

Die modernen Intranets von Unternehmen speichern enorme Mengen an Dokumenten, Verfahren, Anweisungen und organisatorischem Wissen. Die traditionelle, auf Schlüsselwörtern basierte Suche scheitert oft, wenn Benutzer mit Begriffen suchen, die nicht in den Dokumenten enthalten sind.
Problem: Ein Mitarbeiter sucht nach "Zugangsrechte zum Zahlungssystem konfigurieren", aber das Dokument enthält den Ausdruck "Zahlungsintegration konfigurieren". Die traditionelle Suche findet dieses Dokument nicht, obwohl es die Antwort auf die Frage enthält.
Lösung: RAG (Retrieval-Augmented Generation) mit einer Vektor-Datenbank ermöglicht eine semantische Suche. Das System versteht die Bedeutung der Abfrage und findet Dokumente basierend auf dem Kontext, nicht nur auf exakten Wortübereinstimmungen.
In diesem Artikel werden wir Ihnen zeigen, wie Sie die Milvus-Vektor-Datenbank mit Open Intranet auf Drupal integrieren, um eine intelligente Suche in Unternehmenswissensdatenbanken zu erstellen.
In diesem Artikel:
- Was ist RAG und warum ist es wichtig für Intranets?
- Open Intranet: Starter-Kit für Unternehmensintranets
- Was ist Milvus? Vektor-Datenbank für RAG
- Wie sieht die Integrationsarchitektur aus? Open Intranet + Milvus RAG
- Wie installiert man Open Intranet mit der Milvus RAG Option? Schritt für Schritt
- Wie funktioniert die RAG-Suche? Anwendungsbeispiele
- Wie kann Milvus RAG in Organisationen nützlich sein?
- Welche Technologien wurden in der Open Intranet + Milvus Vektor-Datenbank Demo verwendet?
- Häufig gestellte Fragen (FAQ) zur Milvus Vektor-Datenbank im Intranet?
- Milvus Vektor-Datenbank im Intranet - Zusammenfassung
- Muss man eine Vektor-Datenbank in Ihrem Intranet implementieren?
Was ist RAG und warum ist es wichtig für Intranets?
RAG (Retrieval-Augmented Generation) ist eine Technologie, die semantische Suche mit von AI generierten Antworten kombiniert. Im Kontext von Unternehmensintranets bietet RAG viele Vorteile.
Semantische Suche
Anstatt nach exakten Schlüsselwörtern zu suchen, versteht das System die Absicht des Benutzers.
Beispiel:
- Benutzerabfrage: "Wie setze ich das Administrator-Passwort zurück?"
- Traditionelle Suche: Sucht nach Dokumenten, die genau diese Wörter enthalten.
- Semantische Suche: Findet Dokumente über "Zugriff wiederherstellen", "Anmeldedaten ändern" oder "Admin-Rechte wiederherstellen". Selbst wenn sie nicht genau diese Wörter enthalten.
Bessere Ergebnisse für Benutzer
Die Analyse von Kundenanfragen zeigt, dass 66% der Organisationen, die Intranet-Lösungen suchen, eine erweiterte Suche oder AI-Suche benötigen. Dies ist kein Zufall - in großen Organisationen mit tausenden von Dokumenten ist die traditionelle Suche nicht mehr ausreichend. Künstliche Intelligenz versteht den Kontext und die Absicht des Benutzers und eignet sich daher ideal für die Arbeit mit umfangreichen Wissensdatenbanken.
Skalierbarkeit
Vektordatenbanken, wie Milvus, können Millionen von Dokumenten verarbeiten und dabei schnelle Antwortzeiten beibehalten. Dies ist entscheidend für Organisationen mit umfangreichen Wissensdatenbanken.
Leistung
Schnelle Ähnlichkeitssuche auch in großen Datensätzen. Milvus verwendet fortschrittliche Indexierungs-Algorithmen (HNSW, IVF) um Abfragen zu optimieren.
Flexibilität
Erweiterbar mit zusätzlichen KI-Funktionen:
- KI-Chatbots mit Zugriff auf Dokumente oder Unternehmenswissen.
- Automatische Dokumentenmarkierung.
- Empfehlungen für ähnlichen Inhalt.
- Stimmungsanalyse im Unternehmensinhalt.
Open Intranet: Starter-Kit für Unternehmensintranets
Open Intranet ist ein Open-Source-Starter-Kit auf Drupal zur Erstellung von Unternehmensintranets.
Es beinhaltet fertige Intranet-Funktionen wie:
- Zusammenarbeit und Kommunikation,
- Nachrichten- und Ereignissystem,
- Dokumentenaustausch,
- Wissensdatenbank,
- Mitarbeiterverzeichnis.
Das System ermöglicht es Organisationen, schnell ein flexibles internes Portal zu starten, ohne alles von Grund auf neu erstellen zu müssen.
Open Intranet System mit fertiger Wissensdatenbank
Was ist Milvus? Vektor-Datenbank für RAG
Milvus ist eine Open-Source-Vektor-Datenbank, die speziell für das Speichern, Indizieren und Durchsuchen von vektorisierten Darstellungen von Texten (sog. Embeddings) entwickelt wurde.
Wie arbeitet Milvus im Kontext von RAG?
- Indizierung: Dokumente aus dem Intranet werden von einem KI-Modell verarbeitet (z. B. OpenAI-Text-Embedding-3-small), das Vektoren erstellt, die die Bedeutung des Textes repräsentieren.
- Speicherung: die Vektoren werden zusammen mit Metadaten (Titel, URL, Datum) in Milvus gespeichert.
- Suche: wenn ein Benutzer eine Frage stellt, wird die Anfrage ebenfalls in einen Vektor umgewandelt und Milvus findet die ähnlichsten Dokumente basierend auf der Vektordistanz.
- Rückgabe der Ergebnisse: das System gibt Dokumente zurück, die nach semantischer Ähnlichkeit sortiert sind.
Warum Milvus Vektor-Datenbank?
- Open Source: volle Kontrolle über Daten, keine Abhängigkeit von Anbietern.
- Skalierbarkeit: unterstützt Millionen von Vektoren mit schnellen Reaktionszeiten.
- Bereite Integration: das ai_vdb_provider_milvus Modul für Drupal erleichtert die Integration.
- Standalone-Modus: für kleinere Organisationen kann es im Standalone-Modus auf einem einzelnen Server betrieben werden.
- Bereit für den Produktiveinsatz: skalierbar zu einem Cluster für größere Organisationen.
Lesen Sie auch: Empfohlene Vektor-Datenbanken (VDB) für Drupal - Überblick über AI-Anbieter
Wie sieht die Integrationsarchitektur aus? Offenes Intranet + Milvus RAG
Das folgende Diagramm zeigt die vollständige Integrationsarchitektur:
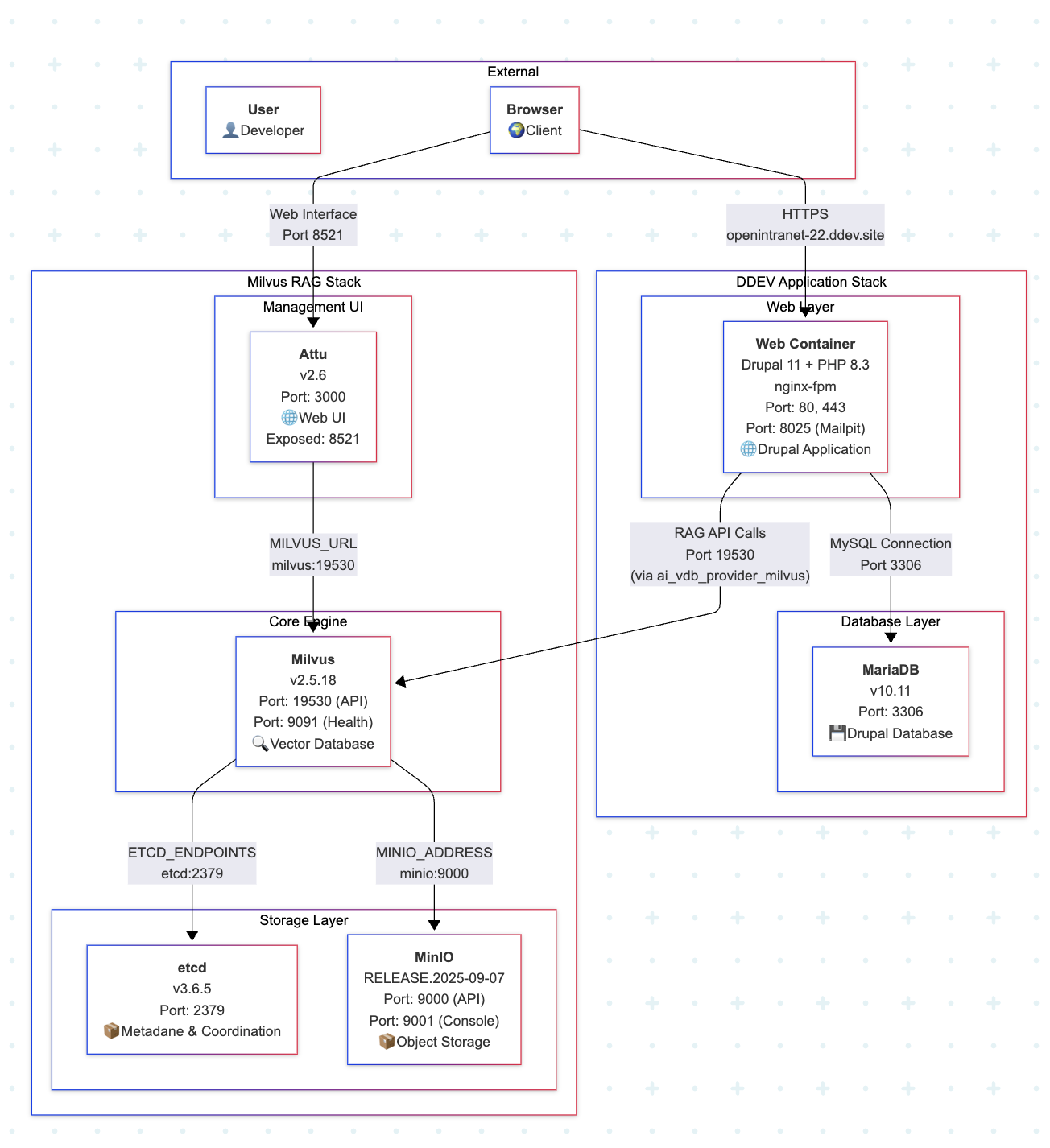
Diagramm erstellt mit dem Mermaid-Tool
Was sind die spezifischen Komponenten des Integrationssystems?
Jedes Element der Architektur spielt eine spezifische Rolle und stellt eine reibungslose Abfrageverarbeitung und Datenverwaltung im gesamten RAG-Umfeld sicher. Im Folgenden beschreiben wir, wie die einzelnen Komponenten innerhalb von Open Intranet zusammenarbeiten.
DDEV Application Stack
Diese Entwicklungs-Umgebung bietet eine vorgefertigte Infrastruktur für den Betrieb eines Intranets mit Milvus und automatisiert den größten Teil der Konfiguration. Dies ermöglicht es, das gesamte System innerhalb weniger Minuten lokal zu betreiben.
Web Container (Drupal Anwendung)
- Drupal 11 mit PHP 8.3.
- nginx-fpm als Webserver.
- Ports: 80 (HTTP), 443 (HTTPS), 8025 (Mailpit).
- Integration mit Milvus über das ai_vdb_provider_milvus-Modul.
MariaDB (Datenbank)
- Datenbank für Drupal.
- Version: MariaDB 10.11.
- Speichert alle Drupal-Daten (Inhalt, Konfiguration, Benutzer).
Milvus RAG Stack
Die Reihe von Diensten, die den Milvus RAG Stack bilden, ist verantwortlich für die Speicherung von Vektoren, Metadaten und die Ausführung von Suchanfragen. Jede Komponente des Systems spielt eine eigenständige Rolle bei der Gewährleistung hoher Leistung und Stabilität.
etcd (Storage Layer)
- Speicherung von Metadaten und Koordination.
- Port: 2379.
- Speichert: Sammlungsschemas, Indizes, Konfigurationen.
- Warum etcd? Es handelt sich um einen verteilten Key-Value-Store, den Milvus zur Speicherung von Metadaten und zur Koordination zwischen Komponenten verwendet. Ohne etcd kann Milvus nicht funktionieren.
MinIO (Storage Layer)
- Objektspeicher für Vektordaten.
- Ports: 9000 (S3 API), 9001 (Web-Konsole).
- Speichert: Vektoren, Segmente, Binärdateien.
- Warum MinIO? Es handelt sich um einen Objektdatenspeicher, der mit der S3 API kompatibel ist. Milvus verwendet ihn zur Speicherung von tatsächlichen Vektordaten und Segmenten. Mit MinIO kann man große Mengen an Vektordaten effizient verwalten und skalieren.
Milvus (Core Engine)
- Die Haupt-Vektorsuchmaschine.
- Ports: 19530 (API), 9091 (Gesundheitsprüfung).
- Funktionen:
- Speicherung von Einbettungen in Form von Vektoren,
- semantische Ähnlichkeitssuche,
- Indizierung und Abfrageoptimierung,
- RESTful API zur Integration mit Drupal.
Attu (Management UI)
- Web-Schnittstelle zur Verwaltung von Milvus.
- Port: 8521 (von DDEV freigegeben).
- Eigenschaften:
- Durchsuchen von Sammlungen und Daten,
- Leistungsüberwachung,
- Indexverwaltung,
- Visualisierung von Suchergebnissen.
Wie sieht der Datenfluss in einem mit der Milvus Vektor-Datenbank integrierten Intranet aus?
Der Datenfluss zwischen Drupal, dem Embeddings-Modell und der Milvus Vektor-Datenbank beinhaltet mehrere Schlüsselschritte, die zusammen einen intelligenten Suchprozess bilden. Im Folgenden beschreiben wir, wie dies ab dem Moment abläuft, in dem eine Anfrage gestellt wird, bis zur Präsentation der Ergebnisse.
Semantische Suche
- Der Benutzer stellt eine Frage auf der Intranet-Oberfläche.
- Drupal konvertiert die Anfrage in einen Vektor mit Hilfe des Embeddings-Modells (OpenAI Text-Embedding-3-Small).
- Die Anfrage wird an Milvus gesendet über das ai_vdb_provider_milvus Modul.
- Milvus sucht nach ähnlichen Vektoren in der Datenbank.
- Milvus gibt die Ergebnisse zurück sortiert nach semantischer Ähnlichkeit.
- Drupal zeigt die Ergebnisse dem Benutzer mit dem Titel, einem Ausschnitt des Inhalts und dem Ähnlichkeitsscore.
Content-Indizierung
- Ein neues Dokument wird in der Wissensdatenbank im Intranet hinzugefügt.
- Drupal erzeugt automatisch ein Embedding mit Hilfe der OpenAI API.
- Das Embedding wird in Milvus gespeichert zusammen mit den Metadaten (Titel, URL, Datum).
- Das Dokument ist bereit für die semantische Suche.
Lesen Sie auch: Wie wir die Genauigkeit der Antworten des RAG Chatbots um 40% verbessert haben
Wie installiert man das Open Intranet mit der Milvus RAG-Option? Schritt für Schritt
Der Installationsprozess wurde dank eines vorgefertigten Skripts, das automatisch alle benötigten Komponenten konfiguriert, so sehr vereinfacht. Es müssen nur einige Befehle ausgeführt werden, um eine vollständige RAG-Demo in Ihrer Umgebung zu starten.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie Folgendes haben:
- Docker Desktop — läuft und ist aktiv.
- DDEV — installiert (brew install ddev/ddev/ddev unter macOS).
- OpenAI API Key — erforderlich zur Generierung von Embeddings.
- Herunterzuladen von: https://platform.openai.com/api-keys.
- Der Schlüssel muss mit sk-proj- oder sk- beginnen.
- Kosten: ~$0,01-0,10 für die gesamte Demo.
Open Intranet RAG-Demo Installationsprozess
Verwenden Sie den folgenden Befehl:
git clone https://github.com/droptica/openintranet_rag_demo.git
cd openintranet_rag_demo
./launch_openintranet_with_rag_demo.shDas Skript führt automatisch Folgendes aus:
- Klonen von Open Intranet von Drupal.org.
- Herunterladen der Docker-Compose-Konfiguration für Milvus VDB.
- Konfiguration von DDEV (Drupal 11, PHP 8.3).
- Starten von Containern (Web, DB, Milvus).
- Installation von Composer-Abhängigkeiten.
- Hinzufügen des drupal/ai_vdb_provider_milvus:^1.1@beta Moduls.
- Kopieren des Rezepts (Drupal-Rezept) openintranet_milvus_rag.
- Installation von Drupal mit Demo-Inhalt.
- Anwendung der Milvus RAG-Rezept-Konfiguration.
- Interaktive Anforderung des OpenAI API-Schlüssels (Validierung des Formats).
- Speichern des API-Schlüssels in dem Key-Modul in Drupal.
- Indizierung von Knowledge-Base-Inhalten nach Milvus.
- Generierung eines einmaligen Login-Links.
Während der Installation werden Sie aufgefordert, den OpenAI API-Schlüssel einzufügen. Das Skript validiert das Format und speichert es sicher.
Überprüfung der Installation
Nach Abschluss der Installation ist es sinnvoll, sicherzustellen, dass alle Elemente korrekt funktionieren und miteinander kommunizieren. Einige einfache Befehle überprüfen schnell, ob die Indizierung und semantische Suche korrekt funktionieren.
1. Überprüfung des Indexstatus
cd openintranet_source_code/openintranet
ddev drush search-api:statusErwartetes Ergebnis:
knowledge_base_content Knowledge Base Content 100% 24 24
Wenn Sie 100% sehen - alles funktioniert!
2. Überprüfung der Verbindung zu Milvus
- Öffnen Sie das Milvus Attu UI: Überprüfen Sie den Port mit ddev describe (suchen Sie nach dem Port des Attu-Dienstes).
- Verbinden Sie sich mit: http://milvus:19530.
- Finden Sie die Sammlung: openintranet_knowledge_base.
- Überprüfen Sie: Entity Count > 0
3. OpenAI API-Test
cd openintranet_source_code/openintranet
ddev drush php:eval "
$provider = Drupal::service('ai.provider')->createInstance('openai');
$result = $provider->embeddings('test', 'text-embedding-3-small', []);
echo count($result->getNormalized()) . ' dimensions';
"Erwartetes Ergebnis: 1536 Dimensionen
Screen mit laufender Milvus Vektor-Datenbank für Open Intranet
Brauchen Sie mehr technische Informationen?
Für weitere technische Informationen, einschließlich detaillierter Tipps zur Fehlerbehebung, siehe die Projekt-README auf GitHub: https://github.com/droptica/openintranet_rag_demo.
Wie funktioniert die RAG-Suche? Anwendungsbeispiele
Das fertige Drupal-Rezept von Droptica enthält eine Beispielseite für die RAG-Suche unter /search-rag-example. Zum Testen:
- Öffnen Sie die Seite: https://your-site.ddev.site/search-rag-example.
- Geben Sie eine Suchanfrage ein (z.B., "milvus configuration").
- Überprüfen Sie die Anzeige der Ergebnisse aus:
- Titel (Link zur Ursprungsseite),
- Inhaltsschnipsel,
- Ähnlichkeitsergebnis.
Suchbeispiel
Um zu zeigen, wie RAG in der Praxis funktioniert, veranschaulicht das folgende Beispiel den Unterschied zwischen einer traditionellen Suche und den Ergebnissen, die mit der Milvus-Vektordatenbank erzielt wurden.
Nutzeranfrage: "wie konfiguriere ich den Zugang zum System."
Traditionelle Suche wird nur Dokumente finden, die genau diese Wörter enthalten.
RAG Suche findet Dokumente über:
- Berechtigungskonfiguration,
- Zugriffsmanagement,
- Einstellungen des Autorisierungssystems,
- Anmeldeanweisungen.
Auch wenn die Dokumente nicht den genauen Satz "wie konfiguriere ich den Zugang zum System" enthalten.
Wie kann Milvus RAG in Organisationen nützlich sein?
Milvus ermöglicht es Organisationen, RAG in verschiedenen Geschäftsszenarien zu nutzen, von der Dokumentensuche bis zur Inhaltsanalyse. Hier sind einige Beispiele.
1. Dokumentensuche
Auffinden von Dokumenten basierend auf Bedeutung und Kontext, anstelle von Schlüsselwörtern. Beispiel: Ein Mitarbeiter sucht nach "Notfallverfahren" und das System findet Dokumente über "Business Continuity Plans" und "Krisenszenarien."
2. Chatbots mit Unternehmenswissen
Erstellung von Chatbots mit Zugang zum aktuellen Wissen der Organisation. Der Chatbot kann Fragen von Mitarbeitern beantworten, indem er Dokumente aus dem Intranet als Wissensquelle nutzt.
3. Inhaltsvorschläge
Ähnlichen Inhalt auf der Basis semantischer Ähnlichkeit für die Nutzer vorschlagen. Beispiel: Nach dem Lesen eines Dokuments über "Datensicherheit" schlägt das System Dokumente über "DSGVO" und "Datenschutz" vor.
4. Automatisches Taggen
Automatisches Zuweisen von Tags basierend auf dem Dokumenteninhalt. Das System analysiert die Bedeutung des Textes und ordnet ohne manuellen Eingriff entsprechende Kategorien zu.
5. Sentiment-Analyse
Analysieren des Sentiments in Unternehmensinhalten. Das System kann Dokumente identifizieren, die aktualisiert werden müssen, oder solche, die eine positive Organisationskultur aufbauen können.
Welche Technologien wurden in der Open Intranet + Milvus Vektordatenbank Demo verwendet?
Sehen Sie sich die detaillierte Liste der verwendeten Technologien an.
Drupal 11
- Version: 11.x
- PHP: 8.3
- Datenbank: MariaDB 10.11
- Webserver: nginx-fpm
Milvus
- Version: 2.5.18
- Modus: Standalone (für die Entwicklung)
- API: RESTful auf Port 19530
- Einbettungen: 1536 Dimensionen (text-embedding-3-small)
OpenAI
- Modell Einbettungen: text-embedding-3-small
- Dimensionen: 1536
- Kosten: ~$0.01-0.10 für die gesamte Demo
DDEV
- Version: v1.24.10
- Plattform: Docker Desktop
- Netzwerk: ddev_default (externes Netzwerk)
Häufig gestellte Fragen (FAQ) zur Milvus Vektordatenbank im Intranet?
Sehen Sie sich die am häufigsten gestellten Fragen und Antworten zur Integration von Milvus in Ihr Intranet an.
Braucht RAG für die OpenAI API eine ständige Internetverbindung?
In der Demo-Version des Projekts auf GitHub ist eine Verbindung zur OpenAI API erforderlich. Die Lösung kann jedoch je nach den Bedürfnissen der Organisation mit anderen Einbettungsmodellen konfiguriert werden, z.B. mit lokalen Modellen (Sentence Transformers) die ohne Internetverbindung arbeiten oder anderen Cloud-APIs (Claude, lokale KI-Server).
Wie hoch sind die Kosten für die Nutzung der OpenAI API für Einbettungen?
Das Modell text-embedding-3-small kostet $0.02 pro 1M Tokens. Für eine typische Wissensbasis von 1.000 Dokumenten (durchschnittlich 500 Wörter jedes), beträgt die Indexierungskosten etwa $0.10-0.50 einmalig. Die Suche erfordert nur das Generieren einer Einbettung für die Anfrage (ein paar Wörter), daher sind die Kosten minimal.
Lesen Sie auch: Wie wir KI-API-Kosten um 95% mit intelligenter Fragenrouting reduziert haben
Wie kann die Lösung für eine größere Organisation skaliert werden?
Für größere Organisationen können Sie:
- vom Standalone-Modus zum Milvus-Cluster (mehrere Knoten) wechseln,
- größere MinIO-Instanzen für mehr Kapazität verwenden,
- etcd auf separate Knoten aufteilen für eine bessere Leistung,
- Lastverteiler vor die Milvus API hinzufügen.
Können andere Einbettungsmodelle anstelle von OpenAI verwendet werden?
Ja, das ai_vdb_provider_milvus-Modul ist unabhängig von der Quelle der Einbettungen. Sie können andere Anbieter (Claude, lokale Modelle) verwenden, solange sie Vektoren im richtigen Format zurückgeben.
Wie oft sollte der Inhalt neu indiziert werden?
Das hängt von der Häufigkeit der Änderungen in der Wissensbasis ab. Für dynamische Intranets mit häufigen Updates können Sie automatische Neuindizierung bei jeder Inhaltsänderung konfigurieren. Für statischere Datenbanken ist eine Neuindizierung einmal täglich oder einmal wöchentlich ausreichend.
Funktioniert die Lösung für Organisationen mit Compliance-Anforderungen (DSGVO, Gesundheitssektor)?
Ja, da alle Komponenten (Drupal, Milvus, etcd, MinIO) auf eigenen Servern betrieben werden können, verlassen die Daten nie die Infrastruktur der Organisation. Dies ist für Organisationen mit Compliance-Anforderungen entscheidend. Die OpenAI API verlangt das Senden von Dokumenteninhalten, daher können für besonders sensible Daten lokale Einbettungsmodelle in Betracht gezogen werden.
Was sind die Hardware-Anforderungen für Milvus im Standalone-Modus?
Für kleine Organisationen (bis zu 10.000 Dokumente) ist folgendes ausreichend:
- 4GB RAM
- 2 CPU-Kerne
- 20GB Festplatte
Für größere Organisationen steigen die Anforderungen proportional zur Anzahl der Dokumente und Anfragen.
Milvus Vektordatenbank im Intranet – Zusammenfassung
Die Integration von Milvus RAG mit Open Intranet eröffnet neue Möglichkeiten für Unternehmensplattformen. Die wichtigsten Vorteile sind:
- Intelligente Suche basierend auf Bedeutung, nicht nur Schlüsselwörtern.
- Besseres Benutzererlebnis im Intranet dank Verständnis von Kontext und Absicht.
- Skalierbarkeit für Organisationen mit großen Wissensbasen.
- Flexibilität bei der Erweiterung um zusätzliche KI-Funktionen.
Alle Komponenten sind Open Source, was volle Kontrolle über die Daten und keinen Herstellerbindungen bedeutet. Die Lösung ist produktionsreif und kann entsprechend den Anforderungen der Organisation skaliert werden.
Brauchen Sie eine Vektordatenbank in Ihrem Intranet?
Bei Droptica entwerfen und implementieren wir KI-basierte Lösungen mit LLMs, Vektordatenbanken und fortschrittlichen RAG-Pipelines. Wir helfen Ihnen bei der Auswahl der richtigen Technologie, integrieren semantische Suche, erstellen Unternehmenschatbots und optimieren die Qualität der generierten Antworten. Schauen Sie sich unseren Entwicklungsservice für generative KI an und sehen Sie, wie wir Ihre Organisation beim Aufbau intelligenter datengetriebener Lösungen unterstützen können.










