
Zuverlässige Umgebung unterstützt von AWS

Websites spielen eine zunehmend wichtige Rolle im Internet und können manchmal riesige Gewinne erzielen. Selbst die kleinsten Unterbrechungen in ihrem Betrieb können Verluste in Höhe von Hunderten oder sogar Tausenden von Dollar verursachen. Deshalb legen wir, wenn wir Drupal-Entwicklungsdienste durchführen, großen Wert darauf, dass unsere Arbeit so zuverlässig wie möglich ist. Wie? Dank Lösungen, die von Amazon Web Services angeboten werden und eine hohe Verfügbarkeit garantieren.
Was versteht man unter Hochverfügbarkeit?
Für diesen Artikel definieren wir Hochverfügbarkeit als eine Anforderung an eine Website bezüglich ihrer Betriebszeit, ausgedrückt als Prozentsatz der Betriebszeit in einem Monat. 100% Verfügbarkeit bedeutet, dass Nutzer die Website für 43.200 Minuten oder genau 30 Tage im Monat nutzen können.
Wenn aus irgendeinem Grund, sei es ein Update, ein Ausfall oder ein Angriff, die Website 12 Stunden lang nicht ordnungsgemäß funktioniert, liegt der Verfügbarkeitsparameter bei 98,3% (42.480 von 43.200 Minuten).
Welcher Verfügbarkeitsgrad ist erforderlich?
Es gibt keine klare Antwort auf diese Frage, da sie hauptsächlich von den Anforderungen des Kunden abhängt. Wenn der Kunde diesen Parameter nicht spezifiziert hat, müssen wir ihn selbst festlegen. In diesem Fall ist es sinnvoll, zwei einfache Fragen zu beantworten:
- Wie viel Zeit wird für Website-Updates benötigt (die die Abschaltung der Website für Nutzer erfordern)?
- Wie viel Zeit sollte für andere Aktivitäten aufgewendet werden, die die Abschaltung der Website erfordern?
Die Summe der beiden Antworten, erhöht um einen möglichen Sicherheitsbuffer, ermöglicht es, die gewünschte Verfügbarkeitszeit zu bestimmen. Bei Droptica beträgt dieser Parameter für unsere wichtigsten Websites 99,99%, was bedeutet, dass der Zugang zu den Diensten den ganzen Monat über nur für 4 Minuten unterbrochen ist!
Was zeichnet eine HA-Infrastruktur aus?
Im Standardansatz, der auf vielen Hosting-Plattformen verwendet wird, haben wir es mit einem einzelnen Server zu tun, auf dem alle Anwendungen, die zur Bereitstellung der Dienste erforderlich sind – wie HTTP-Server (apache2 oder nginx), MySQL, manchmal auch solr, redis, memcached und natürlich Festplattenspeicher – konfiguriert sind. Eine Darstellung einer solchen Lösung ist im Bild unten gezeigt.
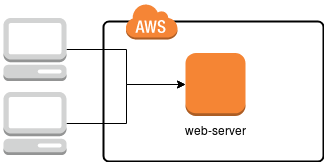
In diesem Fall reicht es aus, einen Server (oder eine der installierten Komponenten) zu beschädigen, um die darauf gewartete Website unzugänglich zu machen, wodurch die Verfügbarkeitszeit reduziert wird. Wie kann dies verhindert werden? Einfach die Infrastruktur so duplizieren, dass, wenn einer der Server ausfällt, ein anderer die Aufgabe übernimmt, wie im Diagramm unten gezeigt.
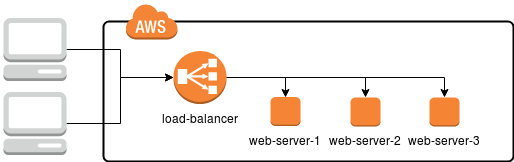
Dank dieses Ansatzes hat jeder Webserver dieselbe Funktionalität und bietet genau dieselben Dienste an. Zwischen dem Server und dem Nutzer befindet sich jedoch auch ein Load-Balancer, ein spezieller Server, der die Anfragen des Nutzers empfängt und sie an eine der drei Zielmaschinen weiterleitet.
Obwohl der Load-Balancer in unserem Diagramm wie ein einzelnes Element aussieht und als der verwundbarste Knoten und einzige Fehlerpunkt erscheinen mag, bietet Amazon in Wirklichkeit eine Reihe skalierbarer, effizienter und zuverlässiger Lösungen für Lastverteiler an:
Praktisches Beispiel
Bei Droptica haben wir das Muster entwickelt, das in den meisten Fällen mehr als ausreichend für die Bedürfnisse unserer Kunden ist. Eine Infrastruktur wie die auf dem Bild unten gewährleistet die Redundanz und hohe Verfügbarkeit bei minimalen Kosten.
Um das genannte Ergebnis zu erreichen, nutzen wir:
- EC2-Maschinen - die Basis der gesamten Umgebung, sie sind virtuelle Maschinen, auf denen die Dienste laufen,
- Application Load Balancer (ALB) - Lastverteiler, der dynamisch Anfragen zwischen EC2-Instanzen umleitet, Fehlfunktionen überprüft und die HTTPS-Verbindung unterstützt,
- Relational Database Service (RDS) - verteilter End-to-End-Datenbankdienst (MySQL),
- Elastic File System (EFS) - verteiltes Dateisystem, in dem die gemeinsamen Daten (z.B. Bilder, Filme und andere) gespeichert werden
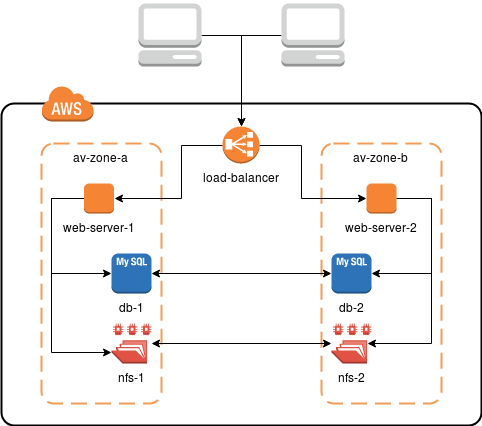
Im obigen Beispiel sind alle Komponenten der Infrastruktur in verschiedenen Verfügbarkeitszonen definiert. Physisch handelt es sich um zwei verschiedene Rechenzentren, die durch stabile und schnelle Verbindungen miteinander verbunden sind. Mit EFS und RDS müssen wir uns keine Sorgen über die Konfiguration und Synchronisierung der Daten machen. Wir verwenden sie einfach. Von RDS erhalten wir Daten an MySQL, während EFS wie ein gewöhnlicher NFS-Share eingebunden wird.
Probleme mit Hochverfügbarkeit
Die Implementierung von Hochverfügbarkeitssystemen bringt nicht nur viele Vorteile, sondern kann auch viele Probleme verursachen. Dies liegt daran, dass deutlich komplexere Strukturen in die Umgebung eingeführt werden müssen.
Einer der ersten Prozesse, die erheblich komplizierter werden, ist das Anwendungs-Deployment, das so angepasst werden muss, dass es mehrere Server unterstützt, um eine Situation zu vermeiden, in der die Anwendung ihre Datenbank auf einem Host aktualisiert, während der andere Inhalte an die Nutzer liefert.
Was die Unterschiede zwischen einzelnen Diensten betrifft, gibt es ein Problem mit Diensten, die auf Dateien arbeiten, wie Solr. Der Betrieb von drei unabhängigen Instanzen führt zu Situationen, in denen einige von ihnen mehr oder weniger aktuell sind als andere. Dies kann durch ein gemeinsames Dateisystem (NFS, EFS etc.), einen Solr-Cluster oder dedizierte Lösungen wie CloudSearch gelöst werden.
Auch das Durchsuchen von Logs wird erheblich schwieriger. Der Verkehr, der sich auf eine bestimmte Nutzersitzung bezieht, wird auf verschiedene Server umgeleitet, daher ist es eine gute Praxis, einen zentralen Anmeldepunkt basierend auf z.B. Logstash einzurichten.
Kosten sind ebenfalls ein wesentlicher Nachteil der Implementierung einer Hochverfügbarkeitsinfrastruktur. Die meisten Server und Dienste müssen parallel eingerichtet werden, mindestens verdoppelt und manchmal in größerer Anzahl. In der Realität können diese Server weniger effizient sein (schließlich wird der Verkehr proportional verteilt), aber insgesamt, wenn man auch die Kosten von Anwendungsclustern berücksichtigt, wird es teurer sein, viel teurer. Andererseits ist es jedoch eine Investition, die zu weniger Stress und der Gewissheit führt, dass wir im Falle eines Ausfalls weiterhin Inhalte an den Endnutzer liefern können.







