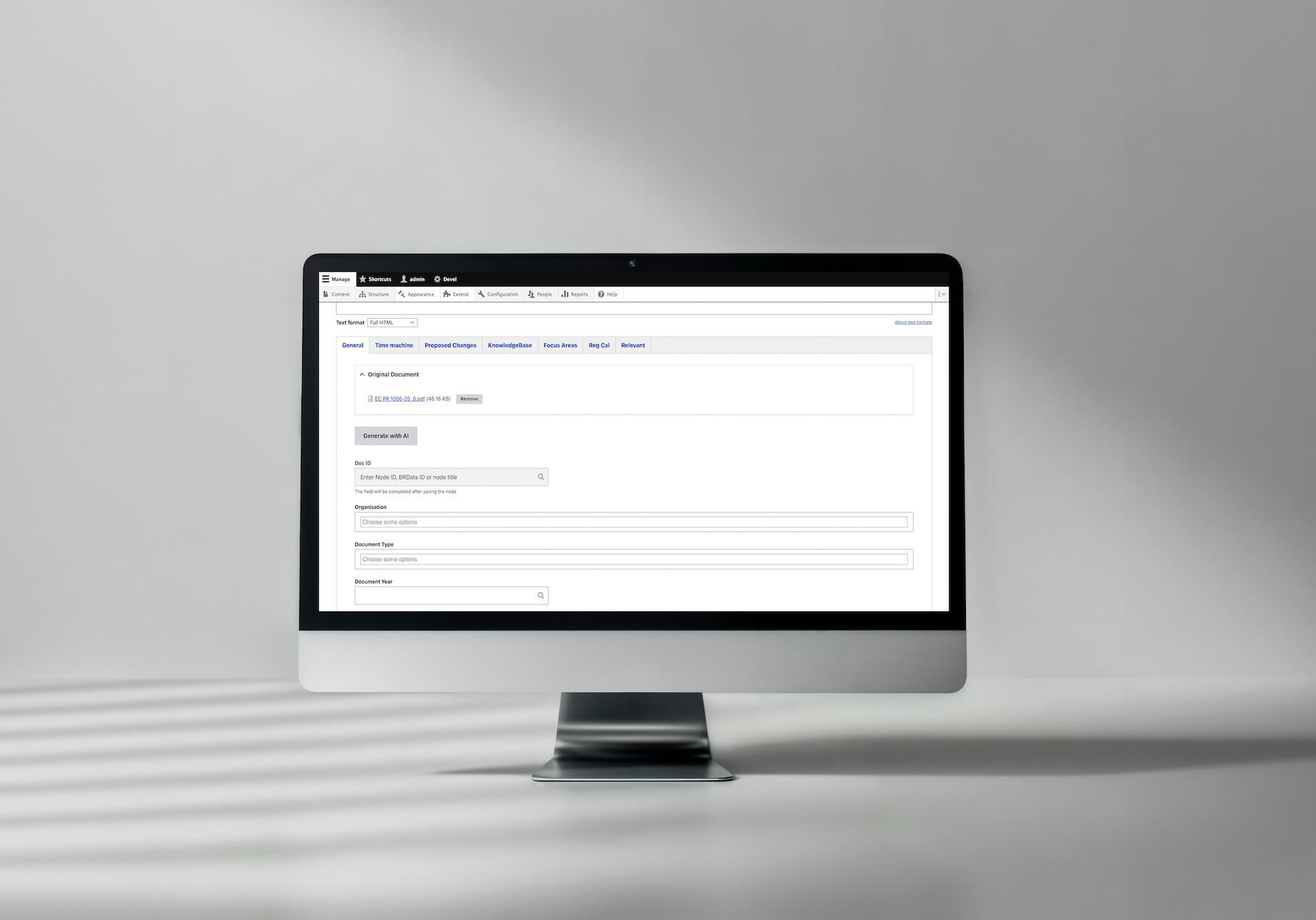
- PDF hochladen: Der Redakteur erstellt einen neuen Dokumenteintrag und lädt das PDF in das Feld "Originaldokument" hoch.
- Klicken Sie auf "Mit KI generieren": Ein einziger Klick startet die KI-Verarbeitung.
- Kurz warten: 10 Sekunden bis 2 Minuten, abhängig von der Dokumentengröße (kein Seitenrefresh erforderlich).
- Anpassungen vornehmen, falls erforderlich: Der Redakteur kann jedes Feld vor dem Speichern verändern.
- Speichern und veröffentlichen: Das Dokument ist bereit für die Plattform.
Die Transformation der Erfahrung:
- Zuvor: 15 Minuten bis mehrere Stunden Lese- und manueller Dateneingabeaufwand.
- Danach: Einen Knopf drücken, kurz warten, zur Überprüfung senden.
Die Redakteure behalten die Kontrolle. Sie können jedes automatisch ausgefüllte Feld vor dem Speichern ändern. Dies erhält Qualitätsstandards bei und beseitigt gleichzeitig die mühsame Arbeit.
Felder, die automatisch von KI ausgefüllt werden
Das System befüllt ungefähr 15 Felder, einschließlich:
Textfelder:
- Titel - extrahierter und bereinigter Dokumententitel.
- Inhalt/Zusammenfassung - Schlüsselinhaltsauszug aus dem Dokument.
Taxonomiebezüge:
- Dokumenttyp - Gesetz, Verordnung, Richtlinie, Code usw.
- Organisation - ausstellende Stelle oder Aufsichtsbehörde.
- Dokumentbereich - Themenklassifikation.
- Dokumentgesetzgebung - zugehöriger gesetzlicher Rahmen.
Entitätsbezüge:
- Zuständigkeitsbereich - UK, Irland, EU usw. (kann mehrfach sein).
Datumsfelder:
- Jahr - wann das Dokument erlassen oder veröffentlicht wurde.
URL-Felder:
- Quell-URL - offizieller Veröffentlichungsort.
Und zusätzliche Metadatenfelder, die spezifisch für das Inhaltsmodell von BetterRegulation sind
Die technische Innovation: intelligente Taxonomie-Mapping
Ein wichtiger technischer Erfolg ist die Handhabung von Drupals Taxonomie-Referenzen durch das System. Die KI extrahiert nicht nur Text; sie kartiert intelligent die extrahierten Informationen zu bestehenden Taxonomie-Begriffen in der Drupal-Datenbank.
So funktioniert es:
- Kontextinjektion: das System enthält die vollständige Liste der verfügbaren Taxonomie-Begriffe für jedes Feld im an die KI gesendeten Eingabeaufforderung
- Semantisches Matching: Die KI analysiert den Dokumenteninhalt und passt ihn auf der Grundlage der Bedeutung, nicht nur der Schlüsselwörter, an diese Begriffe an
- ID-Rückgabe: Es gibt nicht nur die passenden Begriffsnamen zurück, sondern auch ihre spezifischen Drupal-Entity-IDs
- Entity-Referenzerstellung: Das Drupal Automators Modul erstellt dann mit diesen IDs korrekte Entity-Referenzen
Diese Methode sichert:
- Nahtlose Integration mit der bestehenden Inhaltsarchitektur von BetterRegulation.
- Keine "verwaisten" Begriffe oder Dateninkonsistenzen.
- Angemessene Beziehungen zwischen Dokumenten und Taxonomien.
- Wartbare Datenstruktur, da sich die Taxonomien weiterentwickeln.
Technische Architektur
Die Lösung basiert auf einer robusten, produktionsreifen Architektur, die für Zuverlässigkeit und Skalierbarkeit konzipiert ist.
Technologie-Stack:
Drupal 11 - Plattform für Content-Management
Drupal Automatoren (Contrib Modul) - orchestriert die AI-Workflows und verwaltet die Verarbeitungslogik
Unstructured.io (Extracture) - PDF-Textextraktion und -Reinigung, selbst gehostet für die Kontrolle
GPT (OpenAI) - Sprachmodell für Textanalyse und -klassifizierung
RabbitMQ - Nachrichtenwarteschlange für Hintergrundverarbeitung (verwendet für die Zusammenfassungsfunktion)
Watchdog - umfassende Protokollierung und Fehlerüberwachung
Verarbeitungsablauf:
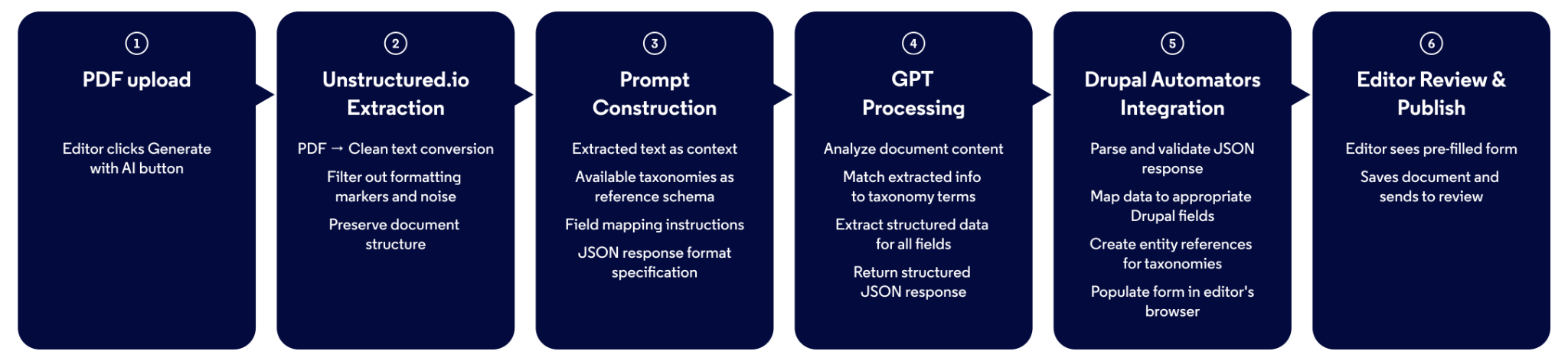
Schlüsseltechnische Entscheidungen
| Herausforderung | Lösung | Begründung |
|---|---|---|
| Komplexe PDF-Formatierung | Unstructured.io | Überlegenes Filtern von PDF-Artefakten, bessere Handhabung von Tabellen und Mehrspaltenlayouts, höhere Extraktionsgenauigkeit. |
| Modellauswahl | GPT | Optimales Gleichgewicht zwischen Geschwindigkeit/Genauigkeit/Kosten, großes Kontextfenster (128K Token) verarbeitet längste Dokumente. |
| Ausgabeformat | Strukturiertes JSON mit Schema | Sicherstellung konsistenter, analysierbarer Antworten; Validierung gegen erwartete Feldtypen. |
| Taxonomieabgleich | Vollständige Taxonomielisten im Eingabeaufforderung einbeziehen | AI kann semantisch statt nur durch exakte Schlüsselwörtern abgleichen; gibt korrekte Entität IDs zurück. |
| Benutzererfahrung | Synchrone on-demand Verarbeitung | Redakteure sehen sofortige Ergebnisse; können vor dem Speichern überprüfen; kein Warten auf Hintergrundjobs. |
| Große Dokumente | Anmutiges Herunterfahren | Dokumente, die Token-Grenzwerte überschreiten, werden zur manuellen Überprüfung mit klaren Fehlermeldungen gekennzeichnet. |
| Zuverlässigkeit | Umfassende Fehlerprotokollierung | Alle Fehler werden mit Kontext in Watchdog protokolliert; Admin-Dashboard zeigt Verarbeitungsstatus an. |
Behandlung von Randfällen
Die KI unterstützt, ersetzt aber nicht das menschliche Urteilsvermögen. Dieser mehrschichtige Ansatz stellt sicher, dass die hohen Standards von BetterRegulation eingehalten werden, während gleichzeitig erhebliche Effizienzvorteile erzielt werden.
Ergebnisse: transformative Effizienzgewinne
50% Zeitersparnis bei der Dokumentenverarbeitung
Das bedeutendste und sofort messbare Ergebnis ist die drastische Reduzierung der für die Dokumentenverarbeitung benötigten Zeit.
BetterRegulation erreicht eine Gesamtzeitersparnis von 50% für den gesamten Prozess der Dokumentenaufnahme, Kategorisierung, Überprüfung und Veröffentlichung.
1 FTE äquivalente Kapazität freigesetzt
Was früher ein ganzer Arbeitstag für einen Redakteur war, wird nun in einer Stunde erledigt. Die KI übernimmt den langweiligen Teil – das Lesen und Extrahieren von Informationen – während sich die Redakteure auf die Überprüfung und Qualitätskontrolle konzentrieren.
Dies entspricht etwa einer vollen Arbeitskraft (1 VZÄ) an redaktioneller Kapazität, die für höherwertige Arbeiten freigesetzt wurde.
Skalierbarkeit ohne Personalwachstum
Vielleicht am wichtigsten für das Geschäft von BetterRegulation ist, dass die KI-Lösung eine Skalierbarkeit bietet, die zuvor proportionalen Personalaufstockungen bedurft hätte.
Technische Innovation: Drupal + KI Erfolgsgeschichte
Dieses Projekt demonstriert die Leistungsfähigkeit des modernen Drupal für eine anspruchsvolle AI-Integration.