

AI document processing is transforming content management in Drupal. Through integration with AI Automators, Unstructured.io, and GPT models, editorial teams can automate tedious tasks like metadata extraction, taxonomy matching, and summary generation. This case study reveals how BetterRegulation implemented AI document processing in their Drupal 11 platform, achieving 95%+ accuracy and 50% editorial time savings.
In this article:
- Introduction: why use AI document processing in Drupal?
- Project context: what problem does AI document processing solve?
- How does AI document processing work in Drupal?
- How to implement AI document processing in Drupal
- What are the key technical challenges in AI document processing?
- How to ensure production reliability for AI document processing?
- Performance and cost optimization for AI document processing
- What lessons did we learn from implementing AI document processing?
- What tools and resources do you need for AI document processing?
- Ready to implement AI document processing in Drupal?
Introduction: why use AI document processing in Drupal?
Drupal has long been a powerhouse for content management, particularly for complex, structured content. But as content volumes grow and user expectations evolve, manual document processing becomes a bottleneck.
AI document processing automates the extraction, classification, and organization of information from documents at scale. AI with Drupal makes this possible for content management workflows. Imagine:
- Documents auto-categorized across 15 metadata fields with 95% accuracy.
- Summaries generated automatically for every piece of content.
- Entity references created intelligently based on semantic understanding.
- Editorial teams freed from tedious data entry to focus on strategy.
This isn’t aspirational—it’s production reality. BetterRegulation, a legal compliance platform running on Drupal 11, added AI capabilities to their existing system and now processes 200+ complex legal documents monthly, achieving:
- 50% time savings in document processing
- 1 FTE freed for higher-value work
- >95% accuracy in auto-categorization
- <12 month ROI
This article shares the technical architecture, key decisions, and lessons learned from a real-world implementation that processes 200+ legal documents monthly.
Key insights you’ll gain:
- Architecture decisions for automated document processing: why AI Automators, Unstructured.io, and GPT-4o-mini.
- How to achieve 95%+ accuracy in automated taxonomy matching.
- Real-world cost optimization strategies (£2,000+/year savings).
- Production challenges and solutions (15-minute delay mechanism, token limits).
- When to use AI Automators vs. custom code for document automation.
Who this is for: Technical leads and developers evaluating AI document processing integration for existing Drupal platforms.
Project context: what problem does AI document processing solve?
BetterRegulation already had a mature Drupal 11 platform managing thousands of legal documents. The challenge was to integrate AI document processing capabilities into their existing workflow without disrupting editors or requiring a complete rebuild.
The goal was simple but ambitious: automate document processing with AI to read PDFs, extract metadata, match taxonomies, and generate summaries—while editors focus on quality control and strategic content curation.
Two main features were developed:
1. Auto-fill Document Fields (Know How content type) - upload a PDF, click “Generate with AI,” and watch 15+ fields populate automatically with document type, organization, year, legislation references, and more. Processing happens in real-time (1-2 minutes) so editors can immediately review and adjust the populated fields.
2. AI-Generated Summaries (General Consultation, Station, Know How content types) - automatically create three types of summaries:
- Detailed summary (~200 words) - comprehensive overview.
- Short summary (~50 words) - one-paragraph synopsis.
- Obligations summary - extracted legal obligations and regulatory requirements.
Summary generation runs in the background with a 15-minute delay to avoid reprocessing during rapid edits.
The implementation needed to be:
- Non-disruptive: work within existing content types and workflows.
- Configurable: allow prompt and taxonomy updates without code deployment.
- Reliable: handle edge cases like 350-page documents and complex legal terminology.
- Cost-effective: process 200+ documents monthly without breaking the budget.
This guide shows how we achieved all of this using Drupal’s AI module ecosystem.
How does AI document processing work in Drupal?
Understanding the technical stack is crucial for evaluating this approach for your own projects. BetterRegulation’s AI document processing implementation combines five core components that work together to process documents from PDF upload to populated content fields.
What technology stack powers AI document processing?
BetterRegulation’s AI implementation uses five key components:
1. Auto-fill document fields (Generate with AI button)
┌─────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Content creation form │ │
│ │ [ Upload PDF ] [ Generate with AI button ] │ │
│ └───────────┬───────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ AI Automators │ │
│ │ (workflow engine) │ │
│ │ + Batch API │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Unstructured.io │ │
│ │ (PDF→clean text) │ │
│ │ Self-hosted pod │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (AI processing) │ │
│ │ OpenAI API │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ JSON response (populated fields) │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ AI Automators │ │
│ │ (parse & populate) │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Fields populated │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Content creation form │ │
│ │ [ Fields auto-filled, ready for review ] │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (logging) │ │
│ └───────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
2. AI-generated summaries (background processing)
┌─────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ │
│ Document save │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ RabbitMQ queue │ │
│ │ (15-minute delay) │ │
│ └───────┬──────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ AI Automators │ │
│ │ (workflow engine) │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (summary gen) │ │
│ │ OpenAI API │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Generated summaries │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ AI Automators │ │
│ │ (save to fields) │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Document updated │ │
│ │ [ Summaries saved to content fields ] │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (logging) │ │
│ └───────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
What does each component do in the AI document processing pipeline?
Drupal 11 serves as the foundation of the entire system, providing the content management platform, entity structure, and user interface. It orchestrates the workflow and stores all document data, acting as the central hub where editors interact with content and where the AI-processed results ultimately live.
Drupal AI Automators is the contrib module that bridges Drupal and AI services. Rather than building custom integration code, this module provides a configuration-based approach to defining AI workflows. It manages prompts, handles responses from multiple AI providers (OpenAI, Anthropic, etc.), and orchestrates multi-step processes through an intuitive admin interface. This means creating and modifying AI workflows becomes a configuration task rather than a development project. For more examples of AI automation in Drupal, see how to generate image alt text and content strategy with AI modules.
Unstructured.io runs on a self-hosted pod and handles the critical first step: converting messy PDF documents into clean, structured text. It analyzes document layouts, preserves structure, filters out artifacts like headers and page numbers, and even handles OCR for scanned documents. The result is clean text that’s optimized for AI processing, which is essential for accurate categorization and metadata extraction.
GPT-4o-mini powers the AI analysis through OpenAI’s API. Once it receives clean text from Unstructured.io, it performs document analysis, matches content against the BetterRegulation taxonomy, extracts metadata, and generates summaries. The model returns structured JSON responses that Drupal Automators can parse and automatically populate into the appropriate content fields.
RabbitMQ manages background job processing, particularly for the time-intensive summary generation. When a user saves or edits a document, summary creation is automatically queued with a 15-minute delay. This design decision came from a practical need: editors often make multiple quick edits to documents, and processing summaries after each save would waste API costs and processing time. The 15-minute delay allows editors to finalize their changes before AI processing begins. This prevents redundant processing and enables the system to scale horizontally by processing multiple summaries across different workers.
Watchdog, Drupal’s core logging system, captures every step of the process. From PDF upload to AI response, every action, error, and performance metric is logged. This comprehensive logging proved essential during development for debugging workflows and continues to be valuable for monitoring the system’s health in production.
Why choose this technology stack for AI document processing?
BetterRegulation already had Drupal 11 as their content management platform when they decided to add AI capabilities. The challenge was how to integrate AI into their existing workflow without disrupting editors or requiring major architectural changes.
Choosing AI Automators over custom code saved weeks of development time. Instead of writing boilerplate integration code for OpenAI’s API, managing prompt templates, and building admin interfaces, we configured workflows through a GUI. This configuration-over-code approach means future modifications—like adding new AI steps or switching providers—can be done without deploying new code. The module is community-maintained, so improvements and security updates come from the broader Drupal ecosystem.
For PDF processing, Unstructured.io proved superior to direct extraction in every meaningful metric. Initial tests with standard PDF libraries showed 75% extraction quality and produced text filled with page numbers, headers, and formatting artifacts. Unstructured.io achieved 94% quality and produced clean text that saved 30% on AI tokens. Self-hosting the service on their existing infrastructure eliminated per-document processing fees, making it economically viable even for thousands of documents.
The selection of GPT-4o-mini over GPT-4 came down to economics and sufficiency. While GPT-4 is more capable, GPT-4o-mini proved entirely sufficient for taxonomy matching and metadata extraction. At 10x lower cost and with a 128K context window (enough for 350-page documents), it offered the perfect balance of capability and affordability. The faster processing speed was a bonus that improved the editor experience.
For a detailed comparison of different AI integration approaches, read LangChain vs LangGraph vs Raw OpenAI: how to choose your RAG stack.
How to implement AI document processing in Drupal
With the architecture established, let’s examine how these components were actually built and configured. The implementation focused on leveraging existing Drupal modules rather than building custom code from scratch.
The build approach
Rather than building custom AI integration code from scratch, we leveraged Drupal’s AI Automators module—a configuration-based approach that saved weeks of development time and provided enterprise-grade reliability out of the box.
Core components built
1. PDF text extraction service
We created a custom Drupal service that sends PDFs to the self-hosted Unstructured.io instance and receives clean, structured text. The service filters out headers, footers, page numbers, and preserves document structure—critical for accurate AI analysis.
Key implementation decision: Filter only Title, NarrativeText, and ListItem elements from Unstructured.io’s response. This removes noise while preserving the document’s logical structure.
2. Automator workflow configuration
Using AI Automators’ admin interface (/admin/config/ai/automator_chain_types/manage/summary/automator_chain), we configured a two-step workflow:
- Step 1: Extract text from PDF → store in temp field
- Step 2: Send text + taxonomies to GPT-4o-mini → receive JSON response
No custom code needed for the AI API integration—AI Automators handles provider management, retry logic, and error handling.
3. Prompt engineering for taxonomy matching
The secret to 95%+ accuracy: inject complete taxonomy lists directly into the prompt.
The prompt structure looks like this:
You are analyzing a legal document. Extract and categorize using these taxonomies:
### DOCUMENT TYPE TAXONOMY:
- Statute (ID: 12)
- Regulation (ID: 13)
- Guidance Note (ID: 14)
[... complete list with IDs ...]
### ORGANIZATION TAXONOMY:
- Financial Conduct Authority (ID: 23)
- Bank of England (ID: 24)
[... complete list with IDs ...]
[Document text here]
Return JSON:
{
"document_type": ["Statute", "Regulation"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Data Protection", "Financial Services", "GDPR"],
...
}
Critical decisions:
- Dynamic taxonomy loading: PHP code queries Drupal taxonomies and builds the prompt context on-the-fly. Changes to taxonomies don’t require prompt updates.
- AI returns taxonomy names: AI returns taxonomy term names (e.g.,
["Data Protection", "Financial Services", "GDPR"]), not IDs. The system then performs a lookup to match these names to term IDs in Drupal’s taxonomy system. This approach leverages AI’s semantic understanding while maintaining precise entity references. - Name-to-ID mapping: after AI returns term names, the system searches the taxonomy vocabulary to find matching terms and retrieves their IDs. For example:
"Data Protection"→ finds term ID42,"Financial Services"→ finds term ID87,"GDPR"→ finds term ID156. The document is then assigned the array of IDs:[42, 87, 156]. - Semantic matching: AI understands “consumer lending” = “Consumer Credit Lenders” even without exact keyword matches. The name-based approach allows AI to use its semantic understanding to match concepts, while the system ensures accuracy through exact term name matching in the taxonomy lookup.
Token cost: adding taxonomies increases prompt size by ~5,000 tokens per request, costing £0.03 extra per document. The accuracy improvement (75% → 95%) saves 12+ minutes of manual correction per document, making it a 70x ROI.
4. “Generate with AI” Button
We added an AJAX-enabled button to the content edit form that triggers the processing workflow and populates fields in real-time. The editor sees the form fields fill automatically and can review/adjust before saving.
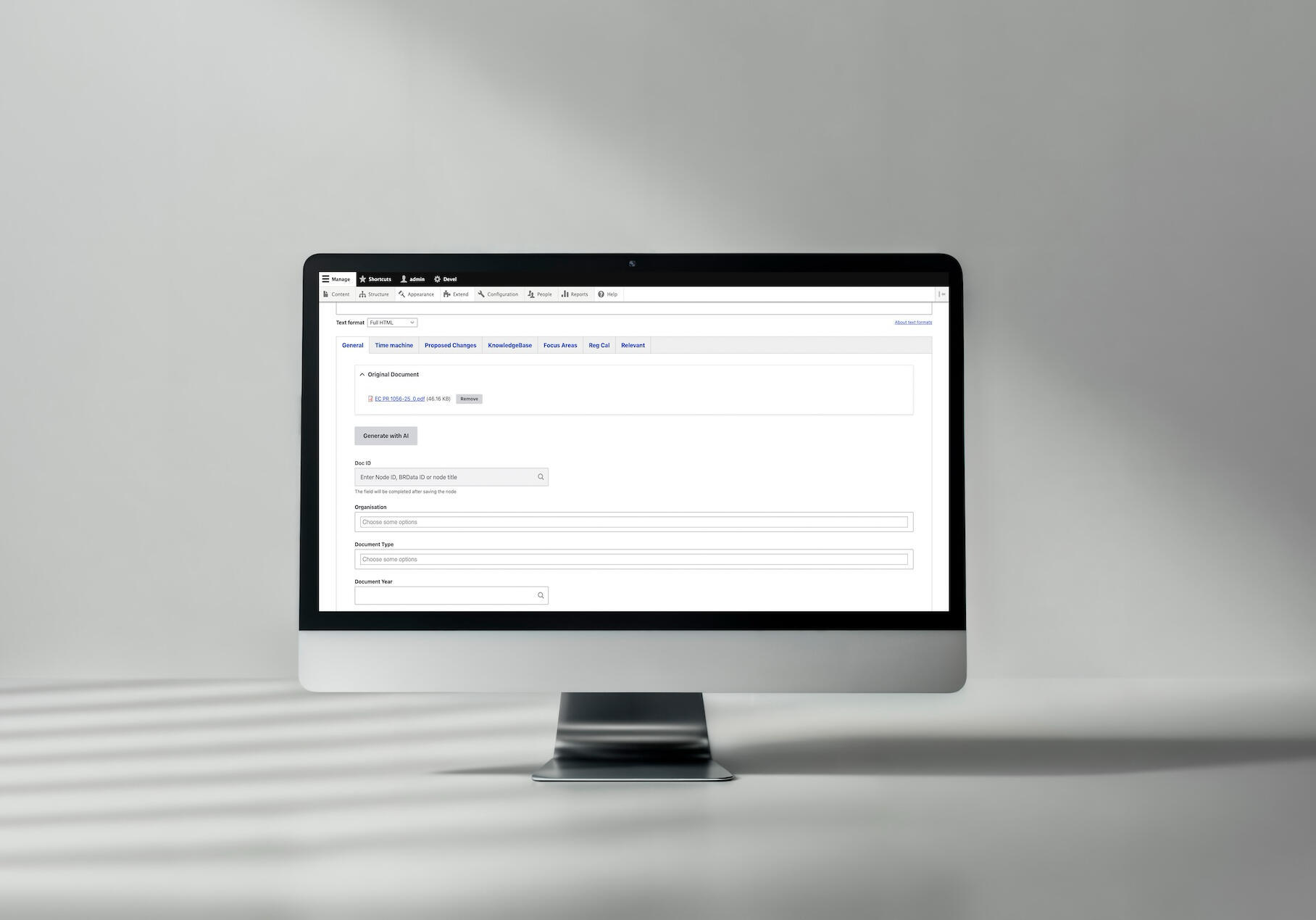
An example of AI document processing we implemented for Better Regulation
Read the full AI-Powered Document Categorization case study here →
What are the key technical challenges in AI document processing?
Every AI integration faces unique challenges. Here are the three most significant technical hurdles BetterRegulation encountered and how they solved them.
Challenge 1: Automated PDF extraction for document processing
Legal documents are notoriously messy:
- Multi-column layouts
- Headers/footers on every page
- Page numbers embedded mid-sentence
- Tables and footnotes
Our solution: Unstructured.io’s hi_res strategy with element filtering for clean document processing.
Results:
- 94% extraction quality (vs. 75% with standard PDF libraries)
- 30% token savings by filtering out artifacts
- Clean, structured text that AI can accurately parse
Key implementation: only include Title, NarrativeText, and ListItem elements. Ignore headers, footers, and page numbers.
Challenge 2: Token limit with large documents
Some documents are 350+ pages, exceeding GPT-4o-mini’s 128K context window.
Our solution: graceful degradation strategy.
- Calculate estimated tokens before sending (1 token ≈ 4 characters)
- If >120K tokens: extract only titles and section headings
- Add admin field for manually-condensed PDFs for edge cases
Trade-off: slightly lower accuracy on mega-documents (90% vs. 95%), but avoids complete failure.
Challenge 3: Semantic taxonomy matching
The problem: document says “consumer lending practices.” Taxonomy term is “Consumer Credit Lenders and Hirers.” Traditional keyword matching fails.
Our solution: leverage LLM’s semantic understanding.
- AI understands “consumer lending” = “Consumer Credit”
- Recognizes acronyms (FCA = Financial Conduct Authority)
- Uses context to disambiguate (ICO = data regulator, not cryptocurrency)
Why name-based matching works: AI returns term names like ["Consumer Credit", "Data Protection"], which the system then maps to term IDs (e.g., [35, 42]) through taxonomy lookup. This approach combines AI’s semantic understanding with precise entity references—the AI can match concepts semantically, while the system ensures accuracy by finding exact term matches in the taxonomy vocabulary.
Read also: How We Improved RAG Chatbot Accuracy by 40% with Document Grading →
How to ensure production reliability for AI document processing?
Moving from proof-of-concept to production requires robust error handling and monitoring. BetterRegulation built comprehensive safeguards to ensure the system remains stable under real-world conditions.
How do you handle errors in AI document processing?
Comprehensive logging: every step logged to Drupal’s Watchdog system—from PDF upload to AI response. Essential for debugging and monitoring.
Retry logic: transient API failures (rate limits, timeouts) trigger automatic retry with exponential backoff (2s, 4s, 8s delays).
Graceful failure: if processing fails, the document remains editable with clear error messages. Editors can retry or fill fields manually.
Monitoring dashboard
Custom admin view at /admin/content/ai-processing tracks:
- Success/failure rates
- Processing times
- API costs
- Editor correction frequency (accuracy metric)
Weekly review: BetterRegulation’s team checks dashboard weekly to spot issues early and refine prompts based on error patterns.
Performance and cost optimization for AI document processing
AI API costs can quickly spiral out of control without proper optimization. BetterRegulation implemented several strategies to minimize document processing expenses while maintaining performance and user experience.
Background processing with 15-minute delay
The problem: editors often save documents multiple times in quick succession while making edits. Triggering expensive AI summary generation on every save wastes money.
Our solution: summary generation queued to RabbitMQ with 15-minute delay.
- Editor saves document → queued for processing in 15 minutes
- If editor saves again within 15 minutes → delay resets
- After 15 minutes of no changes → summaries generated once
Impact: eliminates 60-70% of redundant API calls during rapid editing sessions. For more strategies on reducing AI API costs, see how intelligent routing cut AI API costs by 95%.
How does caching reduce AI document processing costs?
Extracted PDF text cached for 7 days. If prompt needs refinement, reprocessing uses cached text instead of re-extracting from PDF.
Savings: ~£0.05 per reprocess (Unstructured.io call eliminated).
Read also: How to Speed Up AI Chatbot Responses with Intelligent Caching →
What are the costs of AI document processing?
Monthly processing (200 documents):
- GPT-4o-mini API: ~£42/month (~£0.21 per document)
- Unstructured.io: £0 (self-hosted)
- Total: £42/month
Optimization savings compared to GPT-4:
- GPT-4 would cost: ~£420/month
- Savings: £378/month (90% reduction)
Cost per time saved:
- 50% time savings = 50 hours/month saved
- £42/month ÷ 50 hours = £0.84 per hour saved
- Typical editor cost: £15-25/hour
- ROI: 18-30x return
What security considerations should you address in AI document processing?
Data privacy: PDFs sent to OpenAI API. For sensitive documents, consider:
- Self-hosted LLMs (Llama, Mistral via Ollama)
- Data processing agreements with OpenAI
- Text anonymization (scrub PII before sending)
API key security: stored in Drupal config system, not in code. Admin-only access.
What lessons did we learn from implementing AI document processing?
After months of development and production use, BetterRegulation’s team identified seven critical lessons that would benefit anyone building similar AI integrations. These insights go beyond technical documentation to capture hard-won practical knowledge.
1. Test with real documents
Don’t: test with sample/synthetic PDFs.
Do: use actual documents from your domain.
Why: synthetic test documents are clean, well-formatted, and predictable. Real-world documents are messy, inconsistent, and full of edge cases that will break your carefully crafted prompts.
What BetterRegulation discovered during real-world testing:
- Scanned PDFs with poor OCR: PDFs had garbled text like “Cong umer Cred it Act” that confused taxonomy matching. Solution: Added text normalization to handle OCR artifacts.
- Multi-language documents: EU regulations mixing English and Latin legal terms. The AI initially failed to categorize these correctly until prompts were adjusted to handle mixed-language content.
- Inconsistent naming: same organization referenced as “FCA,” “Financial Conduct Authority,” “the Authority,” and “the FCA” within one document. Semantic matching handled this, but validation was needed.
- 350+ page monsters: only discovered the token limit issue when testing with actual regulatory compendia. Led to the title-extraction fallback strategy.
BetterRegulation tested with real legal PDFs covering 5+ years of publications before launch. The first 20 test documents revealed more issues than 6 months of development with synthetic samples would have.
2. Human-in-the-loop is essential
Don’t: fully automate without review.
Do: AI populates, humans review and approve.
Why: no AI system is perfect, and errors in a legal compliance platform have real consequences. More importantly, AI errors aren’t random—they tend to cluster around the most complex, ambiguous, or unusual documents that need the most careful attention.
The human-in-the-loop approach delivers multiple benefits:
- Quality assurance: legal editors catch AI mistakes before they affect end users. In a compliance platform, incorrect categorization could mean critical regulatory guidance isn’t found when needed.
- Trust building: editors trust the system because they see how it works and can correct it. Positioning AI as an “assistant” rather than a replacement reduces organizational resistance and increases adoption.
- Continuous improvement: editor corrections reveal patterns in AI behavior. By tracking which fields get corrected most frequently, you can identify where prompts need refinement or where taxonomies need clarification.
- Domain expertise capture: when editors make corrections, they’re often applying nuanced domain knowledge that wasn’t captured in the original prompts. These corrections can be analyzed to improve the system over time.
- Efficiency balance: AI handles the tedious, repetitive work of reading documents and extracting basic metadata. Humans focus on reviewing, adjusting edge cases, and applying judgment to ambiguous situations. This division of labor is more efficient than either approach alone.
The result: significant time savings while maintaining quality standards. Editors work faster because AI does the initial heavy lifting, and final output is more consistent because AI doesn’t get tired or make transcription errors.
3. Iterate on prompts
Don’t: write prompt once and move on.
Do: review errors and refine prompts.
Why: your first prompt will be good but not great. AI behavior is emergent and often surprising—you won’t predict all failure modes until you process hundreds of real documents.
The lesson: improvement came from analyzing actual mistakes, not theorizing about improvements. Track corrections, find patterns, refine prompts.
4. Edge cases are inevitable
Don’t: assume AI will handle everything.
Do: plan for edge cases upfront and build graceful fallbacks.
Why: no matter how good your AI, some documents will break the system. The question isn’t “if” but “when” and “how often.”
BetterRegulation’s edge case catalog:
- Token limit breakers: very large regulatory compendia that exceed GPT-4o-mini’s 128K context window. Fallback: Extract and process only titles and section headings—lower accuracy but better than complete failure.
- Scanned PDF disasters: older legislation scanned with poor OCR producing garbled text. Fallback: Admin field to upload manually-typed condensed version or flag for human processing.
- Genuinely ambiguous documents: some documents legitimately span multiple categories and even legal experts disagree on proper categorization. Fallback: AI returns multiple options; editor makes final call.
- Missing metadata: some PDFs simply don’t contain expected information like year, source URL, or other fields. Fallback: Return empty values rather than hallucinating; editor fills manually.
The pragmatic approach: accept that some documents need special handling. Build monitoring to identify these cases quickly and provide editors with clear workflows for handling them. Trying to achieve 100% automation would cost significantly more development time for marginal gains.
5. Monitoring is critical
Don’t: deploy and forget.
Do: build comprehensive monitoring from day one.
Why: AI systems can degrade silently. Model updates, taxonomy changes, or evolving document formats can break previously working processes. Without monitoring, you won’t notice until users complain.
BetterRegulation’s monitoring approach tracks:
- Success/failure rates: overall processing success metrics. Sudden drops indicate system issues.
- Processing time distribution: track performance over time. Significant increases indicate API slowdowns or token limit issues.
- Per-field accuracy: monitor which fields editors correct most frequently. Reveals where prompts need improvement.
- API cost trends: track spending patterns. Spikes indicate issues like duplicate processing, failed delay logic, or unexpected volume increases.
- Error patterns: categorize failures by type. Each pattern gets specific remediation strategies.
Value of early detection: monitoring provides early warning when external services change behavior or when document processing patterns shift, enabling quick adaptation before users are impacted.
6. Cost optimization matters
Don’t: default to the most expensive AI model.
Do: test cheaper models first; optimize based on actual costs.
Why: “use the best AI” sounds smart but wastes money. For many tasks, cheaper models perform just as well. BetterRegulation’s cost optimization journey delivered substantial savings compared to the naive approach of using premium models for everything.
Decision 1: GPT-4o-mini vs GPT-4
- Initial assumption: “GPT-4 is better, so use GPT-4.”
- Reality check: tested both models on 50 documents. GPT-4: 96% accuracy. GPT-4o-mini: 95% accuracy.
- Cost analysis: GPT-4: £1.05/document. GPT-4o-mini: £0.21/document.
- Decision: 1% accuracy gain not worth 5x cost increase. Chose GPT-4o-mini.
- Annual savings: £2,016 (200 docs/month × 12 months × £0.84 savings per doc)
Decision 2: Self-hosted Unstructured.io
- SaaS option: £0.10-0.20 per document processing
- Self-hosted option: run on existing Kubernetes cluster, effectively free (marginal compute cost ~£5/month)
- Decision: self-host on existing infrastructure
- Annual savings: £240-480 (200 docs/month × 12 months × £0.10-0.20)
7. Start simple, add complexity
Don’t: try to build the complete vision on day one.
Do: launch with minimum viable AI, iterate based on real usage.
Why: you don’t know what will work until real users interact with real data. Starting complex means longer development, more bugs, and wasted effort on features users might not need.
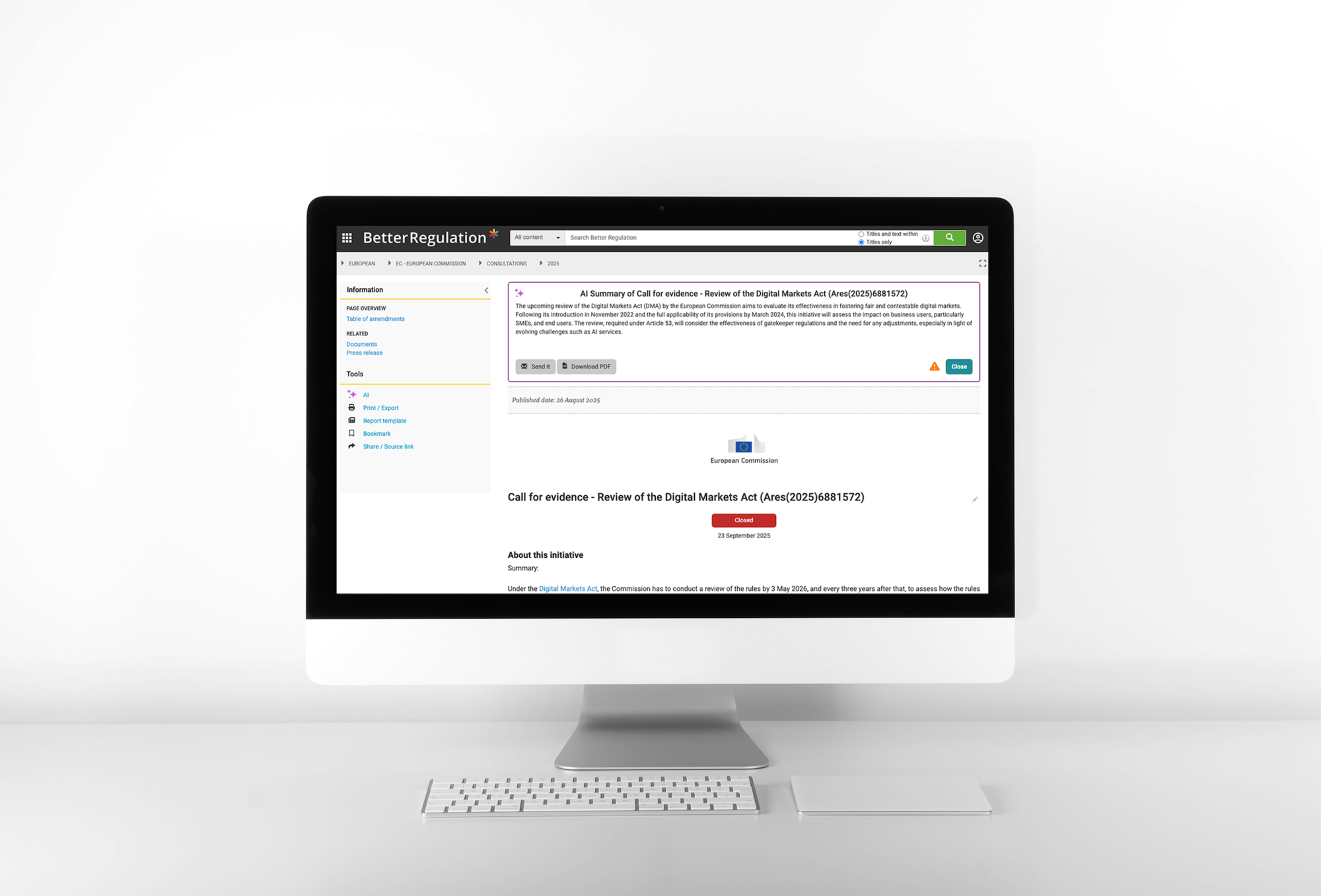
An example of a project in which we used AI and Drupal to implement automated summaries for complex legal documents
Read the full AI-Powered Document Summaries case study here →
What tools and resources do you need for AI document processing?
Ready to implement AI document processing in your Drupal project? Here are the essential modules, services, and resources you’ll need to get started.
Drupal modules
Required:
- AI module - core AI integration framework for Drupal
- AI Automators - submodule providing workflow engine for multi-step AI processes
Helpful:
- Queue UI - manage background queues
- Unstructured module - Drupal integration for Unstructured.io
External services
AI APIs:
- OpenAI API - GPT models (recommended: GPT-4o-mini)
- Anthropic Claude - alternative LLM provider
PDF processing:
- Unstructured.io - best PDF extraction (self-host or SaaS)
- Unstructured GitHub - open source
Infrastructure
Docker/Kubernetes:
- Docker Compose - local development
- Kubernetes - production deployment
Message queues:
- RabbitMQ - reliable message queue
- Drupal Queue API - built-in queues
Ready to implement AI document processing in Drupal?
This case study is based on our real production implementation for BetterRegulation, where we integrated AI Automators, Unstructured.io, and GPT-4o-mini to automate document processing for 200+ legal documents monthly with 95%+ accuracy and 50% time savings. The system has been running in production for months, delivering consistent results and ROI.
Interested in building AI document processing for your Drupal site? Our team specializes in creating production-grade AI document processing solutions that balance accuracy, performance, and cost-effectiveness. We handle everything from architecture design and prompt engineering to deployment and optimization. Visit our generative AI development services to discover how we can help you automate document processing and free your editorial team to focus on strategic work.










