
AI Terms You Need to Know. Part Two – 31 Advanced Phrases and AI Solutions

Our previous article on AI terms introduced you to the basic dictionary. In this part, we'll dive into more specialized phrases that will help you understand the technical discourse and enable you to discuss AI systems with more tech-oriented people. You'll also find some explanations of the inner workings of existing AI solutions such as ChatGPT, Stable Diffusion, HuggingFace, etc.
Advanced AI terms
Our earlier article included basic AI terms, such as big data, chatbot, fine-tuning, and large language model (LLM). This blog post will present more advanced information, but understanding that fundamental terminology will be beneficial.
Artificial Neural Network
It’s a computing system inspired by the biological neural networks of animal brains. These networks comprise interconnected units (neurons) that process data and can learn to perform tasks. A single neuron is called a “perceptron.” It consists of inputs that are multiplied by associated weights, a summation node, and an activation function determining the output of a neuron.
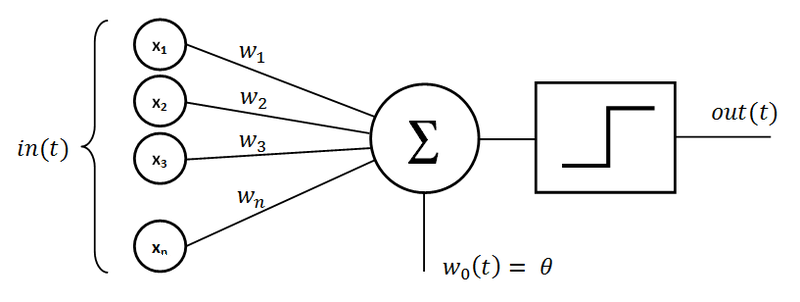
Source: wikipedia.org
Classifier
A classifier is a type of AI model used in machine learning for categorization tasks. It assigns labels or categories to input data based on learned patterns. Classifiers are widely used in applications like spam detection, image recognition, and sentiment analysis.
Context window
This term refers to an essential characteristic of Large Language Models (LLMs) that determines the extent of input data they can consider at any given time. The context window represents the number of tokens an LLM can process or “remember” during an interaction. In practical terms, this feature is crucial for maintaining the coherence and continuity of conversations or text-generation tasks.
As LLMs, like those in the GPT (Generative Pre-trained Transformer) series, handle inputs, they incorporate conversational history along with new prompts. Without a sufficiently large context window, these models might treat each input independently, leading to responses that appear disconnected from the ongoing conversation. The size of the context window is usually specified as a number of tokens.
For instance, OpenAI's GPT-3.5-turbo model has a context window of 16,385 tokens. This means that after processing this many tokens (including user inputs and model responses), the model starts to “forget” the earliest parts of the interaction. In such cases, it might become necessary to reiterate or summarise key points of the conversation to keep the model aligned with the discussion's context.
In contrast, the more advanced GPT-4-turbo-1106 boasts a significantly larger context window of 128,000 tokens. This expansive window allows for much longer interactions, enabling the model to process and respond to extensive texts, such as an entire book like “Harry Potter and the Prisoner of Azkaban,” within a single conversation. This advancement greatly enhances the model's ability to engage in detailed and extended dialogues, providing more relevant and context-aware responses.
Addressing the limitations of the context window has led to various solutions. A common approach is the “rolling context window,” where only the most recent tokens within the limit are provided to the model, effectively maintaining the newest and most relevant parts of the conversation. More sophisticated methods include employing another LLM query to summarise the conversation thus far and optimizing the use of tokens for context retention.
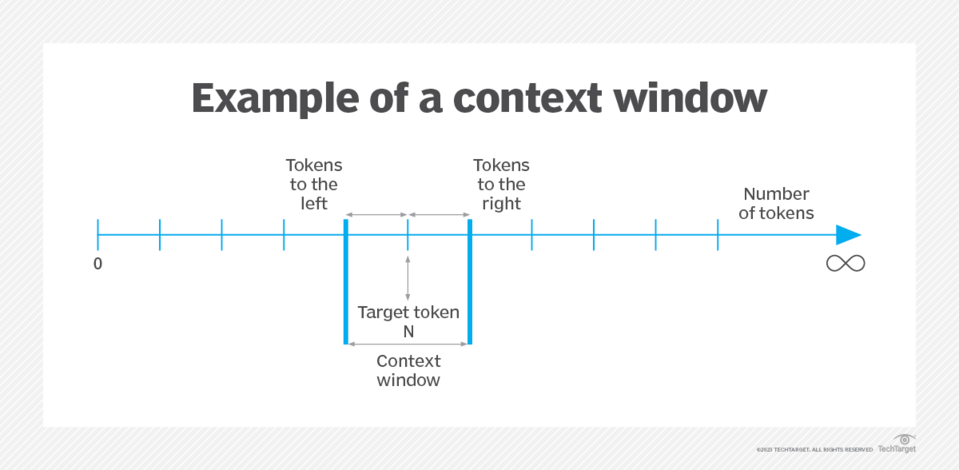
Source: techtarget.com
Deep Learning
A subset of machine learning, deep learning uses neural networks with multiple layers (hence “deep”) to analyze various data factors. It excels in tasks like image and speech recognition, where it can learn complex patterns and make decisions with high accuracy.
Embedding
In the context of AI and natural language processing, embedding refers to the process of converting data, such as text, into a set of vectors in a high-dimensional space. This transformation allows complex data like words, sentences, or even entire documents to be represented in a format that AI models, especially neural networks, can process. These vector representations capture semantic and syntactic relationships in the data, enabling the model to understand and work with natural language more effectively.
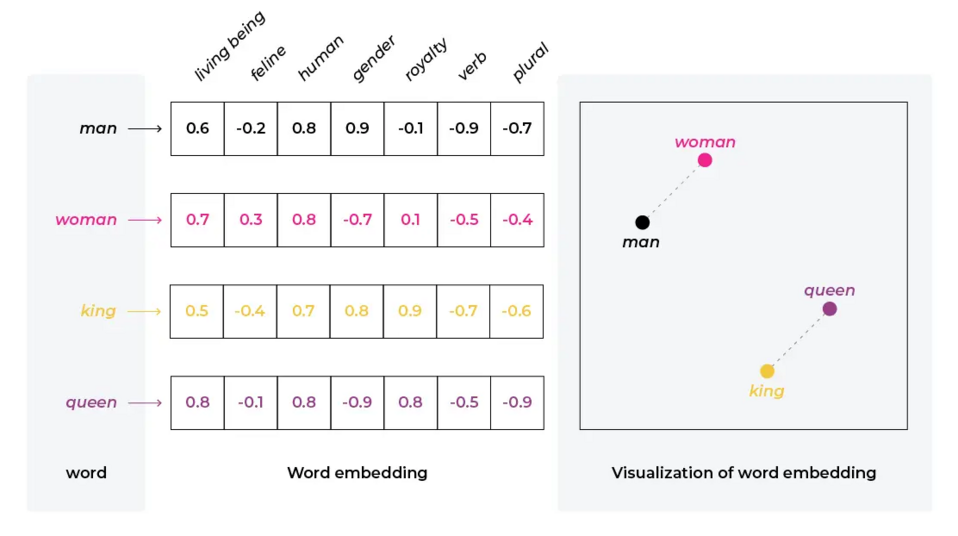
Example of vector representation of words, source: arize.com
Generative Pretrained Transformer
A Generative Pretrained Transformer is a series of large-scale language models developed by OpenAI. GPT models are trained on diverse text datasets and can generate human-like text. Thanks to their ability to understand and generate contextually relevant text, they’re versatile in various language tasks, including translation, question-answering, and content creation.
Hallucination
In the realm of Large Language Models (LLMs), hallucination refers to the phenomenon where the model generates incorrect or misleading information, often as a response to queries outside its training data scope. This behavior results in the model “fabricating” details or presenting false information. For instance, an LLM might suggest non-existent classes or functions in coding contexts.
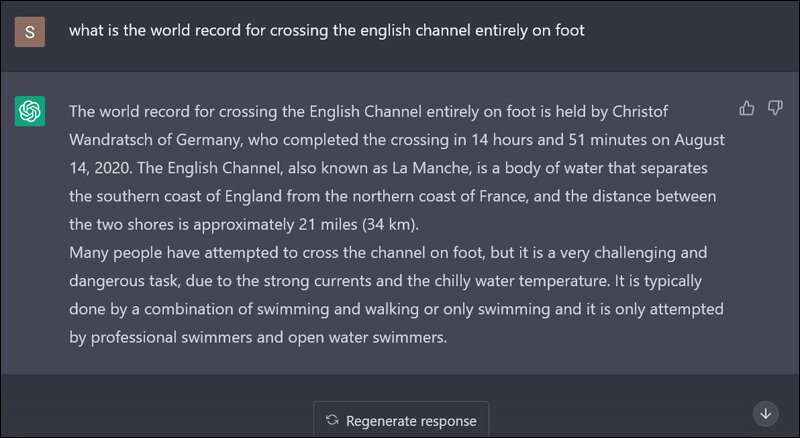
Example of hallucinations, source: sify.com
Similarly, in general knowledge queries, it might incorrectly assert that Zair is the only country starting with “Z,” disregarding or omitting countries like Zimbabwe. Hallucinations in LLMs highlight the limitations of these models, particularly when handling questions or tasks that require factual accuracy or lie beyond the bounds of their trained knowledge base.
Hypernetworking
This term refers to a novel approach within the field of neural networks, where one network, known as a hypernetwork, is employed to generate the weights for another network. This concept introduces an additional layer of abstraction and complexity to neural network design and training.
In hypernetworks, the primary focus is on optimizing the hypernetwork itself, which determines the target network's configuration and performance. This method can potentially enhance the efficiency of neural network training and allow for more dynamic and adaptable network behaviors.
Hypernetworks represent a cutting-edge area in neural network research, exploring new ways to leverage the relationships between different networks for more effective learning and problem-solving. For a detailed exploration of this concept, see this research paper on arXiv.
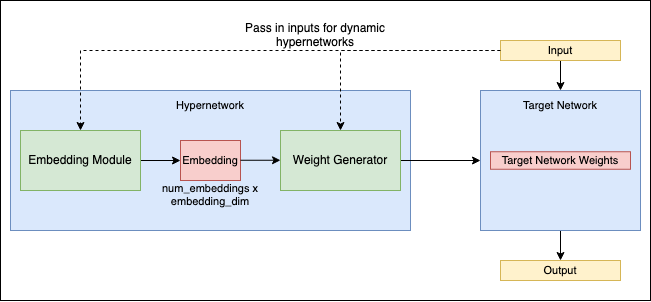
Source: github.com
Inference
In AI, inference refers to the process where a trained model makes predictions or decisions based on new, unseen data. It's the stage where the model applies what it has learned to real-world applications.
Latent space
In machine learning, the latent space refers to a compressed representation of the input data, often in a lower-dimensional form. It captures the essential aspects of the data and is used in generative models.
Low-Rank Adaptation (LORA)
LORA represents a specialized technique primarily utilized in Diffusion Models, and it's also applicable to Large Language Models (LLMs). In this approach, smaller auxiliary models are developed to work in conjunction with a “full model.” They operate by injecting their weights into a specific component of the larger model, typically the “Cross Attention Layer,” which plays a crucial role in the final stage of output generation.
For instance, in image generation using a diffusion model, if the goal is to create anime-style images of a specific person, rather than fine-tuning the entire diffusion model on that person's images, a LORA would be trained on these images and then used alongside an anime-capable model. This combination allows the larger model to generate personalized anime-style pictures of the individual.
Similarly, in the context of LLMs, LORA can be employed to introduce new concepts or knowledge areas into the model without the need for extensive retraining of the entire model. This technique offers a more efficient and targeted way to enhance and customize AI models for specific tasks or styles.
Machine Learning
A core subset of AI, machine learning involves training algorithms to make decisions or predictions based on data. It includes various techniques such as supervised learning, unsupervised learning, and reinforcement learning. Machine learning automates analytical model building, allowing systems to learn and adapt from experience without being explicitly programmed.
Reinforcement Learning
Reinforcement Learning is a type of machine learning where an agent learns to make decisions by performing actions in an environment to achieve some goal. The agent learns from trial and error, receiving rewards or penalties for actions, thus reinforcing favorable behaviors. For example, this technique can be used to teach an algorithm to play a video game by just interacting with it.
Supervised Learning
Supervised learning is a machine-learning approach where models are trained on labeled data. The model learns to predict outputs from input data, and its performance is measured against known labels. This approaches a set of data for the model to learn on in the form of vectors, which contain the input and expected output. Based on the difference between expected output, the behavior of the algorithm is adjusted (for example, by using backpropagation in Artificial Neural Networks).
Transformer
Behind this AI term is a revolutionary neural network architecture that has significantly advanced the field of natural language processing. Transformers are designed to handle sequential data and are notable for their self-attention mechanism, which allows them to weigh the importance of different parts of the input data. They are behind many state-of-the-art language models like GPT and BERT.
Unsupervised Learning
Unlike supervised learning, this approach involves training models on data without predefined labels. The model learns patterns and structures from the data itself.
Variational Autoencoder (VAE)
A VAE is a type of generative model used in machine learning, mainly known for its capability to encode input data into a compressed, latent space and subsequently reconstruct the input from this space. The model comprises two main components: an encoder that compresses the data into the latent space and a decoder that reconstructs the data from this space.
VAEs are especially effective in image-generation tasks. They can learn to produce new images that closely resemble the original training data, allowing for the creation of diverse styles and realistic pictures.
For instance, VAEs might be employed in a larger system where diffusion models are a part, especially in tasks involving image encoding and reconstruction. However, the core process of transforming noise into coherent images in diffusion models is typically managed by the diffusion process itself rather than by a VAE.
Vector
In the context of machine learning and AI, a vector is an array of numbers representing data. In NLP, for instance, words are often converted into vectors, which algorithms use to process and understand text.
Vector database – it’s specifically engineered for storing and querying vector data, which are representations of data points in a high-dimensional space. This type of database is particularly relevant in scenarios involving embeddings, where diverse data types, such as text or images, are transformed into a vector format.
The core strength of a vector database lies in its ability to perform operations like similarity searches efficiently. This capability is crucial in various applications, including recommendation systems. Their goal is to find items similar to a user's interests and image retrieval tasks, where the objective is to locate images that are visually akin to a query image.
Real-world application example – a practical use case for vector databases is enhancing the capabilities of a Large Language Model (LLM). For instance, rather than fine-tuning an LLM with specific website data, the website's content can be stored as vectors in a vector database. When a user query is received, the vector database can be searched to find the most relevant content vectors that closely match the query.
These relevant vectors can then be fed as additional context to the LLM prompt. This approach allows the model to generate responses that are more aligned with the specific content and themes of the website, thus providing more accurate and contextually appropriate answers to user queries.
AI tools, solutions, and useful websites
In addition to advanced AI terms, it's also useful to be familiar with tools and websites in this field that can be handy for various activities. It's impossible to list a finite number of examples of such solutions, as new ones are being created all the time. However, we provide our subjective selection.
Automatic1111/stable diffusion webUI
Automatic1111/stable diffusion webUI - called Automatic1111 or A1111 by the community, is a popular implementation of the Stable Diffusion model, often used for image generation tasks. It's known for its user-friendly interface and efficient processing, making advanced image synthesis more accessible. This implementation enables users to insert a wide range of model checkpoints trained by the community to generate images in different styles. It also allows image-to-image generation, inpainting, upscaling of generated images, training, and merging of model’s checkpoints.
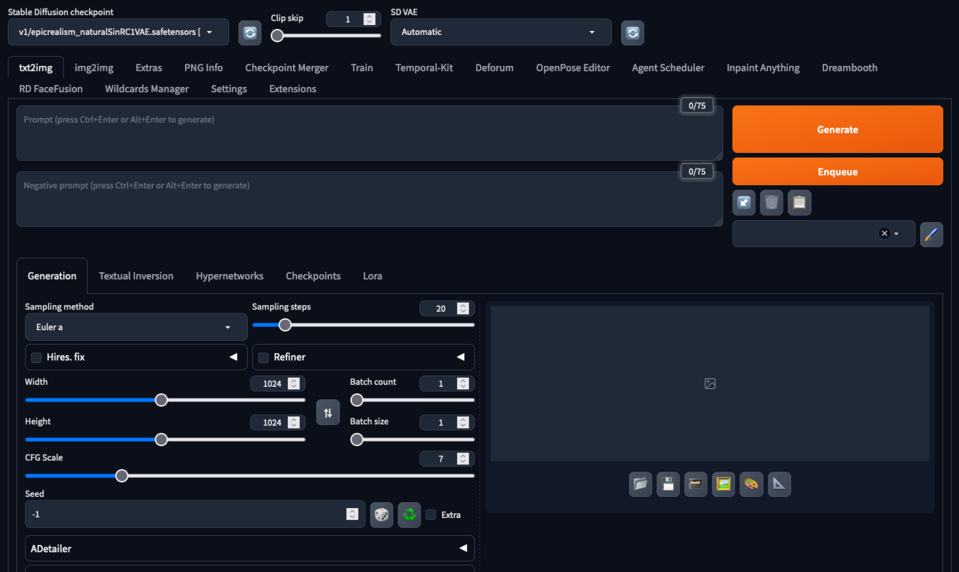
Automatic1111 interface
Google Bard
Bard is a conversational generative AI chatbot developed by Google. Initially based on the LaMDA family of Large Language Models (LLMs), it was later upgraded to PaLM and then to Gemini. Bard was created as Google's response to the rise of OpenAI's ChatGPT and was launched in a limited capacity in March 2023. Its development and release were part of Google's intensified focus on AI in response to the growing prominence of ChatGPT. Bard is designed to function similarly to ChatGPT, providing conversational AI services but with integration into Google's search capabilities and other products.
ChatGPT
Developed by OpenAI, ChatGPT is a variant of the GPT (Generative Pre-trained Transformer) AI model, designed specifically for generating human-like text in a conversational context. It excels in various language tasks, including chatting, answering questions, and completing text.
CivitAI
CivitAI is a platform focused on generative AI, hosting a variety of open-source models and tools. The website features a collection of images and models created by the community, showcasing applications ranging from simple shapes to complex landscapes and human faces. Civitai serves as a hub for creativity and inspiration. It offers resources, guides, and tutorials on generative AI. The site also organizes challenges and events, encouraging community engagement and collaboration in the field of AI-generated art and content.
CLIP
Contrastive Language-Image Pre-Training (CLIP) is a type of neural network model developed by OpenAI that is trained on a diverse range of image and text pairs. This innovative approach enables the model to understand and interpret images in the context of natural language. One of the critical capabilities of CLIP is its ability to effectively associate images with textual descriptions.
DALL-E
Also developed by OpenAI, DALL-E is an AI diffusion model known for its ability to generate creative and detailed images from textual descriptions. It showcases the potential of AI in artistic and creative applications. In the newest version, it’s integrated into the ChatGPT, allowing image generation via the chatbot’s interface and leveraging the ability of the chat model to refine the user prompts.

Graphics generated by Dall-E 2 based on prompt "Drupal software house"

Dall-E 3, with its interface integrated into ChatGPT
HuggingFace
HuggingFace is a company and platform known for its vast repository of pre-trained models and tools in natural language processing. This solution provides an accessible gateway for implementing and experimenting with advanced AI models. It’s a home of many open-source LLMs and Diffusion Models.
Stable Diffusion
Introduced in 2022, Stable Diffusion is a text-to-image diffusion model developed by Stability AI. It generates detailed images based on text descriptions using a variational autoencoder (VAE), U-Net, and an optional text encoder. The model compresses images into a smaller dimensional latent space, applying Gaussian noise iteratively during forward diffusion. The U-Net block, with a ResNet backbone, denoises the output, and the VAE decoder then converts the representation back into pixel space.
Stable Diffusion can be conditioned on text and images with the CLIP text encoder transforming text prompts into an embedding space. With its relatively lightweight architecture and ability to run on consumer GPUs, Stable Diffusion marked a departure from previous proprietary models like DALL-E, which were cloud-based.

Stable Diffusion generation for the prompt: “Drupal software house,” checkpoint used - “epicRealism”
LLAMA
Large Language Model Meta AI (LLAMA) is a family of large language models released by Meta AI in February 2023. It comprises models with 7, 13, 33, and 65 billion parameters. LLaMA models have shown notable performance on various NLP benchmarks, with the 13B parameter model outperforming GPT-3 (175B parameters) in specific tasks.
These models are significant for their accessibility. Meta released LLaMA's model weights to the research community under a noncommercial license. In July 2023, in partnership with Microsoft, Meta introduced LLaMA-2 with model sizes of 7, 13, and 70 billion parameters. LLaMA-2 includes foundational models and fine-tuned models for dialogue, called LLaMA-2 Chat, and offers improved data training and safety measures. However, shortly after its release, LLaMA's weights were leaked online, leading to widespread distribution.
Midjourney
Midjourney is a generative AI program created by the San Francisco-based independent research lab Midjourney, Inc. It generates images from natural language descriptions, similar to OpenAI's DALL-E and Stability AI's Stable Diffusion. Midjourney entered open beta in July 2022 and is accessible through a Discord bot. The tool has been utilized for various creative applications, including rapid prototyping in the arts. Midjourney's image-generation capabilities have also been a subject of debate and controversy, particularly concerning the originality and ethics of AI-generated art.
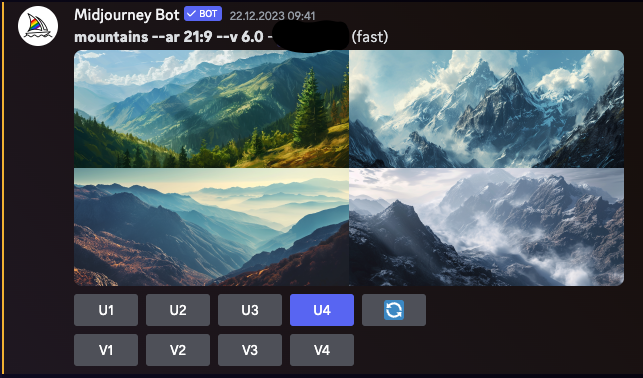
Images generated using Midjourney version 6.0 (Discord interface is clearly visible)
Pinecone
Pinecone is a vector database solution that is designed to handle high-dimensional data efficiently. Pinecone is particularly useful for similarity search applications, often in machine learning and AI contexts.
Text-generation-webui
Text-generation-webui is a Gradio-based web UI designed for interacting with various Large Language Models (LLMs). It supports a range of models like transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), and Llama models. The interface aims to be user-friendly, offering multiple modes like notebook, and chat. It includes numerous features like support for different model architectures, a dropdown menu for model and checkpoints switching, and integration with extensions for additional functionalities like long-term memory, or Text-to-speech. The repository provides detailed instructions for installation and usage, making it accessible for users looking to leverage LLMs for text-generation tasks.
Whisper
Developed by OpenAI, Whisper is a speech recognition model designed to provide speech-to-text (STT) capabilities. It aims to accurately transcribe audio into text, recognizing multiple languages and accents. Whisper is notable for its effectiveness in understanding spoken language, which makes it a valuable tool for a variety of applications, including automated transcription and assisting in accessibility for those with hearing impairments.
Advanced AI terms and solutions – summary
We hope that this article (especially when combined with the first part on basic terminology) will serve as a stepping stone into the broader world of AI, which is an ever-evolving, new, and exciting field. May this AI dictionary inspire you to explore the potential of artificial intelligence! And if you come up with an idea for a project that would benefit from AI development, our experienced developers are here to help.










