

Das Extrahieren strukturierter Metadaten aus rechtlichen Dokumenten gehört zu den anspruchsvollsten KI-Aufgaben in regulierten Branchen. Durch sorgfältige Aufforderungstechnik mit GPT-4o-mini und OpenAI's Structured Outputs können Teams eine Genauigkeit von 95%+ bei der Kategorisierung komplexer regulatorischer Dokumente über mehrere Taxonomien erreichen. In diesem technischen Leitfaden wird dargestellt, wie BetterRegulation Produktions-Prompt-Vorlagen entwickelt hat, die zuverlässig Dokumenttypen, Organisationen, Themenbereiche und rechtliche Verpflichtungen aus UK/Irland rechtlichen Texten extrahieren – dabei wird die manuelle Korrekturzeit pro Dokument von 15 Minuten auf 3 Minuten reduziert.
In diesem Artikel:
- Die Herausforderung: Strukturierte Datenauslesung aus unstrukturiertem juristischen Text
- Warum sind juristische Dokumente so schwierig mit KI zu verarbeiten?
- Wie verbessert die Taxonomieeinführung die Genauigkeit der Extraktion?
- Wie sorgt man für konsistente Ausgaben mit JSON Schema?
- Wie funktioniert semantisches Matching für Entitätsreferenzen?
- Wie optimiert man Aufforderungen für eine bessere Genauigkeit?
- Wie extrahiert man rechtliche Verpflichtungen aus Dokumenten?
- Codebeispiele und Aufforderungs-Vorlagen
- Aufforderungstechnik zur Datenauslesung – Abschluss
- Benötigen Sie Experten für die Aufforderungstechnik für Ihr KI-Projekt?
Die Herausforderung: Strukturierte Datenauslesung aus unstrukturiertem juristischen Text
Juristische Dokumente sind Schatztruhen voller strukturierter Informationen, die in dichtem, komplexem Prosa verborgen sind:
"Die Financial Conduct Authority gibt diese Anleitung gemäß Abschnitt 139A des Financial Services and Markets Act 2000 heraus, das durch das Financial Services Act 2012 geändert wurde und ab dem 1. Januar 2024 für alle Verbraucherkreditgeber und -verleiher gilt, die gemäß Teil II des Consumer Credit Act 1974 tätig sind..."
In diesem einen Satz verborgen:
- Dokumenttyp: Leitfaden
- Organisation: Financial Conduct Authority
- Gesetzgebung: Financial Services and Markets Act 2000
- Jahr: 2024
- Betroffene Parteien: Verbraucherkreditgeber und -verleiher
Ein menschlicher Jurist extrahiert dies sofort. Eine KI benötigt sorgfältige Anleitung – hier kommt die Aufforderungstechnik ins Spiel.
Dieser Artikel zeigt Ihnen, wie Sie Aufforderungen verfassen, die zuverlässig strukturierte Daten aus juristischen Dokumenten extrahieren und dabei eine Genauigkeit von 95%+ in der Produktion erreichen.
Warum sind juristische Dokumente so schwer mit KI zu verarbeiten?
Bevor wir uns den Lösungen zuwenden, ist es unerlässlich zu verstehen, welche spezifischen Herausforderungen die Auslesung von juristischen Dokumenten so schwierig machen. Juristische Texte stellen einzigartige Hindernisse dar, die herkömmliche Textverarbeitungsansätze nicht effektiv bewältigen können.
1. Komplexe Sprache
Juristische Texte verwenden:
- Archaistische Begriffe – "hierin", "während", "vorangehend"
- Geschachtelte Klauseln – Sätze, die Absätze umspannen
- Technisches Fachjargon – "force majeure", "res ipsa loquitur"
- Mehrdeutige Verweise – "das vorher genannte Gesetz" (welches?)
2. Mehrere Taxonomien
Ein einziges Dokument könnte eine Kategorisierung in folgenden Bereichen benötigen:
- Dokumenttyp (Gesetz, Verordnung, Leitfaden, Rechtsprechung)
- Organisation (ausstellende Behörde)
- Fachgebiet (Bankwesen, Datenschutz, Arbeitsrecht)
- Zuständigkeitsbereich (UK, EU, spezifische Länder)
- Rechtsvorschriften (welche Gesetze/Verordnungen gelten)
- Jahr, effektives Datum, Änderungshistorie
Jede Taxonomie hat 10-400 Begriffe. Das sind Hunderte mögliche Klassifikationen.
3. Variable Formate
Keine zwei juristischen Dokumente strukturieren Informationen auf die gleiche Weise:
Statut:
Banking Act 2023
Ein Gesetz zur Regulierung...
Von Parlament beschlossen: 15. März 2023Leitfaden:
FCA-Leitfaden Konsultationspapier CP23/15
Veröffentlicht: Dezember 2023
Für: Banken und BausparkassenRechtsprechung:
Regina gegen Financial Conduct Authority [2023] UKSC 42
Oberstes Gericht, 8. November 2023Dieselbe Information (Typ, org, Datum) in völlig unterschiedlichen Formaten.
4. Implizite vs. explizite Information
Manchmal wird die Information direkt angegeben:
> “Diese Verordnung gilt für alle Verbraucherkreditgeber...”
Andere Male ist sie impliziert:
> “Gemäß Teil II des Verbraucherkreditgesetzes...” (impliziert: betrifft Kreditgeber)
KI muss aus dem Kontext schließen.
Wie verbessert die Taxonomie-Injektion die Extraktionsgenauigkeit?
Die Grundlage für eine präzise Extraktion: Teilen Sie der KI Ihre Taxonomien im Voraus mit.
Vollständige Taxonomielisten im Kontext bereitstellen
Anstatt: „Kategorisiere dieses Dokument nach Typ, Organisation und Bereich."
Besser: „Ordne dieses Dokument diesen exakten Taxonomien zu:"
### DOKUMENTTYP-TAXONOMIE:
- Statute
- Regulation
- Guidance Note
- Code of Practice
- Case Law
### ORGANISATIONS-TAXONOMIE:
- Financial Conduct Authority
- Bank of England
- Competition and Markets Authority
- Information Commissioner's Office
[... vollständige Liste ...]
### DOKUMENTBEREICH-TAXONOMIE:
- Banking and Finance
- Consumer Credit
- Banking Regulation
- Data Protection
[... vollständige Liste ...]
Warum das funktioniert:
- Klare Grenzen – die KI weiß genau, welche Optionen existieren
- Semantisches Matching – die KI versteht, dass „FCA" = „Financial Conduct Authority"
- Gibt Taxonomie-Namen zurück – die KI liefert Begriffsnamen (z. B.
["Data Protection", "Financial Services", "GDPR"]), die das System dann über Drupals Taxonomie-Lookup auf Term-IDs abbildet - Keine Halluzinationen – die KI erfindet keine Kategorien
So funktioniert es:
Die KI gibt Taxonomie-Begriffsnamen zurück:
["Data Protection", "Financial Services", "GDPR"]
Das Drupal-System führt ein Taxonomie-Lookup durch:
- „Data Protection" → findet Term-ID: 42
- „Financial Services" → findet Term-ID: 87
- „GDPR" → findet Term-ID: 156
Dem Dokument wird zugewiesen: [42, 87, 156]
Dieser Ansatz nutzt das semantische Verständnis der KI und gewährleistet gleichzeitig präzise Entity-Referenzen durch Drupals Taxonomie-System.
Lohnt sich der Token-Aufwand?
„Aber verbraucht das nicht zu viele Tokens?"
Ja, es verbraucht Tokens. Aber es lohnt sich.
BetterRegulations Zahlen:
- Dokumenttext: 35.000 Tokens (typisches 50-seitiges PDF)
- Taxonomie-Kontext: 5.000 Tokens (alle Taxonomien)
- Anweisungen: 1.000 Tokens
- Gesamt: 41.000 Tokens
- Kontextlimit: 128.000 Tokens (GPT-4o-mini)
- Reserve: 87.000 Tokens (reichlich Spielraum)
Kosten:
- Mit Taxonomien: £0,21 pro Dokument
- Ohne Taxonomien (hypothetisch): £0,18 pro Dokument
- Mehrkosten: £0,03 pro Dokument
Nutzen:
- Genauigkeitssteigerung: 75 % → 95 %
- Manuelle Korrekturzeit: 15 Min. → 3 Min.
- Wert der Zeitersparnis: £2,00+ pro Dokument
ROI: 70-fache Rendite auf die Taxonomie-Token-Investition.
Wie erzwingt man konsistente Ausgaben mit JSON-Schema?
Sobald Sie der KI Taxonomien bereitgestellt haben, besteht der nächste entscheidende Schritt darin, sicherzustellen, dass sie Daten in einem konsistenten, parsefreundlichen Format zurückgibt. OpenAI's Structured Outputs garantieren, dass die Antworten jedes Mal exakt Ihrem JSON-Schema entsprechen.
Exakte Ausgabestruktur definieren
Vage Anweisung:
„Extrahiere den Dokumenttyp, die Organisation und das Jahr."
Die KI könnte zurückgeben:
Document type is Guidance Note
Organization: FCA
Year: 2024
Nicht parsebar. Das Format variiert jedes Mal.
Besser: Verwenden Sie OpenAI's Structured Outputs:
OpenAI bietet Structured Outputs, die garantieren, dass die Antwort des Modells exakt Ihrem JSON-Schema entspricht. Das ist robuster als der JSON-Modus – statt lediglich gültigem JSON erhalten Sie JSON, das garantiert Ihrer exakten Schema-Struktur entspricht.
Zwei verfügbare Ansätze:
- JSON-Modus (
type: "json_object") – garantiert gültiges JSON, erzwingt aber nicht Ihr spezifisches Schema - Structured Outputs (JSON Schema +
strict: true) – garantiert, dass die Ausgabe exakt Ihrem Schema entspricht (das verwendet BetterRegulation)
API-Konfiguration mit Structured Outputs:
$response = $client->chat()->create([
'model' => 'gpt-4o-2024-08-06', // Structured Outputs erfordern gpt-4o-Modelle
'messages' => [
['role' => 'user', 'content' => $prompt]
],
'response_format' => [
'type' => 'json_schema',
'json_schema' => [
'name' => 'document_metadata',
'strict' => true, // ← Erzwingt strikte Schema-Konformität
'schema' => [
'type' => 'object',
'properties' => [
'document_type' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'organization' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'document_area' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'year' => ['type' => 'string'],
'title' => ['type' => 'string'],
'source_url' => ['type' => 'string']
],
'required' => ['document_type', 'organization', 'document_area', 'year', 'title'],
'additionalProperties' => false
]
]
],
'temperature' => 0.1,
]);
Prompt-Text (Anweisungen):
Analyze the document and extract:
- document_type: The primary document type (return taxonomy term name as string in array)
- organization: The issuing organization (return taxonomy term name as string in array)
- document_area: All relevant subject areas (return taxonomy term names as strings in array)
- year: Publication year in YYYY format
- title: Document title
- source_url: Full URL if found in document
Use ONLY taxonomy term names from the provided taxonomy lists. The system will map these names to term IDs automatically.
Mit Structured Outputs gibt die KI konsistent zurück:
{
"document_type": ["Guidance Note"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Consumer Credit", "Banking Regulation"],
"year": "2024",
"title": "FCA Guidance on Consumer Credit Practices",
"source_url": "https://www.fca.org.uk/publication/guidance/gc24-1.pdf"
}
Hinweis: Das System führt dann ein Taxonomie-Lookup durch, um Begriffsnamen in IDs umzuwandeln:
- „Guidance Note" → Term-ID: 14
- „Financial Conduct Authority" → Term-ID: 23
- „Consumer Credit" → Term-ID: 35
- „Banking Regulation" → Term-ID: 36
Dem Dokument wird zugewiesen: document_type: [14], organization: [23], document_area: [35, 36]
Ergebnis: 100 % Schema-Konformität, garantiert. BetterRegulation hat Tausende von Dokumenten mit Structured Outputs verarbeitet – ohne einen einzigen Schema-Validierungsfehler. Das Modell kann keine Daten zurückgeben, die nicht dem JSON-Schema entsprechen – OpenAI erzwingt dies auf API-Ebene und eliminiert damit die Notwendigkeit umfangreicher Ausgabevalidierung in Ihrem Code.
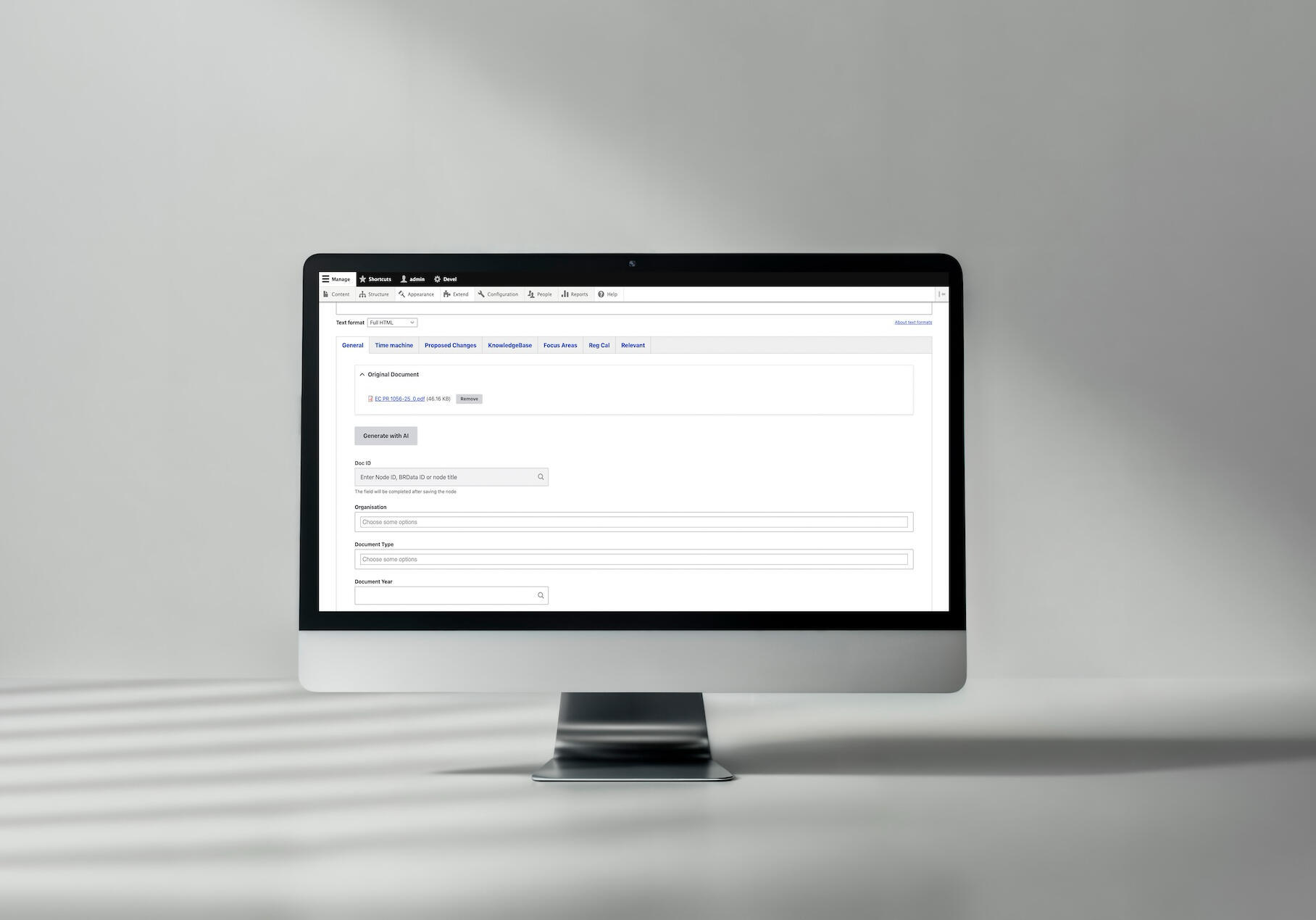
Ein Praxisbeispiel der KI-basierten Dokumentenkategorisierung bei Better Regulation
Zur vollständigen KI-Dokumentenkategorisierungs-Fallstudie →
Wie funktioniert semantisches Matching für Entity-Referenzen?
Mit strukturierter Ausgabe implementiert, besteht die nächste Herausforderung darin, sicherzustellen, dass die KI Dokumentinhalte korrekt Ihren spezifischen Taxonomie-Begriffen zuordnet. Hier wird semantisches Matching – die Fähigkeit der KI, Bedeutung jenseits exakter Textübereinstimmungen zu verstehen – entscheidend.
Wie die KI Begriffe zu Taxonomien zuordnet
Das Besondere: KI versteht Bedeutung, nicht nur Text.
Beispiel:
Taxonomie-Begriff: „Consumer Credit Lenders and Hirers"
Dokumentphrasen, die die KI erfolgreich zuordnet:
- „consumer lending practices"
- „personal loan providers"
- „credit companies offering hire purchase"
- „firms engaged in consumer finance"
- „lenders to individuals"
Wie? Große Sprachmodelle lernen semantische Beziehungen während des Trainings. Sie wissen:
- „lending" ≈ „lenders"
- „personal loan" ≈ „consumer credit"
- „hire purchase" → „hirers"
Traditionelles Keyword-Matching würde bei den meisten dieser Variationen versagen.
Name-zu-ID-Zuordnungsmechanismus
Entscheidende Design-Entscheidung: Die KI gibt Taxonomie-Begriffsnamen zurück, die das System dann über Drupals Taxonomie-Lookup auf Term-IDs abbildet.
Warum dieser Ansatz funktioniert:
// ✅ GUT: KI gibt Begriffsnamen zurück
{
"organization": ["Financial Conduct Authority"],
"document_area": ["Data Protection", "Financial Services"]
}
// System führt Taxonomie-Lookup durch
$organization_terms = \Drupal::entityQuery('taxonomy_term')
->condition('name', 'Financial Conduct Authority')
->condition('vid', 'organization')
->execute();
$area_terms = \Drupal::entityQuery('taxonomy_term')
->condition('name', ['Data Protection', 'Financial Services'], 'IN')
->condition('vid', 'document_area')
->execute();
// Namen auf IDs abbilden
$organization_id = reset($organization_terms); // z. B. 23
$area_ids = array_values($area_terms); // z. B. [42, 87]
// IDs dem Dokument zuweisen
$node->set('field_organization', ['target_id' => $organization_id]);
$node->set('field_document_area', array_map(function($id) {
return ['target_id' => $id];
}, $area_ids));
Vorteile des namensbasierten Ansatzes:
- Semantisches Matching – die KI kann ihr Verständnis nutzen, um Konzepte semantisch zuzuordnen, auch wenn exakte Begriffsnamen nicht im Dokument vorkommen
- Flexibilität – wenn Taxonomie-Begriffe umbenannt werden, funktioniert das Lookup weiterhin (solange die Namen übereinstimmen)
- Klarheit – Begriffsnamen sind für Menschen lesbar, was Debugging und Validierung erleichtert
- Präzision – das Lookup gewährleistet exakte Übereinstimmungen innerhalb des Taxonomie-Vokabulars und verhindert Mehrdeutigkeit
So funktioniert es:
- Die KI gibt Begriffsnamen basierend auf dem semantischen Verständnis des Dokuments zurück
- Das System führt ein Taxonomie-Lookup durch, um passende Term-IDs zu finden
- Dokumentfelder werden mit Term-IDs für Entity-Referenzen befüllt
Wie geht man mit mehrdeutigen Begriffen um?
Manche Begriffe sind wirklich mehrdeutig:
„ICO" könnte bedeuten:
- Information Commissioner's Office (Datenschutz)
- Initial Coin Offering (Kryptowährung)
Strategie 1: Kontexthinweise im Prompt
If document discusses data protection, "ICO" likely means "Information Commissioner's Office".
If document discusses cryptocurrency, "ICO" likely means "Initial Coin Offering".
Use document context to disambiguate.
Strategie 2: Mehrere Optionen zulassen
If ambiguous, return multiple possible term names:
{
"organization": ["Information Commissioner's Office", "Initial Coin Offering"]
}
Das System schlägt beide Namen nach und gibt deren IDs zurück. Ein menschlicher Prüfer wählt dann die richtige Option aus.
Strategie 3: Konfidenzwerte (fortgeschritten)
{
"organization": [
{"term_name": "Information Commissioner's Office", "confidence": 0.8},
{"term_name": "Initial Coin Offering", "confidence": 0.2}
]
}
Höchsten Konfidenzwert auswählen, niedrige Konfidenz (<0,7) zur Überprüfung markieren. Das System bildet die Begriffsnamen nach der Auswahl auf IDs ab.
Lesen Sie auch: KI-Dokumentenverarbeitung in Drupal: Technische Fallstudie mit 95 % Genauigkeit
Wie optimiert man Prompts für eine höhere Genauigkeit?
Selbst mit der richtigen Struktur und den richtigen Taxonomien erfordert das Erreichen hoher Genauigkeit eine kontinuierliche Verfeinerung. So verbessern Sie Ihre Prompts systematisch auf der Grundlage realer Leistungsdaten.
Iterativer Verfeinerungsprozess
Erwarten Sie keine perfekten Prompts beim ersten Versuch. Iterieren Sie.
Verwenden Sie echte Dokumente, keine synthetischen Beispiele.
Wenn Sie unsicher sind, welcher Ansatz besser ist, testen Sie beide:
Prompt A: Kompakt
Categorize using these taxonomies:
[taxonomies]
Document:
[document]
Return JSON:
[schema]
Prompt B: Ausführlich
You are an expert legal document analyst. Your task is to carefully read
the provided document and categorize it according to the taxonomies below.
Instructions:
- Read the document thoroughly
- Identify the document type
- Determine the issuing organization
- Extract all relevant subject areas
[... detaillierte Anweisungen ...]
Taxonomies:
[taxonomies]
Document:
[document]
Please return your analysis as JSON:
[schema]
Wie extrahiert man rechtliche Verpflichtungen aus Dokumenten?
Die Extraktion von Verpflichtungen ist schwieriger als die Kategorisierung, weil:
- Implizite Verpflichtungen – nicht immer explizit formuliert
- Bedingte Verpflichtungen – „wenn X, dann muss Y"
- Geltungsbereich-Identifikation – wer muss die Vorschriften einhalten?
- Fristenextraktion – wann muss die Einhaltung erfolgen?
Implizite Verpflichtungen identifizieren
Explizite Verpflichtung:
„All banks must submit quarterly reports to the FCA."
Implizite Verpflichtung:
„The Authority expects quarterly reporting from regulated entities."
„Expects" impliziert eine Verpflichtung im regulatorischen Kontext.
Prompt-Anleitung:
Extract legal obligations including:
- MUST/SHALL/REQUIRED (explicit)
- SHOULD/EXPECTED/RECOMMENDED (strong guidance, often treated as obligations)
- Implicit requirements from regulatory context
For each obligation, extract:
- What action is required
- Who must perform it (affected parties)
- When it must be done (deadline/frequency)
- What happens if not done (consequences, if stated)
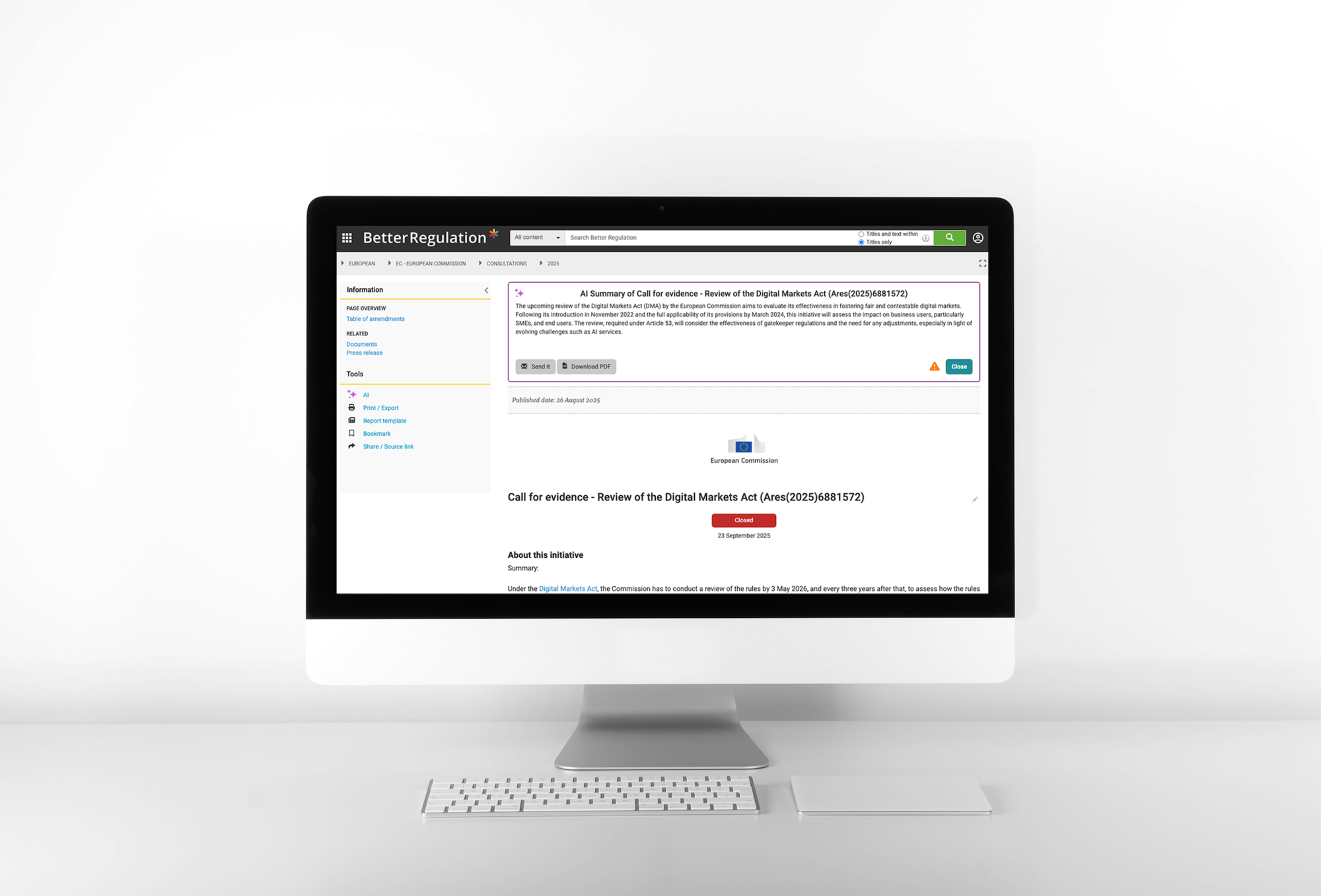
Eine KI-basierte Lösung für automatisierte Dokumentzusammenfassungen und Verpflichtungsextraktion bei Better Regulation
Sehen Sie, wie wir KI-Dokumentzusammenfassungen generieren und Verpflichtungen extrahieren →
Fehlende Informationen
Was, wenn das Dokument die erwarteten Informationen nicht enthält?
Prompt-Anleitung:
If information cannot be determined from document:
- Return empty array [] for that field
- Do NOT guess or invent information
- Do NOT return null or undefined
Example:
{
"source_url": "" // Not found in document
}
NOT:
{
"source_url": "https://www.example.com" // Don't make up URLs
}
Mehrere gültige Interpretationen
Manche Dokumente passen legitimerweise in mehrere Kategorien.
Beispiel: Ein Dokument behandelt sowohl Bankenregulierung als auch Datenschutz.
Prompt-Strategie:
document_area is a multi-value field.
If document covers multiple areas, include ALL relevant areas:
{
"document_area": ["Banking Regulation", "Data Protection"]
}
Prefer including all relevant areas over forcing single selection.
The system will map these term names to their corresponding IDs automatically.
Lesen Sie auch: KI-Automatoren in Drupal: Wie orchestriert man mehrstufige KI-Workflows?
Codebeispiele und Prompt-Vorlagen
Nachdem wir die Techniken behandelt haben, finden Sie hier produktionsreife Prompt-Vorlagen, die Sie für Ihre eigenen Projekte zur Extraktion juristischer Dokumente anpassen können. Diese Vorlagen integrieren alle oben besprochenen Strategien.
Vollständiger Kategorisierungs-Prompt
You are analyzing a UK/Ireland legal or regulatory document.
Extract and categorize using these exact taxonomies.
CRITICAL RULES:
- Use ONLY taxonomy term names from lists below (return term names as strings)
- Return valid JSON in specified format
- Match by semantic meaning, not just keywords
- If multiple terms apply, include all relevant ones
- If uncertain, return empty array []
- The system will automatically map term names to term IDs
### DOCUMENT TYPE TAXONOMY:
- Statute
- Regulation
- Guidance Note
- Code of Practice
- Case Law
### ORGANIZATION TAXONOMY:
- Financial Conduct Authority
- Bank of England
- Competition and Markets Authority
- Information Commissioner's Office
- HM Treasury
[... vollständige Liste ...]
### DOCUMENT AREA TAXONOMY:
- Banking and Finance
- Consumer Credit
- Banking Regulation
- Payment Services
- Data Protection
- Competition Law
[... vollständige Liste ...]
### DOCUMENT TO ANALYZE:
{{ document_text }}
Return JSON with taxonomy term names (strings), not IDs.
Example:
{
"document_type": ["Guidance Note"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Consumer Credit", "Banking Regulation"]
}
Prompt zur Verpflichtungsextraktion
Extract legal obligations from this document.
An obligation is a requirement that specific parties must fulfill.
For each obligation, identify:
- What action is required
- Who must perform it (affected parties/license types)
- When (deadline or frequency)
Include:
- Explicit obligations (MUST, SHALL, REQUIRED)
- Strong guidance (SHOULD, EXPECTED, RECOMMENDED)
- Implicit requirements from regulatory context
### LICENSE TYPES:
- Consumer Credit Lenders
- Consumer Credit Hirers
- Payment Services Providers
[... vollständige Liste ...]
Return taxonomy term names (strings) for license types. The system will map these names to term IDs automatically.
### DOCUMENT:
{{ document_text }}
Prompt Engineering für Datenextraktion – Fazit
Effektives Prompt Engineering für die Extraktion juristischer Dokumente erfordert:
- Taxonomie-Injektion – vollständige Taxonomielisten bereitstellen (nur Begriffsnamen; das System bildet Namen auf IDs ab)
- JSON-Schema-Erzwingung – exakte Ausgabestruktur definieren
- Semantisches Matching – das Bedeutungsverständnis der KI nutzen
- Iterative Verfeinerung – testen, messen, verbessern
- Fehlermusteranalyse – spezifische Fehler systematisch beheben
- Randfallbehandlung – für Größenlimits, fehlende Daten und Mehrdeutigkeit planen
BetterRegulations Ergebnisse:
- Über 95 % Feldgenauigkeit
- Weniger als 5 % Redaktionskorrekturrate
- 2 Monate iterative Verbesserung (75 % → 95 %)
- Monatliche Prompt-Verfeinerung basierend auf Fehleranalyse
Die wichtigste Erkenntnis: Prompt Engineering ist kein einmaliges Unterfangen. Es ist eine kontinuierliche Verbesserung basierend auf realer Leistung.
Beginnen Sie einfach. Testen Sie gründlich. Verfeinern Sie systematisch. Ihre Prompts werden sich mit der Zeit verbessern.
Benötigen Sie Experten für Prompt Engineering in Ihrem KI-Projekt?
Dieser Leitfaden basiert auf unserer produktiven Prompt-Engineering-Arbeit für BetterRegulation, bei der wir über zwei Monate hinweg Prompts entwickelt und verfeinert haben, um eine Genauigkeit von über 95 % bei der Extraktion juristischer Dokumente zu erreichen. Der Schlüssel war systematische Iteration: Beginn mit einfachen Prompts bei 75 % Genauigkeit, Analyse von Fehlermustern, Verfeinerung der Anweisungen und schrittweise Verbesserung bis zur produktionsreifen Leistung. Dieser iterative Ansatz des Prompt Engineerings verwandelte einen Prototyp in ein zuverlässiges System, das monatlich Tausende von Dokumenten verarbeitet.
Die Entwicklung effektiver Prompts erfordert sowohl technisches Fachwissen als auch Domänenwissen. Unser Team ist auf Prompt Engineering für komplexe Datenextraktionsaufgaben spezialisiert. Wir übernehmen den gesamten Zyklus: initiales Prompt-Design, Taxonomie-Integration, JSON-Schema-Definition, iteratives Testen, Fehleranalyse und kontinuierliche Optimierung. Besuchen Sie unsere Generative-KI-Entwicklungsdienstleistungen, um zu erfahren, wie wir Ihnen helfen können.










