

Die Verarbeitung von KI-Dokumenten transformiert das Content-Management in Drupal. Durch die Integration von KI-Automatisierungswerkzeugen, Unstructured.io und GPT-Modellen können Redaktionsteams langweilige Aufgaben wie Metadatenextraktion, Übereinstimmung von Taxonomien und Zusammenfassungserzeugung automatisieren. Diese Fallstudie zeigt, wie BetterRegulation die Verarbeitung von KI-Dokumenten auf ihrer Drupal 11-Plattform implementiert hat und dabei eine Genauigkeit von über 95% und eine Zeitersparnis von 50% bei der redaktionellen Arbeit erreicht hat.
In diesem Artikel:
- Einführung: Warum KI-Dokumentenverarbeitung in Drupal verwenden?
- Projektkontext: Welches Problem löst die KI-Dokumentenverarbeitung?
- Wie funktioniert die KI-Dokumentenverarbeitung in Drupal?
- Wie implementiert man KI-Dokumentenverarbeitung in Drupal
- Was sind die wichtigsten technischen Herausforderungen bei der KI-Dokumentenverarbeitung?
- Wie stellt man die Produktionszuverlässigkeit für die KI-Dokumentenverarbeitung sicher?
- Performance- und Kostenoptimierung für die KI-Dokumentenverarbeitung
- Was haben wir aus der Implementierung der KI-Dokumentenverarbeitung gelernt?
- Welche Tools und Ressourcen benötigen Sie für die KI-Dokumentenverarbeitung?
- Bereit zur Implementierung der KI-Dokumentenverarbeitung in Drupal?
Einführung: Warum KI-Dokumentenverarbeitung in Drupal verwenden?
Drupal war schon immer ein Kraftpaket für das Content-Management, insbesondere für komplexe, strukturierte Inhalte. Aber wenn die Inhaltsvolumen wachsen und die Benutzererwartungen sich weiterentwickeln, wird die manuelle Dokumentenverarbeitung zum Engpass.
KI-Dokumentenverarbeitung automatisiert die Extraktion, Klassifizierung und Organisation von Informationen aus Dokumenten im großen Stil. KI mit Drupal macht dies für die Content-Management-Workflows möglich. Stellen Sie sich vor:
- Dokumente werden automatisch kategorisiert über 15 Metadatenfelder mit 95% Genauigkeit.
- Zusammenfassungen werden automatisch generiert für jeden Inhalt.
- Entitätsreferenzen werden intelligent erstellt basierend auf semantischem Verständnis.
- Redaktionsteams werden von langweiliger Dateneingabe befreit, um sich auf die Strategie zu konzentrieren.
Dies ist keine Zukunftsvision, sondern Realität. BetterRegulation, eine auf Drupal 11 laufende Plattform für die Einhaltung von Rechtsvorschriften, hat ihrem bestehenden System KI-Fähigkeiten hinzugefügt und verarbeitet nun mehr als 200 komplexe Rechtsdokumente pro Monat und erreicht:
- 50% Zeiteinsparung bei der Dokumentenverarbeitung
- 1 FTE freigesetzt für höherwertige Arbeit
- >95% Genauigkeit bei der automatischen Kategorisierung
- <12 Monate Amortisationszeit
Dieser Artikel teilt die technische Architektur, entscheidende Entscheidungen und Lehren aus einer realen Implementierung, die mehr als 200 Rechtsdokumente pro Monat verarbeitet.
Wichtige Erkenntnisse, die Sie gewinnen werden:
- Architekturentscheidungen für die automatisierte Dokumentenverarbeitung: Warum KI-Automatisierungswerkzeuge, Unstructured.io und GPT-4o-mini.
- Wie man eine Genauigkeit von über 95% bei der automatisierten Taxonomieabstimmung erreicht.
- Realistische Strategien zur Kostensenkung (Einsparungen von über £2.000/Jahr).
- Produktionsschwierigkeiten und Lösungen (15-minütige Verzögerungsmechanismen, Token-Grenzen).
- Wann man KI-Automatisierungswerkzeuge gegenüber benutzerdefiniertem Code für die Dokumentenautomatisierung einsetzt.
Für wen ist dies gedacht: Technische Teamleiter und Entwickler, die eine Integration der KI-Dokumentenverarbeitung für bestehende Drupal-Plattformen evaluieren.
Projektkontext: Welches Problem löst die KI-Dokumentenverarbeitung?
BetterRegulation hatte bereits eine reife Drupal 11 Plattform, die tausende von juristischen Dokumenten verwaltet. Die Herausforderung bestand darin, die Fähigkeiten der KI-Dokumentenverarbeitung in ihren bestehenden Workflow zu integrieren, ohne die Redakteure zu stören oder einen kompletten Neubau zu erfordern.
Das Ziel war einfach, aber ehrgeizig: Dokumentenverarbeitung mit KI automatisieren um PDFs zu lesen, Metadaten zu extrahieren, Taxonomien abzugleichen und Zusammenfassungen zu erstellen - während sich die Redakteure auf Qualitätskontrolle und strategische Inhaltskuration konzentrieren.
Zwei Hauptfunktionen wurden entwickelt:
1. Automatisches Ausfüllen von Dokumentenfeldern (Inhaltstyp Know How) - Laden Sie ein PDF hoch, klicken Sie auf "Mit KI generieren" und beobachten Sie, wie sich 15+ Felder automatisch mit Dokumententyp, Organisation, Jahr, Gesetzesreferenzen und mehr füllen. Die Verarbeitung erfolgt in Echtzeit (1-2 Minuten), sodass die Redakteure die ausgefüllten Felder sofort überprüfen und anpassen können.
2. KI-Generierte Zusammenfassungen (Allgemeine Beratung, Station, Know How Inhaltsarten) - Erstellen Sie automatisch drei Arten von Zusammenfassungen:
- Detaillierte Zusammenfassung (~200 Wörter) - umfassender Überblick.
- Kurzzusammenfassung (~50 Wörter) - ein Absatz Zusammenfassung.
- Verpflichtungszusammenfassung - extrahierte rechtliche Verpflichtungen und regulatorische Anforderungen.
Zusammenfassungserzeugung läuft im Hintergrund mit einer 15-minütigen Verzögerung, um Neubearbeitungen bei schnellen Bearbeitungen zu vermeiden.
Die Implementierung musste sein:
- Nicht störend: Arbeiten innerhalb der bestehenden Inhaltsarten und Workflows.
- Konfigurierbar: Ermöglicht Eingabeaufforderungen und Taxonomieaktualisierungen ohne Codebereitstellung.
- Zuverlässig: Kann Randfälle wie 350-seitige Dokumente und komplexe juristische Terminologie bewältigen.
- Kosteneffektiv: verarbeitet monatlich mehr als 200 Dokumente, ohne das Budget zu sprengen.
Dieser Leitfaden zeigt, wie wir all dies mit dem KI-Modul-Ökosystem von Drupal erreicht haben.
Wie funktioniert die KI-Dokumentenverarbeitung in Drupal?
Das Verständnis des technischen Stacks ist entscheidend für die Evaluierung dieses Ansatzes für Ihre eigenen Projekte. Die Implementierung der KI-Dokumentenverarbeitung von BetterRegulation kombiniert fünf Kernkomponenten, die zusammenarbeiten, um Dokumente von der PDF-Hochladung bis zu den ausgefüllten Inhaltsfeldern zu verarbeiten.
Welcher Technologie-Stack ermöglicht die KI-Dokumentenverarbeitung?
Die KI-Implementierung von BetterRegulation verwendet fünf Schlüsselkomponenten:
1. Automatisches Ausfüllen von Dokumentenfeldern (Schaltfläche "Mit KI generieren")
┌──────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Erstellung von Inhalten │ │
│ │ [ PDF hochladen ] [ Mit KI erstellen Button ] │ │
│ └───────────┬───────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ KI Automatisierungswerkzeuge │ │
│ │ (Workflow-Engine) │ │
│ │ + Batch API │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Unstructured.io │ │
│ │ (PDF→sauberer Text) │ │
│ │ Selbst gehosteter Pod │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (KI-Verarbeitung) │ │
│ │ OpenAI API │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ JSON Antwort (ausgefüllte Felder) │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ KI Automatisierungswerkzeuge │ │
│ │ (parse & populate) │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Felder ausgefüllt │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Erstellung von Inhalten │ │
│ │ [ Automatisch ausgefüllte Felder, bereit zur Überprüfung ] │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (protokollierung) │ │
│ └───────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘
2. KI-generierte Zusammenfassungen (Hintergrundverarbeitung)
┌─────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ │
│ Speichern von Dokumenten │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ RabbitMQ queue │ │
│ │ (15-minütige Verzögerung) │ │
│ └───────┬──────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ KI Automatisierungswerkzeuge │ │
│ │ (Workflow-Engine) │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (Zusammenfassung generieren) │ │
│ │ OpenAI API │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Generierte Zusammenfassungen │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ KI Automatisierungswerkzeuge │ │
│ │ (zu Feldern speichern) │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Dokument aktualisiert │ │
│ │ [ Zusammenfassungen in Inhaltsfeldern gespeichert ] │ │
│ └───────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (protokollierung) │ │
│ └───────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘
Was macht jede Komponente in der KI-Dokumentenverarbeitung?
Drupal 11 dient als Grundlage für das gesamte System und bietet die Plattform für das Content-Management, die Entitätsstruktur und die Benutzeroberfläche. Es koordiniert den Workflow und speichert alle Dokumentendaten, es agiert als zentrale Stelle, an der Redakteure mit Inhalten interagieren und wo letztendlich die von der KI verarbeiteten Ergebnisse leben.
Drupal KI-Automatisierungswerkzeuge ist das Modul, das Drupal und KI-Dienste verbindet. Statt benutzerdefinierten Integrationscode zu erstellen, bietet dieses Modul einen konfigurationsbasierten Ansatz zur Definition von KI-Workflows. Es verwaltet Eingabeaufforderungen, behandelt Antworten von mehreren KI-Anbietern (OpenAI, Anthropic usw.) und organisiert mehrstufige Prozesse über eine intuitive Admin-Oberfläche. Das bedeutet, dass das Erstellen und Modifizieren von KI-Workflows eine Konfigurationsaufgabe und kein Entwicklungsprojekt wird. Weitere Beispiele für KI-Automatisierung in Drupal finden Sie in So generieren Sie alternative Texte und Content-Strategien mit KI-Modulen.
Unstructured.io wird auf einem selbst gehosteten Pod ausgeführt und kümmert sich um den kritischen ersten Schritt: die Umwandlung von unübersichtlichen PDF-Dokumenten in sauberen, strukturierten Text. Es analysiert Layouts von Dokumenten, erhält Strukturen bei, filtert Artefakte wie Kopf- und Fußzeilen und Seitenzahlen heraus und kann sogar OCR für gescannte Dokumente handhaben. Das Ergebnis ist ein sauberer Text, der für die KI-Verarbeitung optimiert ist, was für eine genaue Kategorisierung und Metadatenextraktion wesentlich ist.
GPT-4o-mini unterstützt die KI-Analyse über die API von OpenAI. Sobald es sauberen Text von Unstructured.io erhält, führt es eine Dokumentanalyse durch, gleicht den Inhalt mit der BetterRegulation-Taxonomie ab, extrahiert Metadaten und erstellt Zusammenfassungen. Das Modell gibt strukturierte JSON-Antworten zurück, die Drupal Automators analysieren und automatisch in die entsprechenden Inhaltsfelder einfügen können.
RabbitMQ verwaltet die Hintergrundverarbeitung von Aufgaben, insbesondere für die zeitaufwändige Erstellung von Zusammenfassungen. Wenn ein Benutzer ein Dokument speichert oder bearbeitet, wird die Erstellung der Zusammenfassung automatisch mit einer Verzögerung von 15 Minuten in die Warteschlange gestellt. Diese Designentscheidung entstand aus einer praktischen Notwendigkeit heraus: Redakteure nehmen oft mehrere schnelle Änderungen an Dokumenten vor, und die Verarbeitung von Zusammenfassungen nach jedem Speichern würde API-Kosten und Verarbeitungszeit verschwenden. Die 15-minütige Verzögerung ermöglicht es den Redakteuren, ihre Änderungen abzuschließen, bevor die KI-Verarbeitung beginnt. Dies verhindert redundante Verarbeitungsprozesse und ermöglicht es dem System, horizontal zu skalieren, indem mehrere Zusammenfassungen von verschiedenen Mitarbeitern verarbeitet werden.
Watchdog, das zentrale Protokollierungssystem von Drupal, erfasst jeden Schritt des Prozesses. Vom PDF-Upload bis zur KI-Antwort werden alle Aktionen, Fehler und Leistungskennzahlen protokolliert. Diese umfassende Protokollierung erwies sich während der Entwicklung als unverzichtbar für die Fehlerbehebung in Workflows und ist auch weiterhin wertvoll für die Überwachung des Systemzustands in der Produktion.
Warum wurde dieser Technologie-Stack für die KI-Dokumentenverarbeitung gewählt?
BetterRegulation hatte bereits Drupal 11 als Content-Management-Plattform, als das Unternehmen beschloss, KI-Funktionen hinzuzufügen. Die Herausforderung bestand darin, KI in den bestehenden Workflow zu integrieren, ohne die Arbeit der Redakteure zu stören oder größere architektonische Änderungen vornehmen zu müssen.
Die Entscheidung für KI-Automatisierer anstelle von benutzerdefiniertem Code sparte Wochen an Entwicklungszeit. Anstatt Standard-Integrationscode für die API von OpenAI zu schreiben, Prompt-Vorlagen zu verwalten und Admin-Schnittstellen zu erstellen, konfigurierten wir die Workflows über eine GUI. Dieser Ansatz, bei dem die Konfiguration Vorrang vor dem Code hat, bedeutet, dass zukünftige Änderungen – wie das Hinzufügen neuer KI-Schritte oder der Wechsel des Anbieters – ohne die Bereitstellung neuen Codes vorgenommen werden können. Das Modul wird von der Community gepflegt, sodass Verbesserungen und Sicherheitsupdates aus dem breiteren Drupal-Ökosystem stammen.
Bei der PDF-Verarbeitung erwies sich Unstructured.io in jeder aussagekräftigen Metrik als überlegen gegenüber der direkten Extraktion. Erste Tests mit Standard-PDF-Bibliotheken ergaben eine Extraktionsqualität von 75 % und erzeugten Text voller Seitenzahlen, Kopfzeilen und Formatierungsartefakten. Unstructured.io erreichte eine Qualität von 94 % und erzeugte sauberen Text, der 30 % an KI-Tokens einsparte. Durch das Selbsthosting des Dienstes auf der vorhandenen Infrastruktur entfielen die Bearbeitungsgebühren pro Dokument, sodass der Einsatz selbst bei Tausenden von Dokumenten wirtschaftlich rentabel war.
Die Entscheidung für GPT-4o-mini anstelle von GPT-4 fiel aus wirtschaftlichen Gründen und aufgrund der ausreichenden Leistungsfähigkeit. GPT-4 ist zwar leistungsfähiger, aber GPT-4o-mini erwies sich als völlig ausreichend für die Taxonomieabgleichung und Metadatenextraktion. Mit 10-mal geringeren Kosten und einem 128K-Kontextfenster (ausreichend für Dokumente mit 350 Seiten) bot es die perfekte Balance zwischen Leistungsfähigkeit und Erschwinglichkeit. Die schnellere Verarbeitungsgeschwindigkeit war ein Bonus, der das Editor-Erlebnis verbesserte.
Eine detaillierte Vergleich der verschiedenen Ansätze zur KI-Integration finden Sie unter LangChain vs. LangGraph vs. Raw OpenAI: Wie Sie Ihren RAG-Stack auswählen.
Implementierung der KI-Dokumentenverarbeitung in Drupal
Nachdem die Architektur festgelegt ist, wollen wir uns nun ansehen, wie diese Komponenten tatsächlich aufgebaut und konfiguriert wurden. Bei der Implementierung lag der Schwerpunkt darauf, vorhandene Drupal-Module zu nutzen, anstatt einen benutzerdefinierten Code von Grund auf neu zu erstellen.
Der Ansatz
Anstatt einen benutzerdefinierten KI-Integrationscode von Grund auf neu zu erstellen, haben wir das KI-Automators-Modul von Drupal genutzt – einen konfigurationsbasierten Ansatz, der uns wochenlange Entwicklungszeit erspart und sofortige Zuverlässigkeit auf Unternehmensniveau bietet.
Entwickelte Kernkomponenten
1. Dienst zur PDF-Textextraktion
Wir haben einen benutzerdefinierten Drupal-Dienst erstellt, der PDFs an die selbst gehostete Unstructured.io-Instanz sendet und sauberen, strukturierten Text zurückerhält. Der Dienst filtert Kopf- und Fußzeilen sowie Seitenzahlen heraus und behält die Dokumentstruktur bei, was für eine genaue KI-Analyse entscheidend ist.
Wichtige Implementierungsentscheidung: Filtern Sie nur die Elemente Title, NarrativeTextund ListItem aus der Antwort von Unstructured.io. Dadurch werden Störsignale entfernt, während die logische Struktur des Dokuments erhalten bleibt.
2. Konfiguration des Automator-Workflows
Über die Admin-Oberfläche von AI Automators (/admin/config/ai/automator_chain_types/manage/summary/automator_chain) haben wir einen zweistufigen Workflow konfiguriert:
- Schritt 1: Text aus PDF extrahieren → in temporärem Feld speichern
- Schritt 2: Text + Taxonomien an GPT-4o-mini senden → JSON-Antwort empfangen
Für die Integration der KI-API ist kein benutzerdefinierter Code erforderlich – AI Automators übernimmt die Anbieterverwaltung, die Wiederholungslogik und die Fehlerbehandlung.
3. Prompt Engineering für die Taxonomie-Zuordnung
Das Geheimnis einer Genauigkeit von über 95 %: Vollständige Taxonomielisten direkt in den Prompt einfügen.
Die Prompt-Struktur sieht folgendermaßen aus:
Sie analysieren ein rechtliches Dokument. Extrahieren und kategorisieren Sie mit diesen Taxonomien:
### Dokumenttyp-Taxonomie:
- Gesetz (ID: 12)
- Verordnung (ID: 13)
- Hinweis (ID: 14)
[... komplette Liste mit IDs ...]
### Organisations-Taxonomie:
- Finanzmarktaufsichtsbehörde (ID: 23)
- Bank von England (ID: 24)
[... komplette Liste mit IDs ...]
[Dokumententext hier]
Return JSON:
{
"document_type": ["Gesetz", "Verordnung"],
"organisation": ["Finanzmarktaufsichtsbehörde"],
"document_area": ["Datenschutz", "Finanzdienstleistungen", "DSGVO"],
...
}Wichtige Entscheidungen:
- Dynamisches Laden der Taxonomie: Der PHP-Code fragt die Drupal-Taxonomien ab und erstellt den Eingabeaufforderungskontext spontan. Änderungen an Taxonomien erfordern keine Aktualisierung der Eingabeaufforderung.
- KI gibt Taxonomienamen zurück: Die KI gibt Taxonomiebegriffnamen (z. B.
[„Datenschutz“, ‚Finanzdienstleistungen‘, „DSGVO“]) zurück, keine IDs. Das System führt dann eine Suche durch, um diese Namen mit den Begriff-IDs im Taxonomiesystem von Drupal abzugleichen. Dieser Ansatz nutzt das semantische Verständnis der KI und behält gleichzeitig präzise Entitätsreferenzen bei. - Zuordnung von Namen zu IDs: Nachdem die KI Begriffsnamen zurückgibt, durchsucht das System das Taxonomie-Vokabular nach übereinstimmenden Begriffen und ruft deren IDs ab. Beispiel:
„Datenschutz“→ findet die Begriff-ID42,„Finanzdienstleistungen“→ findet die Begriff-ID87,„DSGVO“→ findet die Begriff-ID156. Dem Dokument wird dann das Array der IDs zugewiesen:[42, 87, 156]. - Semantische Zuordnung: Die KI versteht „Verbraucherkredite“ = „Verbraucherkreditgeber“, auch ohne dass die Schlüsselwörter exakt übereinstimmen. Der namensbasierte Ansatz ermöglicht es der KI, ihr semantisches Verständnis zur Zuordnung von Konzepten zu nutzen, während das System durch die exakte Zuordnung von Begriffsnamen in der Taxonomie-Suche für Genauigkeit sorgt.
Token-Kosten: Durch das Hinzufügen von Taxonomien erhöht sich die Prompt-Größe um ~5.000 Token pro Anfrage, was zusätzliche Kosten von 0,03 £ pro Dokument verursacht. Die Verbesserung der Genauigkeit (75 % → 95 %) spart mehr als 12 Minuten manueller Korrekturarbeit pro Dokument, was einem 70-fachen ROI entspricht.
4. „Mit KI generieren”-Button
Wir haben einen AJAX-fähigen Button zum Inhaltsbearbeitungsformular hinzugefügt, der den Verarbeitungsworkflow auslöst und die Felder in Echtzeit füllt. Der Editor sieht, wie sich die Formularfelder automatisch füllen und kann sie überprüfen/anpassen, bevor er sie speichert.
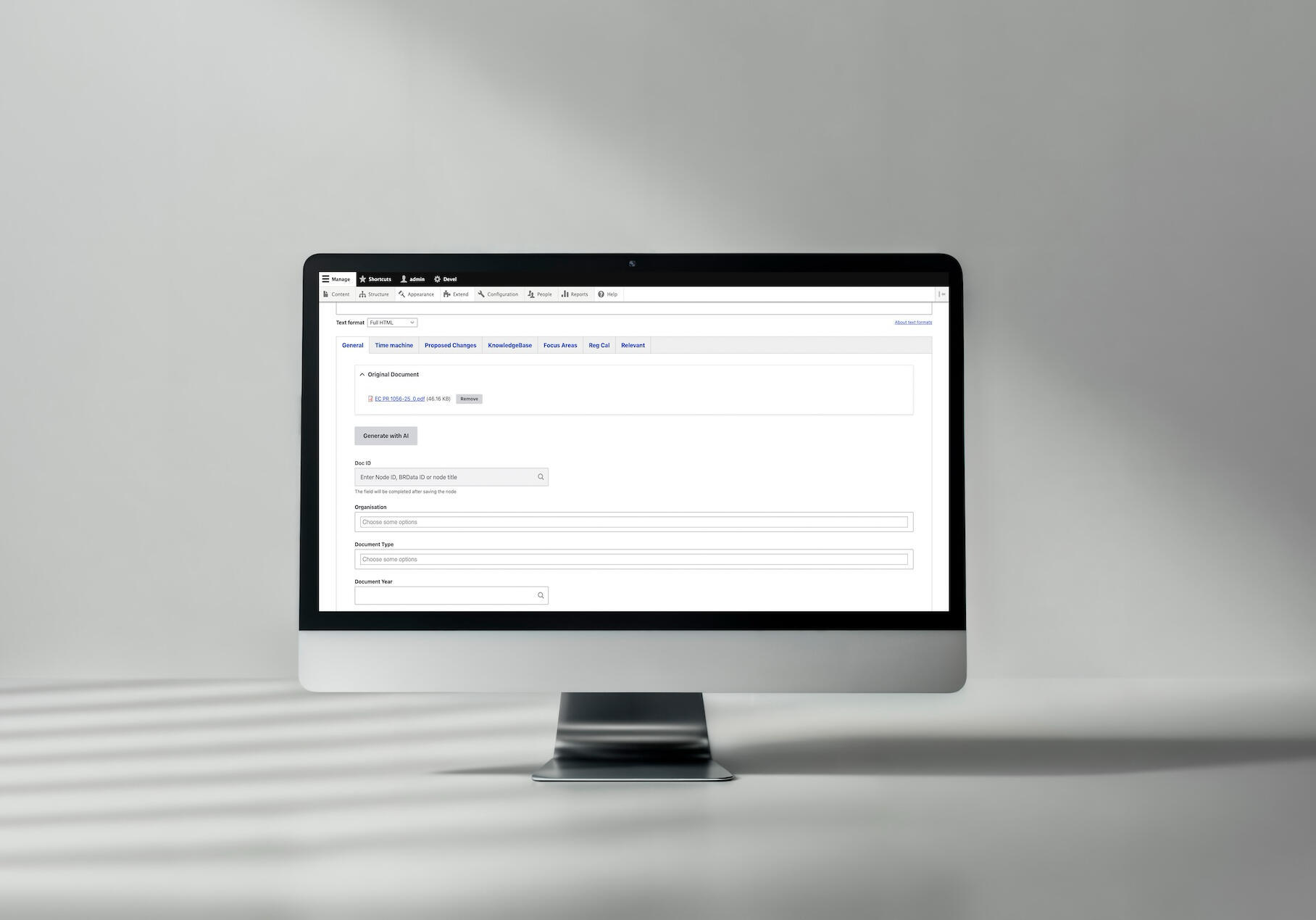
Ein Beispiel für die von uns für Better Regulation implementierte KI-Dokumentenverarbeitung
Lesen Sie hier die vollständige Fallstudie zur KI-gesteuerten Dokumentenkategorisierung →
Was sind die wichtigsten technischen Herausforderungen bei der AI-Dokumentenverarbeitung?
Jede AI-Integration stößt auf einzigartige Herausforderungen. Hier sind die drei wesentlichen technischen Hürden, auf die BetterRegulation stieß und wie sie diese gelöst haben.
Herausforderung 1: Automatisierte PDF-Extraktion für die Dokumentenverarbeitung
Rechtliche Dokumente sind notorisch unübersichtlich:
- Mehrspaltige Layouts
- Kopf-/Fußzeilen auf jeder Seite
- Seitenzahlen mitten im Satz eingebettet
- Tabellen und Fußnoten
Unsere Lösung:Unstructured.io’s hi_res strategie mit Elementfilterung für saubere Dokumentenverarbeitung.
Ergebnisse:
- 94% Extraktionsqualität (im Vergleich zu 75% mit Standard-PDF-Bibliotheken)
- 30% Token-Einsparungen durch das Filtern von Artefakten
- Sauberer, strukturierter Text, den KI genau analysieren kann
Wichtige Implementierung: Nur Title, NarrativeText und ListItem Elemente einbeziehen. Kopf- und Fußzeilen sowie Seitenzahlen ignorieren.
Herausforderung 2: Tokenlimit bei großen Dokumenten
Einige Dokumente sind über 350 Seiten lang und überschreiten das 128K-Kontextfenster von GPT-4o-mini.
Unsere Lösung: Strategie zur eleganten Degradation.
- Schätzung der Token vor dem Senden berechnen (1 Token ≈ 4 Zeichen)
- Wenn >120K Token: extrahiere nur Titel und Abschnittsüberschriften
- Füge ein Admin-Feld für manuell kondensierte PDFs für Randfälle hinzu
Kompromiss: etwas geringere Genauigkeit bei Riesen-Dokumenten (90% vs. 95%), aber Vermeidung eines vollständigen Versagens.
Herausforderung 3: Semantisches Taxonomie-Matching
Das Problem: Das Dokument verwendet den Ausdruck "Verbraucherkreditpraktiken". Der Taxonomiebegriff lautet "Verbraucherkreditgeber und -verleiher". Traditionelles Keyword-Matching versagt.
Unsere Lösung: nutze das semantische Verständnis von LLM.
- KI versteht "Verbraucherkredit" = "Verbraucherkredit"
- Erkennt Akronyme (FCA = Financial Conduct Authority)
- Verwendet Kontext zur Desambiguierung (ICO = Datenregulator, nicht Kryptowährung)
Warum das namenbasierte Matching funktioniert: KI gibt Termini wie["Verbraucherkredit", "Datenschutz"] zurück, die das System dann über die Taxonomieabfrage in Term-IDs (z.B. [35, 42]) umwandelt. Dieser Ansatz kombiniert das semantische Verständnis der KI mit genauen Entitätsreferenzen - die KI kann Begriffe semantisch abgleichen, während das System die Genauigkeit sicherstellt, indem es genaue Term-Matches im Taxonomie-Wortschatz findet.
Lesen Sie auch: Wie wir die Genauigkeit des RAG-Chatbots durch Dokumentbewertung um 40% verbessert haben →
Wie stellt man die Produktionszuverlässigkeit für die AI-Dokumentenverarbeitung sicher?
Der Übergang vom Proof-of-Concept zur Produktion erfordert robuste Fehlerbehandlung und Monitoring. BetterRegulation hat umfangreiche Schutzmaßnahmen errichtet, um sicherzustellen, dass das System unter realen Bedingungen stabil bleibt.
Wie geht man mit Fehlern in der AI-Dokumentenverarbeitung um?
Umfassendes Logging: Jeder Schritt wird im Watchdog-System von Drupal protokolliert - vom PDF-Upload bis zur AI-Antwort. Unverzichtbar für Debugging und Monitoring.
Rückversuchslogik: Vorübergehende API-Ausfälle (Ratenbegrenzungen, Timeouts) lösen automatische, exponentiell abklingende Wiederholungsversuche aus (2s, 4s, 8s Verzögerungen).
Elegante Fehlerbehandlung: Wenn die Verarbeitung fehlschlägt, bleibt das Dokument bearbeitbar mit klaren Fehlermeldungen. Redakteure können erneut versuchen oder die Felder manuell ausfüllen.
Monitoring-Dashboard
Benutzerdefinierte Admin-Ansicht unter/admin/content/ai-processing verfolgt:
- Erfolgs-/Fehlerquoten
- Verarbeitungszeiten
- API-Kosten
- Häufigkeit der Redakteurskorrekturen (Genauigkeitsmetrik)
Wöchentliche Überprüfung: Das Team von BetterRegulation überprüft das Dashboard wöchentlich, um Probleme frühzeitig zu erkennen und Aufforderungen auf Basis von Fehlermustern zu verfeinern.
Leistungs- und Kostenoptimierung für die KI-Dokumentenverarbeitung
Die Kosten für AI-APIs können ohne eine ordnungsgemäße Optimierung schnell außer Kontrolle geraten. BetterRegulation hat mehrere Strategien zur Minimierung der Kosten für die Dokumentenverarbeitung implementiert, ohne dabei Leistung und Benutzererfahrung einzuschränken.
Hintergrundverarbeitung mit 15-minütiger Verzögerung
Das Problem: Redakteure speichern Dokumente oft mehrmals in kurzen Abständen während der Bearbeitung. Die Auslösung einer kostspieligen KI-gestützten Zusammenfassung bei jedem Speichern ist eine Verschwendung von Geld.
Unsere Lösung: Queuing der Zusammenfassungserstellung an RabbitMQ mit 15-minütiger Verzögerung.
- Redakteur speichert Dokument → Warteschlange für die Verarbeitung in 15 Minuten
- Wenn der Redakteur innerhalb von 15 Minuten erneut speichert → Verzögerung neu einstellen
- Nach 15 Minuten ohne Änderungen → Zusammenfassungen werden einmal generiert
Auswirkung: Eliminiert 60-70% überflüssiger API-Aufrufe bei schnellen Bearbeitungssitzungen. Weitere Strategien zur Reduzierung der KI-API-Kosten finden Sie unter wie intelligente Routing KI-API-Kosten um 95% reduziert.
Wie reduziert Caching die Kosten für die AI-Dokumentenverarbeitung?
Extrahierter PDF-Text wird für 7 Tage zwischengespeichert. Wenn eine Aufforderung verfeinert werden muss, zum Beispiel durch Abstraction, wird der zwischengespeicherte Text statt einer erneuten Extraktion aus dem PDF verwendet.
Einsparungen: ca. 0,05 £ pro erneutem Prozess (Unstructured.io-Aufruf entfällt).
Lesen Sie auch: Wie man die Reaktionszeit von AI-Chatbots mit intelligentem Caching beschleunigt →
Was sind die Kosten der AI-Dokumentenverarbeitung?
Monatliche Verarbeitung (200 Dokumente):
- GPT-4o-mini API: ca. 42 £/Monat (ca. 0,21 £ pro Dokument)
- Unstructured.io: 0 £ (selbst gehostet)
- Gesamt: 42 £/Monat
Einsparungen durch Optimierung im Vergleich zu GPT-4:
- GPT-4 würde Kosten verursachen: ca. 420 £/Monat
- Einsparungen: 378 £/Monat (90% Reduktion)
Kosten pro gesparter Stunde:
- 50% Zeiteinsparung = 50 Stunden/Monat gespart
- 42 £/Monat ÷ 50 Stunden = 0,84 £ pro gesparter Stunde
- Typische Redakteurskosten: 15-25 £/Stunde
- ROI: 18-30-fache Rendite
Welche Sicherheitsaspekte sollten bei der AI-Dokumentenverarbeitung berücksichtigt werden?
Datenschutz: PDFs werden an die OpenAI-API gesendet. Bei sensiblen Dokumenten sollte man in Betracht ziehen:
- Self-hosted LLMs (Llama, Mistral via Ollama)
- Datenverarbeitungsvereinbarungen mit OpenAI
- Textanonymisierung (PII vor dem Senden entfernen)
API-Key-Sicherheit: wird im Konfigurationssystem von Drupal gespeichert, nicht im Code. Nur Administratoren haben Zugang.
Was haben wir aus der Implementierung der AI Dokumentenverarbeitung gelernt?
Nach monatelanger Entwicklung und Produktion hat das Team von BetterRegulation sieben entscheidende Lektionen identifiziert, die jedem nützen würden, der ähnliche KI-Integrationen baut. Diese Erkenntnisse gehen über technische Dokumentation hinaus und erfassen hart erarbeitetes praktisches Wissen.
1. Testen Sie mit echten Dokumenten
Nicht: mit Beispiel-/synthetischen PDFs testen.
Doch: verwenden Sie tatsächliche Dokumente aus Ihrem Bereich.
Warum: synthetisch Testdokumente sind sauber, gut formatiert und vorhersehbar. Dokumente aus der realen Welt sind unsauber, inkonsistent und voller Randfälle, die Ihre sorgfältig gestalteten Aufforderungen brechen werden.
Was BetterRegulation während des realen Tests entdeckte:
- Gescannte PDFs mit schlechter OCR: PDFs hatten verstümmelten Text wie "Cong umer Cred it Act", der die Taxonomieabgleichung verwirrte. Lösung: Hinzufügen der Textnormalisierung, um OCR-Artefakte zu bewältigen.
- Mehrsprachige Dokumente: EU-Vorschriften, die englische und lateinische Rechtstermini mischen. Die KI scheiterte zunächst daran, diese korrekt einzuordnen, bis die Aufforderungen angepasst wurden, um gemischtsprachige Inhalte zu behandeln.
- Inkonsistente Benennung: dieselbe Organisation wurde als "FCA", "Financial Conduct Authority", "die Behörde" und "die FCA" innerhalb eines Dokuments bezeichnet. Semantisches Abgleichen bewältigte dies, aber eine Überprüfung war erforderlich.
- 350+ Seiten Monster: stießen auf das Token-Limit-Problem beim Testen mit tatsächlichen Regulierungssammlungen. Führte zur Ausweichstrategie der Titelgewinnung.
BetterRegulation testete mit echten juristischen PDFs, die mehr als 5 Jahre Publikationen abdecken, vor dem Start. Die ersten 20 Testdokumente offenbarten mehr Probleme als 6 Monate Entwicklung mit synthetischen Beispielen.
2. Der Mensch in der Schleife ist wesentlich
Nicht: vollständig automatisieren ohne Überprüfung.
Doch: KI besiedelt, Menschen prüfen und genehmigen.
Warum: kein KI-System ist perfekt und Fehler in einer Compliance-Plattform haben echte Konsequenzen. Noch wichtiger ist, dass KI-Fehler nicht zufällig sind - sie neigen dazu, sich um die komplexesten, mehrdeutigsten oder ungewöhnlichsten Dokumente zu häufen, die die größte Aufmerksamkeit erfordern.
Der menschengesteuerte Ansatz bietet mehrere Vorteile:
- Qualitätssicherung: Juristische Redakteure entdecken KI-Fehler, bevor sie sich auf Endnutzer auswirken. In einer Compliance-Plattform könnte eine falsche Kategorisierung bedeuten, dass wichtige regulatorische Anleitung nicht gefunden wird, wenn sie benötigt wird.
- Vertrauensbildung: Redakteure vertrauen dem System, weil sie sehen, wie es funktioniert und es korrigieren können. Die Positionierung der KI als "Assistent" statt als Ersatz verringert den Widerstand in der Organisation und erhöht die Akzeptanz.
- Kontinuierliche Verbesserung: Korrekturen der Redakteure offenbaren Muster im KI-Verhalten. Durch die Verfolgung, welche Felder am häufigsten korrigiert werden, können Sie identifizieren, wo Aufforderungen verfeinert oder wo Taxonomien klarer definiert werden müssen.
- Erfassung von Fachwissen: Wenn Redakteure Korrekturen vornehmen, wenden sie oft nuanciertes Fachwissen an, das in den ursprünglichen Aufforderungen nicht erfasst wurde. Diese Korrekturen können analysiert werden, um das System im Laufe der Zeit zu verbessern.
- Ausgewogene Effizienz: KI übernimmt die mühsame, wiederholende Arbeit des Lesens von Dokumenten und des Extrahierens grundlegender Metadaten. Menschen konzentrieren sich auf die Überprüfung, die Anpassung von Randfällen und das Anwenden von Urteilsvermögen in mehrdeutigen Situationen. Diese Arbeitsteilung ist effizienter als jeder Ansatz allein.
Das Ergebnis: erhebliche Zeiteinsparungen bei gleichbleibend hohen Qualitätsstandards. Redakteure arbeiten schneller, weil die KI die erste Arbeit erledigt, und das Endprodukt ist konsistenter, weil die KI nicht müde wird oder Übertragungsfehler macht.
3. Wiederholen Sie die Aufforderungen
Nicht: schreiben Sie die Aufforderung einmal und fahren Sie fort.
Doch: Überprüfen Sie Fehler und verfeinern Sie Aufforderungen.
Warum: Ihre erste Aufforderung wird gut, aber nicht großartig sein. Das Verhalten der KI ist aufkommend und oft überraschend - Sie werden nicht alle Ausfallmuster vorhersagen können, bis Sie Hunderte von echten Dokumenten verarbeitet haben.
Die Lektion: Verbesserung kam durch die Analyse tatsächlicher Fehler, nicht durch Theorien über Verbesserungen. Verfolgen Sie Korrekturen, finden Sie Muster, verfeinern Sie Aufforderungen.
4. Randfälle sind unvermeidlich
Nicht: davon ausgehen, dass die KI alles handhaben wird.
Doch: Planen Sie Randfälle im Voraus und bauen Sie gnädige Ausweichmöglichkeiten ein.
Warum: Egal wie gut Ihre KI ist, einige Dokumente werden das System sprengen. Die Frage ist nicht "ob", sondern "wann" und "wie oft".
Katalog der Randfälle von BetterRegulation:
- Token-Limit-Überschreitungen: sehr große Regulierungskompendien, die das 128K-Kontextfenster von GPT-4o-mini überschreiten. Ausweichlösung: Nur Titel und Abschnittsüberschriften extrahieren und verarbeiten - geringere Genauigkeit, aber besser als komplettes Versagen.
- Gescannte PDF-Desaster: ältere Gesetzgebung, die mit schlechter OCR gescannt und verstümmelten Text produzierte. Ausweichlösung: Admin-Feld zum Hochladen einer manuell getippten zusammengefassten Version oder Markierung für menschliche Verarbeitung.
- Wirklich mehrdeutige Dokumente: Einige Dokumente erstrecken sich tatsächlich über mehrere Kategorien und sogar Rechtsexperten sind sich über die richtige Kategorisierung uneinig. Ausweichlösung: KI gibt mehrere Optionen zurück; Redakteur trifft die endgültige Entscheidung.
- Fehlende Metadaten: Einige PDFs enthalten einfach nicht die erwarteten Informationen wie Jahr, Quell-URL oder andere Felder. Ausweichlösung: Leere Werte zurückgeben anstatt zu halluzinieren; Redakteur füllt manuell aus.
Der pragmatische Ansatz: Akzeptieren Sie, dass einige Dokumente eine besondere Behandlung benötigen. Bauen Sie eine Überwachung auf, um diese Fälle schnell zu identifizieren und den Redakteuren klare Workflows für deren Bearbeitung zu bieten. Der Versuch, 100% Automatisierung zu erreichen, würde erheblich mehr Entwicklungszeit für marginale Gewinne kosten.
5. Überwachung ist entscheidend
Nicht: implementieren und vergessen.
Doch: Erstellen Sie von Anfang an eine umfassende Überwachung.
Warum: KI-Systeme können still degradieren. Modellaktualisierungen, Änderungen der Taxonomie oder sich entwickelnde Dokumentenformate können zuvor funktionierende Prozesse brechen. Ohne Überwachung werden Sie es nicht bemerken, bis sich Benutzer beschweren.
Der Überwachungsansatz von BetterRegulation verfolgt:
- Erfolgs-/Fehlerraten: allgemeine Erfolgsmetriken der Verarbeitung. Plötzliche Rückgänge deuten auf Systemprobleme hin.
- Verteilung der Verarbeitungszeit: Verfolgen Sie die Leistung im Laufe der Zeit. Deutliche Erhöhungen weisen auf Verzögerungen bei der API oder Probleme mit dem Token-Limit hin.
- Genauigkeit pro Feld: Überwachen Sie, welche Felder die Redakteure am häufigsten korrigieren. Zeigt, wo Aufforderungen verbessert werden müssen.
- Trends in den API-Kosten: Verfolgen Sie die Ausgabenmuster. Spitzen weisen auf Probleme wie doppelte Verarbeitung, fehlgeschlagene Verzögerungslogik oder unerwartete Mengenerhöhungen hin.
- Fehlermuster: Kategorisieren Sie Fehler nach Art. Jedes Muster erhält spezifische Wiedergutmachungsstrategien.
Wert der Früherkennung: Die Überwachung bietet eine Frühwarnung, wenn externe Dienste ihr Verhalten ändern oder wenn sich die Muster der Dokumentenverarbeitung verschieben, so dass eine schnelle Anpassung möglich ist, bevor die Benutzer betroffen sind.
6. Kostenoptimierung ist wichtig
Nicht: Standardmäßig das teuerste KI-Modell verwenden.
Doch: Testen Sie zuerst billigere Modelle; optimieren Sie basierend auf den tatsächlichen Kosten.
Warum: "Nutzen Sie die beste KI" klingt clever, verschwendet aber Geld. Für viele Aufgaben sind günstigere Modelle genauso gut. Die Kostenoptimierungsreise von BetterRegulation brachte im Vergleich zur naiven Herangehensweise, Premium-Modelle für alles zu verwenden, erhebliche Einsparungen.
Entscheidung 1: GPT-4o-mini vs GPT-4
- Anfängliche Annahme: "GPT-4 ist besser, also verwenden Sie GPT-4."
- Realitätsprüfung: Beide Modelle wurden an 50 Dokumenten getestet. GPT-4: 96% Genauigkeit. GPT-4o-mini: 95% Genauigkeit.
- Kostenanalyse: GPT-4: £1.05/Dokument. GPT-4o-mini: £0.21/Dokument.
- Entscheidung: 1% Genauigkeitsgewinn ist keine 5-fache Kostensteigerung wert. Wählte GPT-4o-mini.
- Jährliche Einsparungen: £2,016 (200 Dokumente/Monat × 12 Monate × £0.84 Einsparungen pro Dokument)
Entscheidung 2: Selbst gehostetes Unstructured.io
- SaaS-Option: £0.10-0.20 pro Dokumentenverarbeitung
- Selbst gehostete Option: Betrieb auf bestehendem Kubernetes-Cluster, effektiv kostenlos (geringe Rechnerkosten ~£5/Monat)
- Entscheidung: Selbst hosten auf vorhandener Infrastruktur
- Jährliche Einsparungen: £240-480 (200 Dokumente/Monat × 12 Monate × £0.10-0.20)
7. Einfach anfangen, Komplexität hinzufügen
Nicht: Versuchen Sie, die komplette Vision am ersten Tag zu bauen.
Doch: Starten Sie mit der minimal lebensfähigen KI, iterieren Sie basierend auf der tatsächlichen Nutzung.
Warum: Sie wissen nicht, was funktionieren wird, bis echte Benutzer mit echten Daten interagieren. Wenn Sie komplex beginnen, bedeutet das längere Entwicklung, mehr Fehler und verschwendeten Aufwand für Funktionen, die die Benutzer vielleicht nicht benötigen.
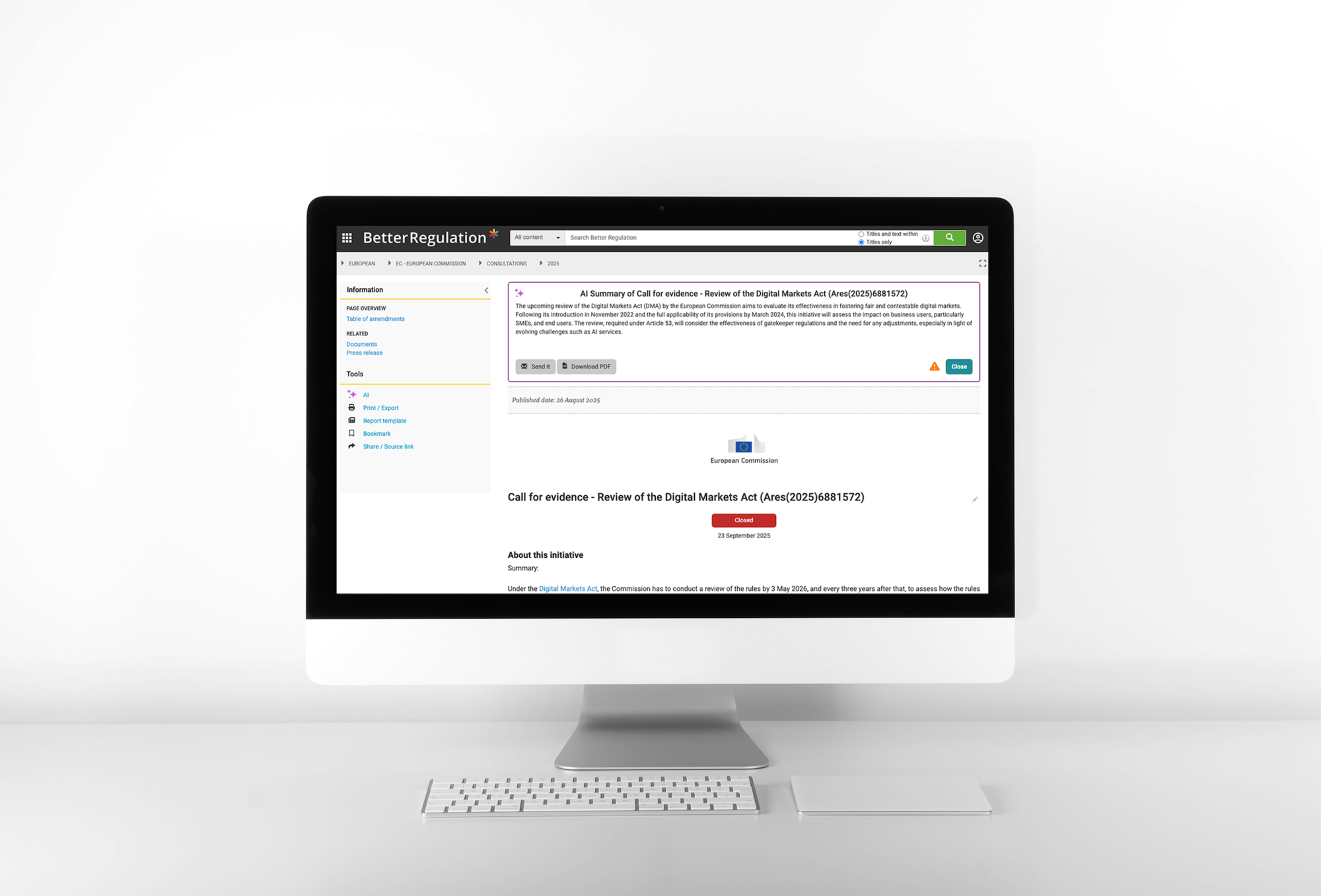
Ein Beispiel für ein Projekt, in dem wir KI und Drupal verwendet haben, um automatisierte Zusammenfassungen für komplexe rechtliche Dokumente zu implementieren
Lesen Sie hier die vollständige Fallstudie zu KI-gesteuerten Dokumentenzusammenfassungen →
Welche Tools und Ressourcen benötigen Sie für die AI Dokumentenverarbeitung?
Sind Sie bereit, die AI Dokumentenverarbeitung in Ihrem Drupal-Projekt zu implementieren? Hier sind die essentiellen Module, Dienste und Ressourcen, die Sie benötigen, um zu starten.
Drupal Module
Erforderlich:
- KI-Modul - Kern-KI-Integrationsframework für Drupal
- KI-Automatisierer - Untermodul, das einen Workflow-Motor für mehrstufige KI-Prozesse bereitstellt
Hilfreich:
- Warteschlangen-Benutzeroberfläche - Verwaltung von Hintergrundwarteschlangen
- Unstrukturiertes Modul - Drupal-Integration für Unstructured.io
Externe Dienste
KI-APIs:
- OpenAI API - GPT Modelle (empfohlen: GPT-4o-mini)
- Anthropic Claude - alternativer LLM-Anbieter
PDF-Verarbeitung:
- Unstructured.io - beste PDF-Extraktion (selbst gehostet oder SaaS)
- Unstructured GitHub - open source
Infrastruktur
Docker/Kubernetes:
- Docker Compose - lokale Entwicklung
- Kubernetes - Produktionseinsatz
Nachrichtenwarteschlangen:
- RabbitMQ - zuverlässige Nachrichtenwarteschlange
- Drupal Queue API - eingebaute Warteschlangen
Sind Sie bereit, die KI-Dokumentenverarbeitung in Drupal zu implementieren?
Diese Fallstudie basiert auf unserer realen Produktionsimplementierung für BetterRegulation, bei der wir AI Automators, Unstructured.io und GPT-4o-mini integriert haben, um die Dokumentenverarbeitung für monatlich über 200 juristische Dokumente mit einer Genauigkeit von über 95% und einer Zeitersparnis von 50% zu automatisieren. Das System läuft seit Monaten in der Produktion und liefert konstante Ergebnisse und einen ROI.
Interessiert daran, die KI-Dokumentenverarbeitung für Ihre Drupal-Seite zu erstellen? Unser Team ist spezialisiert auf die Erstellung von KI-Dokumentenverarbeitungslösungen für den Produktionsbetrieb, die Genauigkeit, Leistung und Wirtschaftlichkeit in Einklang bringen. Wir kümmern uns um alles, von der Architekturplanung und der Aufforderungsingenieurwesen bis hin zur Bereitstellung und Optimierung. Besuchen Sie unsere Services für die generative AI-Entwicklung, um zu erfahren, wie wir Ihnen helfen können, die Dokumentenverarbeitung zu automatisieren und Ihr Redaktionsteam dazu zu bringen, sich auf strategische Arbeit zu konzentrieren.










