
How We Improved RAG Chatbot Accuracy by 40% with Document Grading

Your AI chatbot may respond quickly, but are its answers correct? Many organizations implementing RAG (Retrieval-Augmented Generation) chatbots discover a frustrating truth: semantic similarity doesn't equal relevance. For example, a user may ask about "implementing zero-trust security architecture in hybrid cloud environments," and the system confidently returns articles about "cloud security," but they discuss basic firewall rules instead of zero-trust principles.
We faced this exact challenge while building a RAG chatbot for a professional knowledge management platform. Their extensive library of articles, case studies, and technical documentation required precision – users needed accurate answers with contextual information, not just semantically similar content. Through implementing a two-stage document grading approach, we dramatically improved answer accuracy while maintaining reasonable performance and costs.
In this article, I'll walk you through the problem with naive RAG retrieval, explain our two-stage grading solution, share real implementation details, and help you decide when this approach makes sense for your chatbot.
In this article:
- The problem with naive RAG retrieval
- Two-stage document grading solution
- How to implement document grading? Code examples
- How does document grading affect chatbot performance?
- What are the results and business impact of document grading?
- When document grading makes sense
- Getting started with document grading
- Higher RAG accuracy with document grading
- Want to build production-grade RAG Chatbots?
The problem with naive RAG retrieval
Most RAG systems follow a straightforward pattern: convert user questions into embeddings, search a vector database for similar document chunks, and feed the top-K results to an LLM (ang. Large Language Model) to generate responses. This works remarkably well for many use cases, but it has a fundamental limitation: vector similarity measures how close words and concepts are in semantic space, not whether a document actually answers a specific question.
How standard vector search works
When you perform a vector search, the system calculates the cosine similarity (or another distance metric) between your query embedding and document embeddings stored in the vector databases. Documents with the highest similarity scores rise to the top. For example a query about "GDPR compliance requirements for API data processing in third-party integrations." could return:
- General articles about GDPR compliance (high keyword overlap),
- API documentation guides (semantically similar),
- Case studies about data privacy (mentioned "compliance"),
- Glossary entries defining GDPR terms (keyword matches).
All these documents contain relevant keywords and concepts. The embeddings recognize semantic relationships. But do they actually answer the user's specific question about compliance requirements? Not necessarily.
The cost of poor accuracy
When RAG-based chatbots return plausible but wrong answers, the consequences compound:
- Eroded trust: users quickly learn the system "doesn't really understand" their questions.
- Increased support burden: instead of reducing repetitive questions, you add "How do I get better answers?" to the support queue.
- Wasted implementation investment: a system that users avoid delivers no ROI.
- Reputation damage: in professional knowledge platforms, accuracy directly impacts brand credibility and user retention.
We needed a solution that could distinguish between "these documents contain similar words" and "these documents actually answer this question."
Two-stage document grading solution
Our solution implements a two-stage retrieval process that separates broad discovery from precise selection. Instead of blindly accepting the top-K results from vector search, we introduce an LLM-powered grading step that evaluates each candidate for actual relevance.
Stage 1: Broad retrieval
The first stage casts a wide net, retrieving approximately 20 candidate document chunks from our Elasticsearch vector database. Why 20? This number balances two competing needs:
- Recall: we need enough candidates to ensure relevant documents make it into consideration. If we only retrieve 5 chunks and the truly perfect answer is #6, we'll never find it.
- Processing efficiency: grading documents consumes LLM tokens and adds latency. Evaluating 100 candidates would be unnecessarily expensive.
At this stage, we're still using standard vector similarity search. The query gets embedded using OpenAI's text-embedding-3-small model, and we perform a cosine similarity search with Maximal Marginal Relevance (MMR) to reduce redundancy in the initial results.
Each retrieved chunk includes rich metadata we captured during indexing:
{
"node_id": "12345",
"title": "Zero-Trust Architecture Implementation Guide",
"url": "/articles/zero-trust-security",
"tags": ["Security", "Cloud", "Architecture"],
"authors": ["Jane Doe"],
"channels": ["Enterprise Security"],
"published_at": "2024-03-15",
"type": "article",
"subtype": "technical_guide",
"section_title": "Network Segmentation Strategies",
"chunk_index": 3,
"tokens": 450,
"language": "en"
}
This metadata becomes crucial in the next stage.
Stage 2: LLM-powered grading
Here's where the magic happens. We take those 20 candidate chunks and ask GPT-4o a deceptively simple question for each one: "Does this text actually answer the user's question?"
The grading prompt includes:
- The original user input (a question with full context)
- The candidate chunk text
- The chunk metadata (helps LLM understand context)
- Clear grading criteria:
- Does it directly address the question topic?
- Does it provide substantive information (not just definitions)?
- Is the context appropriate for the query?
- Is it sufficiently complete to be useful?
The Large Language Model returns a relevance grade (we use a scale, but binary yes/no works too). Crucially, the LLM can recognize that an article about "general cloud security" might score high on semantic meaning similarity but low on relevance for a "zero-trust architecture" query.
After grading all 20 candidates, we sort by relevance score and select the top 12 for final answer generation. Why 12? Through testing, we found this number provided enough context for comprehensive answers without overwhelming the generation context window or diluting quality with marginally relevant content.
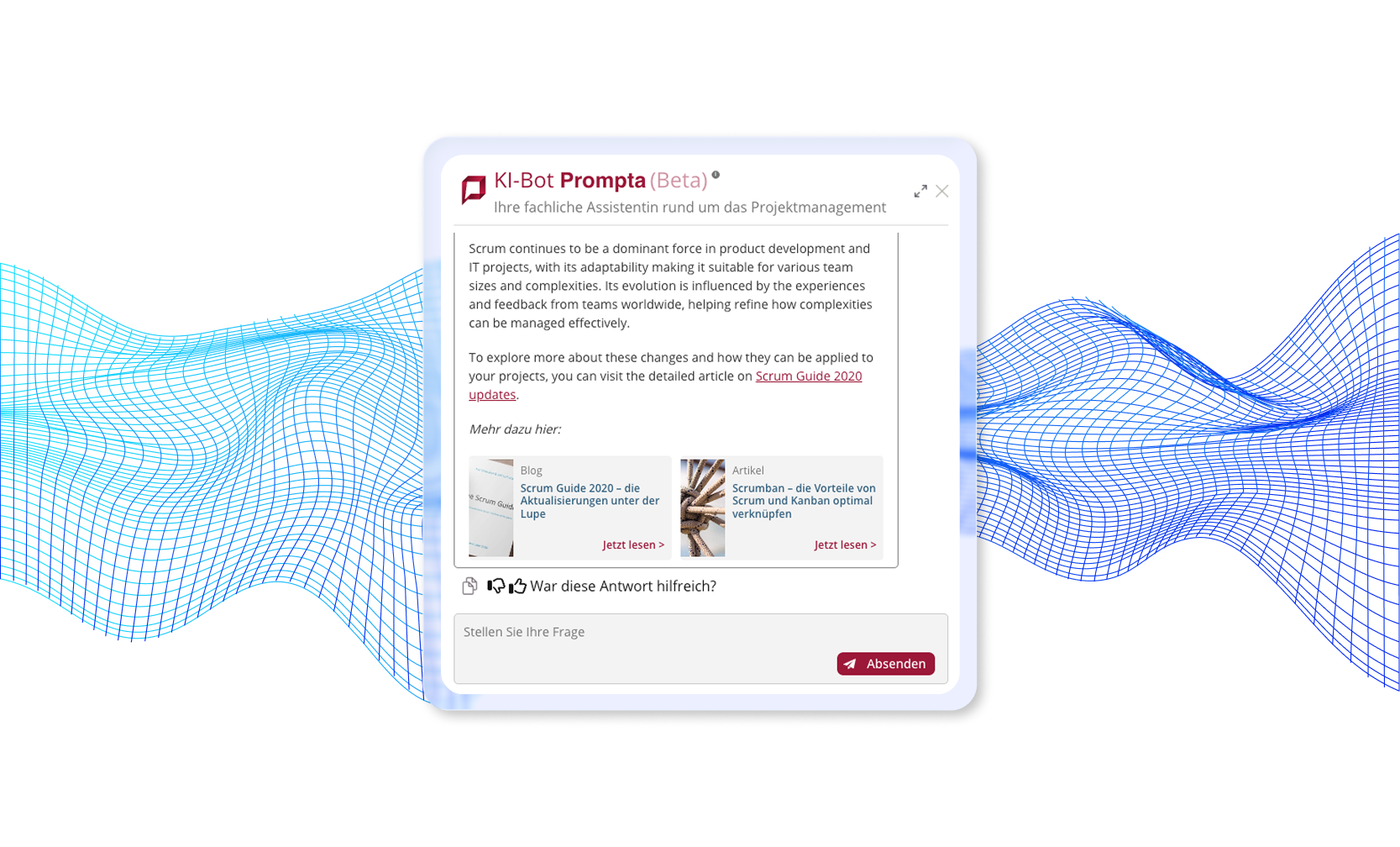
Example of a chatbot we implemented that uses two-stage document grading
Read our full case study: AI Document Chatbot →
Why does a two-stage document grading work?
The two-stage approach exploits the complementary strengths of embeddings and LLMs:
- Embeddings excel at broad semantic search across thousands of documents in milliseconds.
- LLMs excel at nuanced understanding of context, intent, and relevance.
By combining them, we get the speed and scalability of vector search with the precision of language understanding. The LLM can make subtle distinctions that embeddings miss:
- "This discusses security architecture, but for on-premise deployments, not cloud environments".
- "This defines the concept but doesn't provide implementation details".
- "This is about the same technology but for a different use case".
- "This mentions the keyword but it's a tangential reference, not the main topic".
How to implement document grading? Code examples
Let's look at how to implement document grading in practice. While our production system uses LangChain and LangGraph for orchestration, the core concepts apply to any RAG framework.
Conceptual implementation
Here's a simplified version of the grading logic:
from langchain.vectorstores import ElasticsearchStore
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Configuration
BROAD_RETRIEVAL_K = 20 # Candidates to retrieve
FINAL_SELECTION_K = 12 # Chunks to use for generation
# Initialize components
vector_store = ElasticsearchStore(
index_name="embeddings_index_v2",
embedding=OpenAIEmbeddings(model="text-embedding-3-small")
)
grading_llm = ChatOpenAI(model="gpt-4o", temperature=0)
def retrieve_and_grade(query: str) -> list[Document]:
"""
Two-stage retrieval with document grading
"""
# Stage 1: Broad retrieval
candidates = vector_store.similarity_search(
query=query,
k=BROAD_RETRIEVAL_K,
search_type="mmr" # Reduce redundancy
)
print(f"Retrieved {len(candidates)} candidates")
# Stage 2: Grade each candidate
graded_docs = []
for doc in candidates:
grade = grade_document(query, doc)
graded_docs.append({
"document": doc,
"relevance_score": grade["score"],
"reasoning": grade["reasoning"]
})
# Sort by relevance score
graded_docs.sort(key=lambda x: x["relevance_score"], reverse=True)
# Select top K for generation
final_docs = [item["document"] for item in graded_docs[:FINAL_SELECTION_K]]
print(f"Selected {len(final_docs)} highly relevant documents")
return final_docs
def grade_document(query: str, document: Document) -> dict:
"""
Evaluate document relevance using LLM
"""
grading_prompt = ChatPromptTemplate.from_messages([
("system", """You are an expert at evaluating document relevance.
Given a user question and a document chunk, determine if the document
actually answers the question. Consider:
1. Topic match: Does it address the specific topic asked about?
2. Context appropriateness: Is it relevant to the user's situation?
3. Completeness: Does it provide substantive information?
4. Directness: Does it directly answer, or just mention keywords?
Respond with:
- score: 0.0 to 1.0 (1.0 = highly relevant)
- reasoning: Brief explanation of your assessment
"""),
("human", """Question: {query}
Document content:
{content}
Document metadata:
- Title: {title}
- Type: {doc_type}
- Tags: {tags}
Evaluate this document's relevance.""")
])
response = grading_llm(grading_prompt.format_messages(
query=query,
content=document.page_content,
title=document.metadata.get("title", "N/A"),
doc_type=document.metadata.get("type", "N/A"),
tags=", ".join(document.metadata.get("tags", []))
))
# Parse LLM response (implement structured output in production)
return {
"score": parse_score(response),
"reasoning": parse_reasoning(response)
}
Integration with LangGraph
In our production system, grading fits into a LangGraph state machine:
from langgraph.graph import Graph, StateGraph
# Define workflow
workflow = StateGraph()
# Nodes in the workflow
workflow.add_node("classify_question", classify_question)
workflow.add_node("generate_search_phrase", generate_search_phrase)
workflow.add_node("retrieve", retrieve_documents) # Retrieves ~20
workflow.add_node("grade_documents", grade_all_documents) # Grades and selects top 12
workflow.add_node("generate", generate_answer)
# Edges define the flow
workflow.add_edge("classify_question", "generate_search_phrase")
workflow.add_edge("generate_search_phrase", "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
# Compile and run
app = workflow.compile()
result = app.invoke({"query": user_question})
The grade_documents node receives the candidate list from retrieve and outputs the filtered, ranked selection for generate.
How does document grading affect chatbot performance?
Implementing document grading in your chatbot introduces performance trade-offs, but with smart optimization strategies, you can minimize the impact while maximizing accuracy gains.
Understanding the latency trade-off
Adding document grading to your RAG pipeline introduces additional processing time. In our production deployment, grading 20 document candidates adds approximately 2-5 seconds to the total query response time. This happens because each document requires an individual LLM call to evaluate its relevance.
However, this latency can be significantly reduced through parallel processing. Instead of grading documents sequentially, you can evaluate multiple candidates simultaneously using async operations or threading. In practice, we found that users of knowledge base systems readily accept this wait time when it results in dramatically better answer quality. The few extra seconds feel worthwhile when the alternative is receiving irrelevant information that requires reformulating the query and trying again.
Read also: How to Speed Up AI Chatbot Responses with Intelligent Caching →
Breaking down the document grading cost economics
Understanding the economics of document grading helps you make informed decisions about implementation. Each grading operation consumes approximately 150-300 tokens, depending on the document length and metadata included in the grading prompt. With 20 candidates to grade per user query, that's roughly 5,000 tokens per query (using an average of 250 tokens per grade).
Optimization strategies for production
Several optimization strategies can help you balance cost, speed, and quality.
Cache frequent evaluations
Caching grades for common question-document pairs eliminates redundant evaluations. If you retrieve data for the same question-document combination frequently, store the grade and reuse it. This can dramatically reduce costs for high-traffic knowledge bases with recurring queries.
Use a smaller or faster model
You might also consider using a smaller or faster model for grading operations. While we used GPT-4o for maximum accuracy, GPT-3.5-turbo or a specialized fine-tuned model could handle grading at a fraction of the cost, especially if your domain is well-defined.
Reduce the number of candidates
Another approach is reducing the number of candidates you grade. If the budget is tight, grade only the top 10 documents instead of 20, accepting slightly reduced recall for lower costs.
Implement early termination
Finally, implement early termination logic: if the first five documents all score very high for relevance, you might skip grading the remaining fifteen candidates. This intelligent short-circuiting saves tokens while still maintaining quality for queries with obvious high-quality matches.
What are the results and business impact of document grading?
Implementing document grading transformed answer quality in our production RAG system. While we use "40%" in the article title as an illustrative figure, the qualitative improvements were dramatic and measurable through user feedback and system metrics.
Accuracy improvements
Document grading transformed our chatbot's answer quality in ways that people immediately noticed and appreciated.
Before grading:
- Users frequently reported answers that were "close but not quite right".
- Common complaint: "It talks about the topic but doesn't answer my specific question".
- Support tickets included "How do I get better answers from the chatbot?"
After grading:
- User feedback shifted to "This is exactly what I was looking for."
- Support tickets dropped for RAG chatbot usage questions.
- System satisfaction scores improved significantly.
- Users began to trust and rely on the chatbot for daily work.
Real-world validation
Post-deployment feedback validated our approach:
- Stakeholder satisfaction: leadership reported the system exceeded expectations for functionality and reliability.
- Operational success: next priorities shifted to UI enhancements rather than core functionality fixes – a clear signal that answer quality met needs.
- User adoption: active user count steadily increased as trust in the system grew.
- Reduced escalations: technical support could focus on actual user issues rather than system accuracy problems.
When document grading makes sense
Document grading isn't necessary for every RAG chatbot. When should you consider it?
Ideal use cases
Here are some examples of the ideal use cases:
- Large, diverse knowledge bases (1,000+ documents): when your corpus is extensive and covers many topics, naive retrieval struggles to distinguish nuance. Grading becomes increasingly valuable as the knowledge base grows.
- Technical or specialized domains: medical information, legal documents, technical documentation, enterprise architecture patterns, and text files – domains where precision matters and wrong information has real consequences.
- Professional or enterprise users: specialists making business decisions need confidence in answers. Whether it's architects choosing technology stacks, compliance officers interpreting regulations, or developers implementing security patterns – getting it wrong could impact critical business operations.
- Quality over speed prioritization: if users prefer waiting 5 seconds for a great answer from the chat messages over getting a mediocre answer in 2 seconds, grading makes sense.
- High-stakes questions: customer support, compliance guidance, medical advice, financial information – scenarios where accuracy isn't negotiable.
When simpler retrieval might suffice
See cases where it’s worth opting for simpler retrieval:
- Small document collections (<100 documents): with fewer documents, naive retrieval often performs well enough. The precision gains don't justify the complexity.
- General knowledge queries: for broad, non-technical questions, semantic similarity usually correlates well with relevance. A simple FAQ RAG chatbot might not need grading.
- Strict latency requirements: real-time chat or voice applications where every millisecond matters might need to skip grading or use very fast approximations.
- Budget constraints: if per-query costs must stay under $0.01 total, grading might push you over budget. Consider it when scaling or when sponsorship exists.
- Experimental or prototype systems: get basic RAG working first, add grading if naive retrieval proves insufficient. Don't prematurely optimize.
Getting started with document grading
Ready to implement document grading in your RAG chatbot? Here's a practical roadmap:
Step 1: Measure current performance
Before adding grading, establish baselines:
- Manually review 50-100 query-answer pairs.
- Note where answers are off-target despite semantic similarity.
- Calculate rough relevance score (how many answers actually addressed the question).
- Make a note of document common failure patterns.
This baseline proves whether grading helps and by how much.
Step 2: Start with simple grading
Don't overcomplicate initially:
# Simple binary grading prompt
prompt = """Does this document answer the question: {query}?
Document: {content}
Answer only: YES or NO"""
# Retrieve candidates
candidates = vectorstore.similarity_search(query, k=20)
# Grade each
relevant = []
for doc in candidates:
response = llm(prompt.format(query=query, content=doc.content))
if "YES" in response:
relevant.append(doc)
# Use relevant documents for generation
answer = generate(query, relevant[:12])
Step 3: Iterate and improve
Enhance grading based on results:
- Add structured output: use JSON-mode or function calling for consistent responses.
- Include metadata: help the LLM understand document context.
- Tune selection threshold: maybe you need top 15, not top 12.
- Optimize for speed: parallel grading, faster models for some queries.
- Monitor costs: track grading spend vs. quality gains.
Step 4: Run A/B tests
Run grading alongside naive retrieval:
- Route 50% of queries through each path.
- Compare user feedback, engagement, satisfaction.
- Measure cost differences.
- Decide based on data, not assumptions.
Read also: LangChain vs LangGraph vs Raw OpenAI: How to Choose Your RAG Stack →
Document grading tips for production
Learn some useful tips for implementation in production:
- Cache intelligently: if the same question is asked frequently, cache the graded result. No need to re-grade identical queries.
- Fail gracefully: if grading fails (API timeout, etc.), fall back to naive top-K. Some answers are better than no answer.
- Monitor quality: track which documents consistently grade high or low. Low-grading popular documents might need content improvements.
- Tune for your domain: our criteria work for professional knowledge management. Adjust grading prompts for your specific use case and content types.
- Consider cost tiers: offer "fast mode" (no grading) and "accurate mode" (with grading) to let users choose their trade-off.
Higher RAG accuracy with document grading – conclusion
Document grading bridges the gap between semantic similarity and actual relevance in RAG systems. By introducing a second stage where an LLM evaluates whether candidates truly answer the question, we dramatically improved answer quality in our production deployment while keeping costs reasonable.
The approach is conceptually simple: retrieve broadly, grade precisely, generate a relevant response from the best. But the impact is substantial – transforming a system that returns plausible-but-wrong answers into one user's trust for professional decision-making.
Is it worth the extra $0.01 and 3 seconds per user query? For knowledge management, professional services, technical documentation, and other high-stakes applications, absolutely. The cost of wrong information far exceeds the cost of grading.
If you're building a single RAG chatbot and finding that users complain about answer quality despite good retrieval, document grading might be your solution. Start simple, measure results, and iterate based on your specific domain and users.
Want to build production-grade RAG Chatbots?
This blog post is based on our real production implementation of a RAG chatbot for a professional knowledge management platform. You can read the complete case study, including details on intelligent question routing, real-time content synchronization, and other optimizations we implemented.
Interested in implementing RAG with document grading or other solutions for your organization? Our team specializes in building production-ready AI applications that deliver real business value. Check out our AI development services and get in touch to discuss your project.










