Catégorisation de documents par IA : comment BetterRegulation a économisé 50% du temps éditorial
Nous avons construit un moteur de catégorisation de documents alimenté par l'IA pour BetterRegulation qui réduit de moitié l'effort éditorial en automatisant l'extraction de champs de documents juridiques et leur classification. Alimenté par Drupal Automators et l'IA, le système transforme des heures de balisage manuel en un flux de travail rapide et fiable qui garde le contenu juridique complexe parfaitement structuré et recherchable.
Résultats clés
![]() Gain de temps de 50%
Gain de temps de 50%
Temps de traitement des documents réduit de moitié.
![]() Économie équivalente à 1 ETP
Économie équivalente à 1 ETP
Libération de la capacité éditoriale pour la croissance.
![]() Temps de traitement de 10s à 2min
Temps de traitement de 10s à 2min
Traitement IA contre 15 minutes à plusieurs heures manuellement.
![]() Gère 2 à 350 pages
Gère 2 à 350 pages
Gère des documents de toutes tailles.
![]() Très haute précision
Très haute précision
Des corrections minimales sont nécessaires, <5% des
champs nécessitent un ajustement.
![]() Réduction de la charge cognitive
Réduction de la charge cognitive
L'IA supprime le besoin de lire le document en entier.
À propos de BetterRegulation
Défi: le goulot d'étranglement éditorial

Traitement manuel des documents à grande échelle
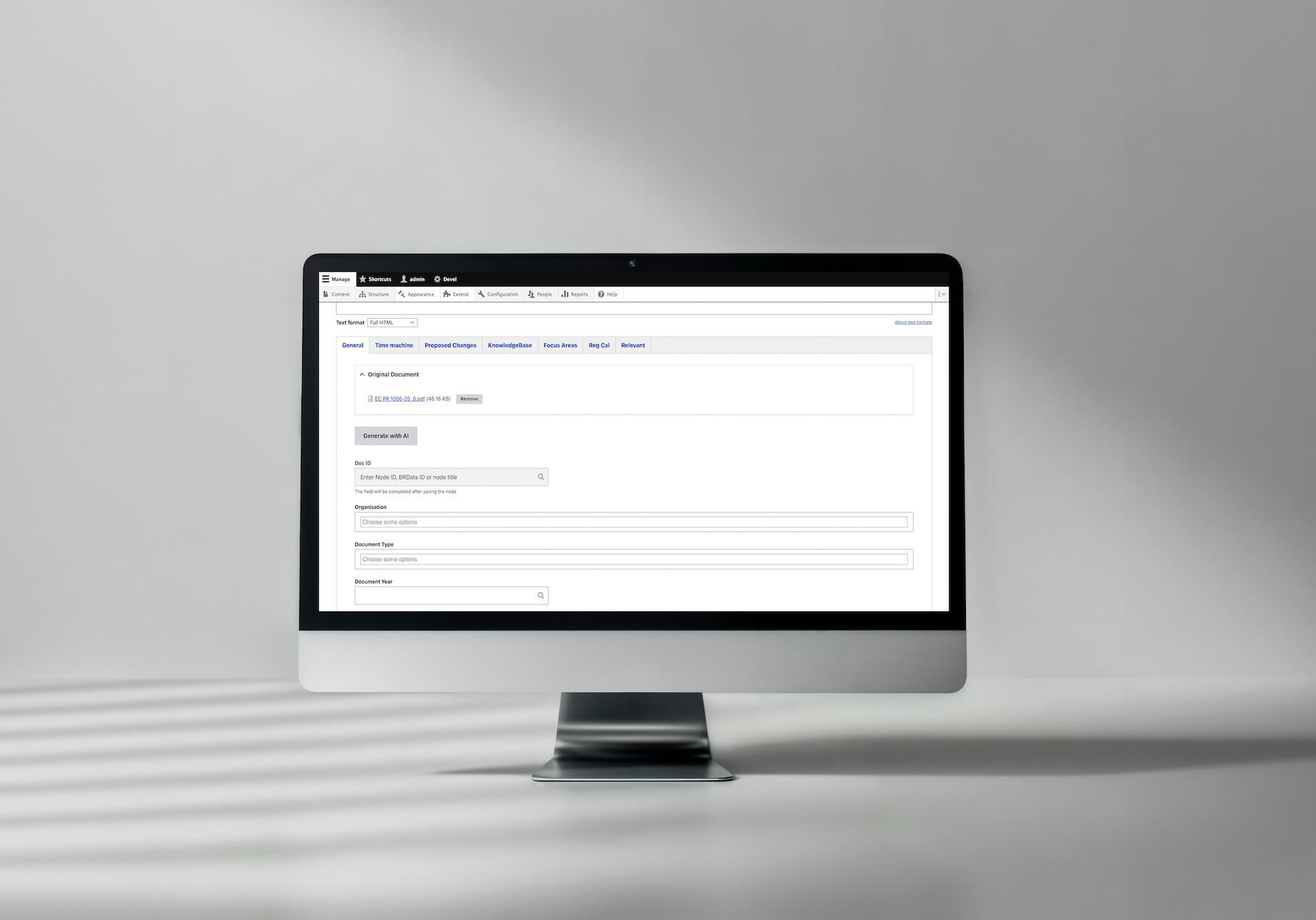
Traiter des documents juridiques pour une plateforme de conformité nécessite une attention méticuleuse aux détails. Chaque statut, réglementation ou document d'orientation doit être lu, catégorisé et étiqueté dans environ 15 domaines différents – du type de document et de juridiction à l'année d'adoption et à l'organisation.
Pour l'équipe de rédaction de BetterRegulation, ce processus manuel a créé un goulet d'étranglement opérationnel significatif.

Le flux de travail manuel en deux étapes
Avant la mise en œuvre de l'IA, chaque document suivait un processus exigeant beaucoup de travail :
Étape 1 : Lecture et catégorisation du document
L'éditeur :
- reçoit un nouveau document juridique (de 2 à 350 pages),
- lit attentivement l'ensemble du document pour comprendre son contenu,
- extrait manuellement les informations clés : type de document, titre, année, juridiction, organisation,
- fait référence aux systèmes de taxonomie existants pour assurer une catégorisation cohérente,
- remplit environ 15 champs différents dans le système de gestion de contenu.
Temps nécessaire : 15 minutes à plusieurs heures par document, selon la longueur et la complexité.
Étape 2 : Vérification de la qualité
Le second éditeur :
- révise toutes les catégorisations,
- vérifie l'exactitude des attributions de champ,
- vérifie la cohérence avec les normes de la plateforme.
Les points douloureux
Solution : Flux de travail éditorial augmenté par l'IA
L'approche: augmenter, ne pas remplacer
Droptica a relevé ce défi en explorant comment l'IA pourrait augmenter - et non remplacer - le flux de travail éditorial. Lors de sessions de découverte collaboratives avec BetterRegulation, nous avons concentré nos efforts sur un objectif clair : éliminer les tâches de lecture manuelle et de saisie de données tout en laissant les éditeurs humains en charge de la qualité et de la prise de décision.
La philosophie était simple : laisser l'IA gérer le travail ennuyeux et répétitif, et laisser les humains gérer le jugement, la vérification et le contrôle de la qualité.
Phase de découverte et de test
Plutôt que de passer directement à la mise en œuvre, l'équipe de Droptica a effectué des tests approfondis de différentes approches pour s'assurer que la solution serait fiable, précise et prête pour la production.

Méthodes de traitement des PDF
Les PDF juridiques sont notoirement complexes. Ils contiennent souvent :
- plusieurs colonnes et des mises en page complexes,
- des en-têtes, des pieds de page et des numéros de page tout au long,
- des images et des graphiques intégrés,
- des tableaux et des données structurées,
- différentes polices et styles de formatage.
Nous avons évalué plusieurs méthodes pour extraire un texte propre et utilisable :
- API Direct PDF à ChatGPT - a révélé des limites avec le formatage complexe et les restrictions de taille de fichier.
- Bibliothèques de traitement de PDF traditionnelles - ont des difficultés avec les structures de document incohérentes et produisent un rendu bruyant.
- Unstructured.io - est apparu comme le grand gagnant.
Le choix d'Unstructured.io s'est avéré crucial. L’équipe a constaté qu'elle n'avait pas le contrôle de la construction des PDF - les documents juridiques contiennent souvent de nombreux marqueurs de formatage et des métadonnées qui peuvent encombrer la fenêtre de contexte et dérouter l'IA. Avec Unstructured.io, ils pouvaient les filtrer lors de la phase d'extraction. L'équipe a également constaté une précision significativement meilleure et des vitesses de traitement plus rapides par rapport aux autres méthodes.
Sélection du modèle de langue
L'équipe a testé plusieurs grands modèles de langage, les évaluant sur trois critères clés :
- Précision : le modèle pouvait-il correctement identifier et catégoriser les informations du document?
- Vitesse :à quelle vitesse pouvait-il traiter des documents allant de 2 à 350 pages?
- Coût :quel était le coût en token par document à des volumes attendus?
Après des tests approfondis avec de véritables documents de BetterRegulation, GPT-4o-mini s'est avéré être le choix optimal. L'équipe a testé d'autres modèles, y compris certaines variantes plus grandes, mais n'a pas constaté une amélioration de qualité qui justifiait la diminution des performances. GPT-4o-mini offrait le bon équilibre de vitesse, de précision, et une fenêtre de contexte suffisamment grande (128K tokens) pour traiter même les documents les plus longs.
Ingénierie des invitations
Un effort significatif a été consacré à la création d'invitations qui permettraient d'extraire et de catégoriser de manière fiable les informations. Ce processus itératif comprenait :
- Définition d'instructions claires et non ambiguës pour l'extraction des champs.
- Fourniture de listes de taxonomie complètes dans le contexte de l'invitation.
- Spécification des formats de sortie JSON exacts pour un analyse cohérente.
- Ajout de règles de validation et de gestion des cas limites.
- Tests avec des centaines de documents réels pour affiner la précision.
Comment ça marche
La fonctionnalité de remplissage automatique
La solution s'intègre de manière transparente dans le flux de travail éditorial existant de BetterRegulation basé sur Drupal 11.
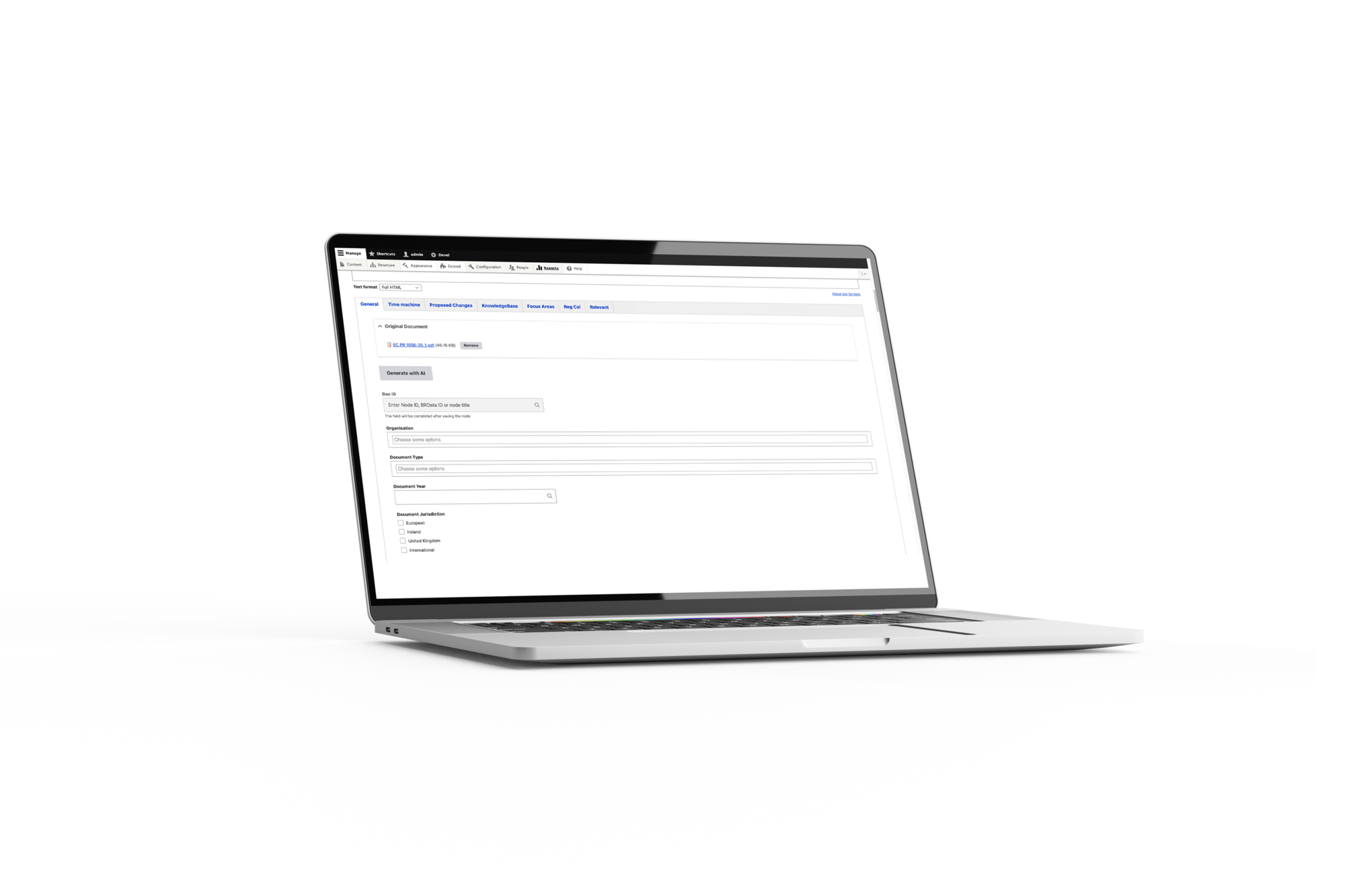
Du point de vue de l'éditeur :
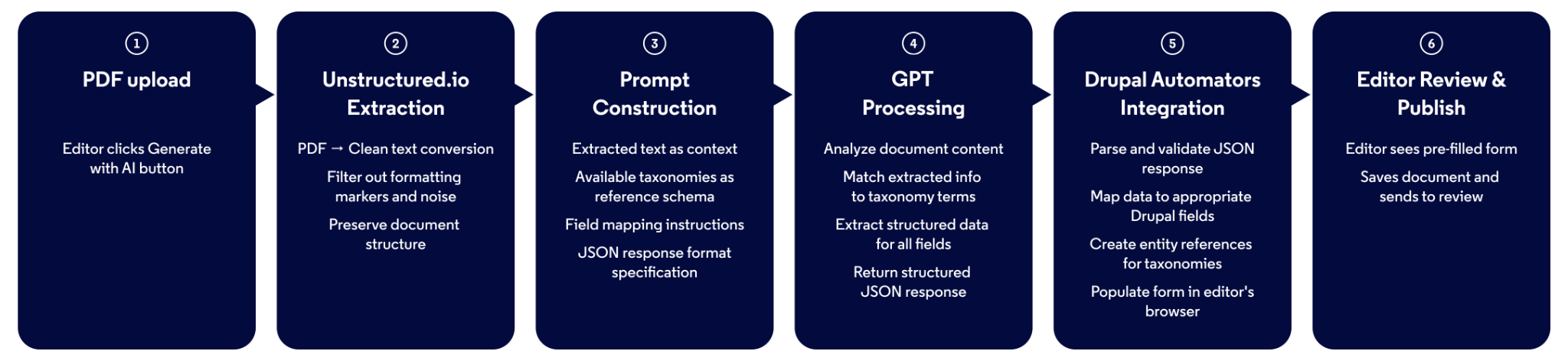
- Charger un PDF : l’éditeur crée une nouvelle entrée de document et télécharge le PDF dans le champ "Document Original".
- Cliquer sur "Générer avec AI" : un seul clic lance le traitement par IA.
- Attendre brièvement : de 10 secondes à 2 minutes en fonction de la taille du document (aucun rafraîchissement de page nécessaire).
- Ajuster si nécessaire : l'éditeur peut modifier n'importe quel champ avant de sauvegarder.
- Sauvegarder et publier : le document est prêt pour la plateforme.
La transformation de l'expérience :
- Avant : 15 minutes à plusieurs heures de lecture et de saisie de données manuelle.
- Après : cliqueter sur un bouton, attendre brièvement, envoyer une révision.
Les éditeurs restent en contrôle. Ils peuvent modifier tout champ rempli automatiquement avant de sauvegarder. Cela préserve les normes de qualité tout en éliminant le travail fastidieux.
Champs remplis automatiquement par l'IA
Le système peuple environ 15 champs, y compris :
Champs de texte :
- Titre - titre du document extrait et nettoyé.
- Corps/Résumé - extraction du contenu clé du document.
Références de taxonomie :
- Type de document - statut, règlement, guide, code, etc.
- Organisation - organisme émetteur ou autorité de régulation.
- Domaine du document - classification du sujet.
- Législation du document - cadre législatif connexe.
Références d'entité :
- Juridiction - UK, Irlande, EU, etc. (peut être multiple).
Champs de date :
- Année - quand le document a été promulgué ou publié.
Champs d'URL :
- URL Source - lieu de publication officielle.
Et des champs de métadonnées supplémentaires spécifiques au modèle de contenu de BetterRegulation
L'innovation technique: cartographie taxonomique intelligente
Une réalisation technique clé est la façon dont le système gère les références de taxonomie de Drupal. L'IA n'extrait pas seulement du texte ; elle mappe intelligemment l'information extraite aux termes de taxonomie existants dans la base de données Drupal.
Voici comment cela fonctionne :
- Injection de contexte : le système inclut la liste complète des termes de taxonomie disponibles pour chaque champ dans l'invite envoyée à l'IA
- Correspondance sémantique : l'IA analyse le contenue du document et le rapproche de ces termes en fonction de leur signification, et non de simples mots-clés
- Retour d'ID : il ne retourne pas seulement les noms de termes correspondants, mais leurs ID spécifiques d'entité Drupal
- Création de référence d'entité : le module Drupal Automators créé ensuite des références d'entité appropriées à l'aide de ces ID
Cette approche garantit :
- Une intégration transparente avec l'architecture de contenu existante de BetterRegulation.
- Pas de termes "orphelins" ou d'incohérences de données.
- Des relations appropriées entre les documents et les taxonomies.
- Une structure de données maintenable à mesure que les taxonomies évoluent.
Architecture technique
La solution repose sur une architecture robuste et prête à la production, conçue pour la fiabilité et l'évolutivité.
Pile technologique:
Drupal 11 - plateforme de gestion de contenu
Automateurs de Drupal (module contrib) - orchestre les flux de travail AI et gère la logique de traitement
Unstructured.io (Extracture) - extraction et nettoyage de texte PDF, auto-hébergé pour le contrôle
GPT (OpenAI) - modèle de langue pour l'analyse et la catégorisation du texte
RabbitMQ - queue de messages pour le traitement en arrière-plan (utilisé pour la fonctionnalité de résumé)
Watchdog - journalisation complète et surveillance des erreurs
Flux de traitement :
Décisions techniques clés
| Défi | Solution | Justification |
|---|---|---|
| Mise en page PDF complexe | Unstructured.io | Filtrage supérieur des artefacts PDF, meilleure gestion des tables et des mises en page multicolumnes, précision d'extraction plus élevée. |
| Sélection de modèle | GPT | Équilibre optimal vitesse/précision/coût, la grande fenêtre de contexte (128K tokens) gère les documents les plus longs. |
| Format de sortie | JSON structuré avec schéma | Assure des réponses cohérentes et analysables ; valide par rapport aux types de champs attendus. |
| Correspondance de taxonomie | Inclure les listes de taxonomie complètes dans l'invite | IA peut correspondre sémantiquement plutôt que par mots-clés exacts ; renvoie les bons ID d'entité. |
| Expérience utilisateur | Traitement à la demande synchronisé | Les éditeurs voient les résultats immédiats ; peuvent vérifier avant de sauvegarder ; pas d'attente pour les tâches en arrière-plan. |
| Grands documents | Dégradation élégante | Documents dépassant les limites de tokens signalés pour examen manuel avec des messages d'erreur clairs. |
| Fiabilité | Journal d'erreurs complet | Toutes les défaillances sont consignées dans Watchdog avec contexte ; le tableau de bord admin montre l'état de traitement. |
Gestion des cas limites
L'IA assiste mais ne remplace pas le jugement humain. Cette approche multi-niveaux garantit que les hauts standards de BetterRegulation sont maintenus tout en obtenant des avantages significatifs en matière d'efficacité.
Résultats: gains d'efficacité transformatifs
50% d'économie de temps dans le traitement des documents
Le résultat le plus significatif et immédiatement mesurable est la réduction drastique du temps nécessaire pour traiter les documents.
BetterRegulation réalise une économie de temps globale de 50% pour le processus complet d'ingestion, de catégorisation, de révision et de publication de documents.
1 équivalent ETP de capacité libéré
Ce qui était auparavant une journée de travail complète pour un éditeur est maintenant accompli en une heure. L'IA s'occupe de la partie fastidieuse - lire et extraire des informations - tandis que les éditeurs se concentrent sur la vérification et le contrôle de la qualité.
Cela représente approximativement un équivalent temps plein (1 ETP) de capacité éditoriale qui a été libéré pour un travail de plus grande valeur.
Évolutivité sans augmentation des effectifs
Peut-être le plus important pour l'entreprise BetterRegulation, la solution d'IA offre une évolutivité qui aurait auparavant nécessité une augmentation proportionnelle du personnel.
Innovation technique : l'histoire de succès de Drupal + IA
Ce projet met en évidence la puissance du Drupal moderne pour une intégration sophistiquée de l'IA.