
AI-Begriffe, die Sie kennen müssen. Teil Eins – 13 grundlegende Begriffe der künstlichen Intelligenz

Nach der „KI-Revolution von 2022“ gibt es eine einfache Erkenntnis – KI ist kein Trend, der bald verschwinden wird, sondern wird uns noch länger begleiten. Dies hat neue Positionen in der Branche und viele neue Ausdrücke hervorgebracht. Beim Diskutieren über KI gibt es viele Begriffe. Einige sind selbsterklärend, andere können verwirrend und unklar sein. Hoffentlich werden Sie nach dem Lesen unserer Artikel zu diesem Thema nicht überrascht sein, wenn Ihnen jemand diese neue Terminologie entgegenschleudert.
Grundlegende Begriffe der künstlichen Intelligenz
Wir teilen die Erklärung der KI-Begriffe in zwei Teile auf. In diesem Artikel behandeln wir einige grundlegende Begriffe der künstlichen Intelligenz, die Ihnen helfen werden, den Überblick über das Gespräch zu behalten und Ihr Verständnis von KI-bezogenem Wissen zu festigen. Im folgenden Artikel werden wir uns auf spezialisiertere Terminologie konzentrieren und die inneren Mechanismen bestehender KI-Lösungen erklären.
Künstliche Intelligenz (KI)
Künstliche Intelligenz (KI) ist ein weites Feld der Informatik, das darauf abzielt, Maschinen zu schaffen, die in der Lage sind, Aufgaben zu erfüllen, die normalerweise menschliche Intelligenz erfordern. Dazu gehören Problemlösung, Mustererkennung und das Verstehen natürlicher Sprache. Dieser Begriff umfasst nicht nur künstliche neuronale Netzwerke, sondern auch Lösungen wie genetische Algorithmen, Fuzzy-Logik usw.
KI-Modell/Checkpoint/Modelldeployment
Dies ist einer der verwirrendsten Teile der allgemeinen Diskussion.
- KI-Modell – das bezieht sich auf die Architektur eines künstlichen Intelligenzsystems. Es umfasst die Struktur der neuronalen Netze (wie Schichten, Neuronen usw.), die Algorithmen, die es verwendet, und die Parameter, die sein Verhalten definieren. Ein Modell ist ein theoretisches Konstrukt, das definiert, wie die KI Eingabedaten verarbeitet, um Ausgaben zu erzeugen.
- Checkpoint – ein Checkpoint ist ein gespeicherter Zustand eines trainierten Modells zu einem bestimmten Zeitpunkt. Er beinhaltet alle Parameter, Gewichte und Verzerrungen, die das Modell bis zu diesem Punkt gelernt hat. Checkpoints werden verwendet, um das Training zu pausieren und fortzusetzen, zur Wiederherstellung bei Unterbrechungen und für das Deployment eines trainierten Modells in verschiedenen Umgebungen. Sie repräsentieren eine spezifische Instanz eines Modells mit seinem gelernten Wissen zu einem bestimmten Stadium des Trainings.
- Modelldeployment – wenn Sie ein Modell haben, müssen Sie es „deployen“. Dies umfasst das Erstellen oder Verwenden verfügbarer Anwendungen oder Skripte (mehr dazu im zweiten Artikel), um eine Schnittstelle für die Interaktion mit dem Modell bereitzustellen. Dies beinhaltet auch Infrastruktur wie einen Server mit GPU, eine Weboberfläche oder eine API, damit Benutzer mit dem Modell interagieren können.
Um es zu verdeutlichen: Wenn Sie sagen, „Ich benutze ChatGPT“, beziehen Sie sich auf das gesamte System, das die Interaktion mit dem „ChatGPT“-Modell ermöglicht.
Big Data
Dieser KI-Begriff bezieht sich auf extrem große Datensätze, die so komplex und umfangreich sind, dass herkömmliche Datenverarbeitungstools unzureichend sind, um sie zu verwalten und zu analysieren.
Die Bedeutung von Big Data liegt nicht nur in seiner Größe, sondern auch in seiner Komplexität und der Geschwindigkeit, mit der es erzeugt und verarbeitet wird. Es wird traditionell durch die sogenannten drei V's – Volumen, Geschwindigkeit und Vielfalt – charakterisiert:
- Volumen – bezieht sich auf die schiere Menge an Daten, die aus verschiedenen Quellen wie Transaktionen, sozialen Medien, Sensoren etc. gesammelt werden. Das Wachstum im Datenvolumen wurde durch die Verfügbarkeit günstigerer Speicheroptionen wie Data Lakes, Hadoop und Cloud-Speicher ermöglicht.
- Geschwindigkeit – dieser Aspekt von Big Data dreht sich um die Geschwindigkeit, mit der Daten erzeugt und verarbeitet werden müssen.
- Vielfalt – Big Data erscheint in verschiedenen Formaten – von strukturierten, numerischen Daten in traditionellen Datenbanken bis hin zu unstrukturierten Texten, Videos, Audios und mehr.

Chatbot
Es handelt sich um eine Softwareanwendung, die darauf ausgelegt ist, Online-Gespräche entweder über Text oder Text-to-Speech zu führen und eine menschenähnliche Interaktion zu simulieren. Das erste bemerkenswerte Beispiel war „Eliza“, das 1966 von Joseph Weizenbaum entwickelt wurde. Eliza funktionierte, indem es die Satzmuster aus Benutzereingaben analysierte und Schlüsselwortsubstitution und Wortreihenfolgenänderungen einsetzte, um Antworten zu erstellen und so eine Illusion des Verstehens zu erzeugen. Sein „DOCTOR“-Skript, das einen Rogerianischen Psychotherapeuten nachahmte, war besonders bekannt für die scheinbar sinnvollen Gespräche mit den Nutzern.
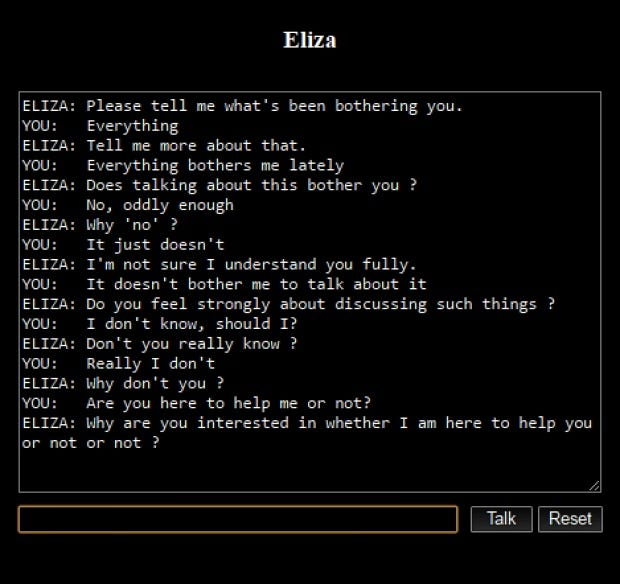
Quelle: medium.com
Das Feld der Chatbots hat sich seit diesen frühen Beispielen erheblich weiterentwickelt. Moderne Chatbots wie ChatGPT und Google Bard nutzen fortgeschrittene KI- und maschinelle Lerntechnologien. Diese zeitgenössischen Versionen glänzen im Verständnis von Kontext, im Management komplexer Dialoge und im Bereitstellen informativer, kohärenter Antworten, weit über die Fähigkeiten ihrer Vorgänger hinaus.
Diffusionsmodell
Das Diffusionsmodell ist eine Klasse von generativen Modellen. Sie bestehen in der Regel aus drei Hauptkomponenten: Sampling, Vorwärts- und Rückwärtsprozess. Im modernen Kontext bezieht sich dieser Begriff normalerweise auf den Bildgenerierungsprozess.
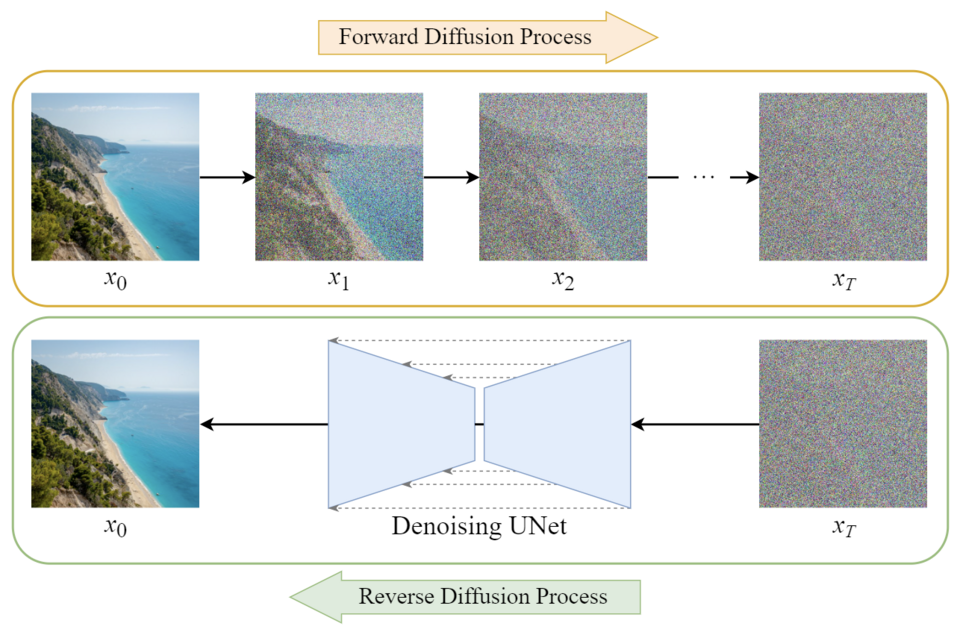
Quelle: towardsai.net
Im Bereich der Bildgenerierung werden Diffusionsmodelle auf Bildersätzen mit hinzugefügtem künstlichem Rauschen trainiert. Die Aufgabe des Modells besteht darin, dieses Rauschen iterativ zu entfernen, wodurch es „lernt“, das ursprüngliche Bild wiederherzustellen.
Dieser Prozess ermöglicht es dem Modell, neue Bilder basierend auf einer Kombination aus Benutzereingaben und einer Probe von latenten Rauschen zu erzeugen. Die Arbeitsweise von Diffusionsmodellen lässt sich umgangssprachlich mit dem Satz „Ich sehe ein Gesicht in diesem Regenbogen“ zusammenfassen, der metaphorisch beschreibt, wie diese Modelle strukturierte Bilder aus scheinbar zufälligen Rauschmustern erkennen.
Beispiel eines Diffusionsmodells in Aktion, erzeugt in Midjourney
Feinabstimmung
Dieser KI-Begriff bezieht sich auf den Prozess der Anpassung eines bereits trainierten KI-Modells, um es einem neuen, spezifischen Datensatz oder einer neuen Aufgabe anzupassen. Dies beinhaltet das „Einbringen neuen Wissens“ in das Modell. Zum Beispiel, wenn Sie ein OpenAI-Modell so anpassen möchten, dass es Fragen basierend auf den Daten Ihrer Website beantwortet, würden Sie das bestehende Modell mit einem Datensatz aus Ihrer Webseite feinabstimmen.
Die Feinabstimmung kann für größere Modelle zeitaufwendig sein und erfordert oft zusätzliche Mechanismen, um Änderungen in den Daten aufzunehmen. Zum Beispiel könnte das Hinzufügen eines neuen Blog-Beitrags zu Ihrer Website eine Neu-Trainierung des Modells erfordern, um diese neuen Informationen zu integrieren. Die Feinabstimmung ermöglicht die Anpassung von KI-Modellen an spezifische Domänen oder Anforderungen, ohne sie von Grund auf neu trainieren zu müssen.
Generative KI
Der Begriff generative KI bezieht sich auf eine Unterklasse von KI-Modellen. Diese sind darauf ausgelegt, neue Inhalte zu generieren, basierend auf Mustern und Kenntnissen, die sie aus ihren Trainingsdaten und Benutzereingaben gelernt haben. Solche Modelle sind fähig zu kreativen Aufgaben, wie das Verfassen neuer Stücke im Stil bestimmter Autoren oder das Erschaffen von Kunst und Musik, die bestimmte Stile nachahmen.
Zum Beispiel könnte ein Modell, das in den Werken Shakespeares trainiert wurde, neue Gedichte oder Textpassagen generieren, die seinen einzigartigen Stil und seine sprachlichen Nuancen nachahmen. Der Schlüsselaspekt der generativen KI ist ihre Fähigkeit, originelle Ausgaben zu erstellen, die kohärent und kontextuell relevant sind und oft den Anschein erwecken, als wären sie von einem Menschen erschaffen worden.
Ein Gespräch mit ChatGPT
Großes Sprachmodell (LLM)
Dieser Begriff beschreibt eine Klasse von KI-Modellen, die auf großen Mengen von natürlichen Sprachdaten trainiert werden. Ihre Hauptfunktion besteht darin, menschlichen Text zu verstehen, zu verarbeiten und zu erzeugen. LLMs erreichen dies, indem sie aus einem breiten Spektrum an Spracheingaben lernen und statistische Wahrscheinlichkeiten nutzen, um neuen Inhalt zu rekonstruieren und zu generieren.
Diese Modelle sind nicht nur geschickt darin, Texte zu erzeugen, die kohärent und kontextuell relevant sind. Sie sind auch fähig, verschiedene sprachbezogene Aufgaben wie Übersetzung, Zusammenfassung und Beantwortung von Fragen durchzuführen. Die Größe und Vielfalt der Trainingsdaten ermöglichen es diesen Modellen, ein umfassendes „Verständnis“ von Sprache, Kontext und Nuancen zu besitzen.
Natürliche Sprachverarbeitung (NLP)
NLP ist ein Feld an der Schnittstelle von Informatik, künstlicher Intelligenz und Linguistik. Es konzentriert sich darauf, Computern das Verstehen, Interpretieren und Generieren menschlicher Sprache auf eine wertvolle und sinnvolle Weise zu ermöglichen. Kritische Aufgaben in NLP umfassen Sprachübersetzung, Sentimentanalyse, Spracherkennung und Textzusammenfassung.
Das Ziel ist es, Systeme zu erstellen, die mit Menschen durch Sprache interagieren können, Einblicke aus Text- oder Sprachdaten extrahieren und menschenähnliche Antworten erzeugen. NLP kombiniert rechnerische Techniken mit sprachspezifischem Wissen, um effektiv große Mengen an natürlicher Sprachdaten zu verarbeiten und zu analysieren.
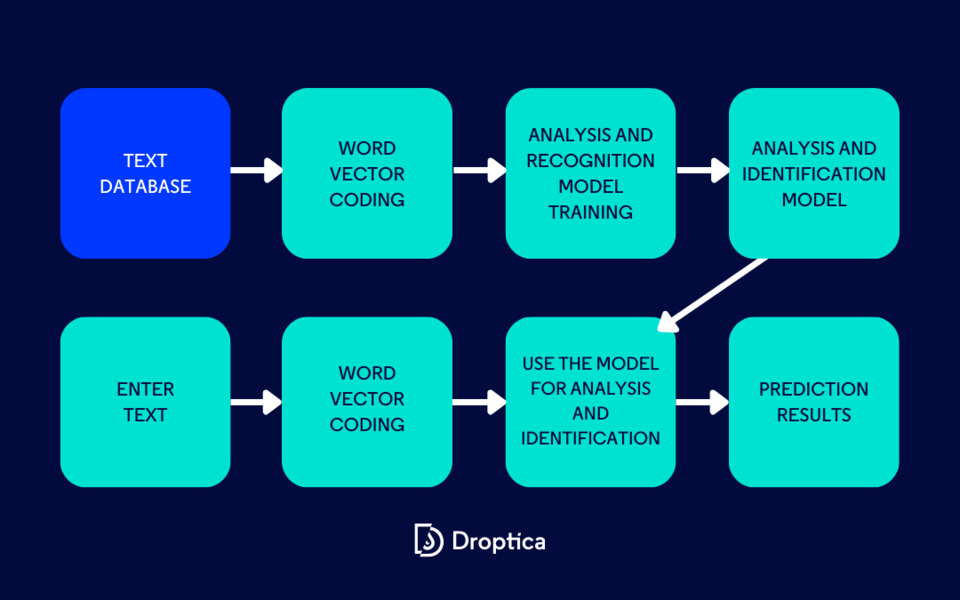
Optische Zeichenerkennung (OCR)
OCR ist der Prozess der Umwandlung von Bildern handgeschriebener oder gedruckter Texte in maschinenkodierten Text. Weit verbreitet als eine Form der Dateneingabe, ist es eine übliche Methode zur Digitalisierung von gedruckten Texten, sodass sie gespeichert, bearbeitet, durchsucht oder in ein Großes Sprachmodell eingegeben werden können.
Prompt
Im Kontext von KI ist ein Prompt eine vom Benutzer bereitgestellte Eingabe, die ein KI-Modell dazu anleitet, einen bestimmten Output zu generieren. Es fungiert als Anleitung oder Anweisung für die KI, die ihre Antworten oder die von ihr erzeugten Inhalte formt. Prompts können stark variieren – von einfachen Fragen bis hin zu komplexen Szenarien – und sind entscheidend für die Bestimmung, wie das KI-Modell Benutzeranfragen interpretiert und darauf reagiert.
Prompt-Engineering
Dieses aufstrebende Feld konzentriert sich darauf, Interaktionen mit KI-Modellen zu optimieren, um gewünschte Outputs zu erzielen. Prompt-Engineering umfasst ein tiefes Verständnis dafür, wie KI-Modelle natürliche Sprache verarbeiten und das Erstellen von Prompts, um die KI zu spezifischen Lösungen oder Antworten zu lenken.
Es ist besonders relevant im Kontext großer Sprachmodelle, wo die Art und Weise, wie ein Prompt formuliert ist, erheblichen Einfluss auf den Output des Modells haben kann. Dieses Feld gewinnt an Bedeutung, da KI-Systeme häufiger und ausgeklügelter werden, was geschickte Techniken erfordert, um ihre Fähigkeiten effektiv zu nutzen.
Token
Im Bereich der Großen Sprachmodelle ist ein Token eine grundlegende Einheit von Text, die das Modell verarbeitet. Das Konzept eines Tokens ergibt sich aus dem Prozess der „Tokenisierung“, bei dem der Eingabetext in kleinere Stücke oder Tokens unterteilt wird. Diese Tokens werden dann vom Modell verwendet, um Text zu verstehen und zu generieren. Es ist wichtig zu beachten, dass ein Token nicht unbedingt einem einzelnen Zeichen entspricht. Im Englischen könnte ein Token beispielsweise ein Wort oder ein Teil eines Wortes darstellen, das typischerweise durchschnittlich etwa vier Zeichen lang ist.
Die genaue Definition eines Tokens kann je nach Sprachmodell und den Besonderheiten seines Tokenisierungsalgorithmus variieren. Tokens sind entscheidend für Modelle, um natürliche Spracheingaben zu verarbeiten und kohärente Antworten oder Texte zu generieren, da sie die Granularität bestimmen, mit der das Modell die Eingabe interpretiert.
Grundlegende KI-Begriffe – Zusammenfassung
In diesem Artikel haben wir die Bedeutung von KI-Begriffen und -Konzepten offenbart und hoffentlich einige Fachausdrücke und Verwirrungen geklärt. Das Verstehen dieser grundlegenden Phrasen ist unerlässlich für jeden, der sich in dem wachsenden Bereich der künstlichen Intelligenz engagieren möchte – sei es aus beruflichen Gründen oder aus persönlicher Neugier. Wenn Sie eines dieser Bereiche in ein spezifisches Projekt umwandeln müssen, können Sie Hilfe von unseren Spezialisten in Anspruch nehmen, die in KI-Entwicklungsdiensten erfahren sind.










