
Welche Server-Uptime-Überwachungstools sind es wert, verwendet zu werden?

Serverüberwachung ist ein komplexer Prozess zur Überwachung der gesamten Serverinfrastruktur und ihrer Abhängigkeiten, um die Nutzung der Systemressourcen zu analysieren und zu optimieren, um Endnutzern Dienste bereitzustellen. Es ist zweifellos eines der Schlüsselelemente für den effizienten Betrieb von Infrastrukturen. Daher ist die Wahl des richtigen Tools zur Überwachung der Serververfügbarkeit wichtig für jedes Unternehmen.
Warum ist die Verfügbarkeitsüberwachung wichtig?
Überwachung ist ein Standard in der IT-Welt, da sie es Ihnen ermöglicht, die Server des Unternehmens in optimalem Zustand zu halten. Der Prozess der Serverleistungsüberwachung selbst ist ziemlich einfach – er basiert auf der regelmäßigen Erfassung von Serverdaten und ihrer Echtzeit- oder historischen Analyse. Dadurch können wir sicherstellen, dass die Server optimal arbeiten und somit die beabsichtige Funktion erfüllen.
Sie können fast alles überwachen, einschließlich Prozessorleistungssteuerung, Speichernutzung, Netzwerk- und Festplattenplatzbandbreite sowie Erkennung von Problemen im Zusammenhang mit der Nutzung der Server. Doch nur zu wissen, wie man seinen Server überwacht, reicht nicht aus. Es ist notwendig zu verstehen, warum dies ein so wichtiger Bestandteil der Sicherheit der Organisation ist. Das Ziel der Überwachung ist es, über Ausfälle und Leistungsprobleme zu informieren und Probleme im Voraus zu lösen. In der Praxis bedeutet dies, dass Ausfälle oder Anomalien so schnell erkannt werden, dass der gesamte Service, die Anwendung oder der Betrieb des Unternehmens nicht gestoppt wird. Dadurch arbeitet die Serverinfrastruktur des Unternehmens ordnungsgemäß und stabil, und die Organisation erleidet keine Verluste, die durch lange Unterbrechungen im Systembetrieb verursacht werden.
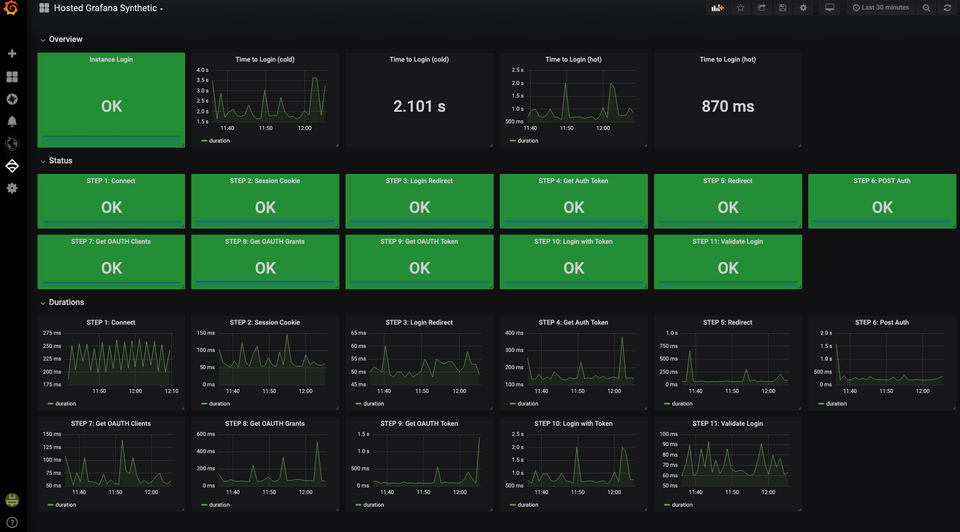
Quelle: Grafana
Wie erkennen Sie, dass ein Server ausgefallen ist?
Eine ordnungsgemäße und ununterbrochene Serverüberwachung stellt sicher, dass der Server läuft und ordnungsgemäß optimiert ist. Darüber hinaus ermöglicht sie es, das Risiko von Unterbrechungen im Systembetrieb zu minimieren. Und wenn ein Ausfall auftritt, eine präzise Analyse der Prozesse durchzuführen, die zu einer schnellen Reparatur führt. Allerdings kann niemand die Zukunft vorhersagen, und alles kann passieren – die Anwendung wird nicht mehr funktionieren, dem Server gehen die Ressourcen aus, es gibt ein Problem mit der Verfügbarkeit der Internetdienste usw. In einem solchen Fall sollte die Information über die nicht verfügbare Webseite oder andere Dienste vom Überwachungssystem bereitgestellt werden, nicht vom Geschäftsführer des Unternehmens oder vom Endnutzer. Um solche Situationen zu vermeiden, sollten Sie ein geeignetes Überwachungstool implementieren, das Administratoren oder zuständige Abteilungen über mögliche Probleme und Ausfälle informiert, bevor sie auftreten.
1. Zabbix
Es ist der inoffizielle Marktführer im Bereich der Überwachung. Die Ursprünge dieses Tools reichen bis ins Jahr 1998 zurück, und sein Schöpfer und Gründer ist Alexei Vladishev, der sein Produkt immer noch sehr aktiv weiterentwickelt. Zabbix ist eine Open Source-Lösung, die auf der GPL (General Public License) basiert, wodurch es frei für kommerzielle und nicht-kommerzielle Nutzung ist. Bisher hat das Programm ein Dutzend Versionen, und derzeit ist die beliebteste Version 5.0 LTS, mit fünf Jahren Langzeitunterstützung, die ideal für die Produktionsumgebung ist. Die folgende Veröffentlichung trug die Nummer 5.4, und 6.0 LTS wurde kürzlich veröffentlicht, während die Roadmap über die Pläne für weitere Versionen bis zu 7.0 LTS informiert. Jede neue Version enthält eine Reihe von Änderungen, die die Bedürfnisse und Anforderungen des dynamischen IT-Marktes berücksichtigen. Version 6.0 führt neue Funktionalitäten ein. Die interessantesten darunter sind das Monitoring von Kubernetes-Clustern, die Erkennung von Anomalien basierend auf Maschinenlernen und die Erweiterung der Überwachung im Hinblick auf das Business.
Das Zabbix-System ermöglicht die Überwachung von Geräten, die die SNMP-, IPMI-Technologien und die ICMP-, TCP-, UDP-, HTTP-Protokolle unterstützen, sowie die Erstellung eigener Überwachungselemente. Die Hardware-Überwachung umfasst Desktop-Computer, physische Server, virtuelle Server, Netzwerk-Laufwerke, Switches, Router, Windows- und Linux-Umgebungen und vieles mehr. Die Funktionalitäten von Zabbix sind enorm und erlauben es Ihnen, beispielsweise zu überwachen:
- Prozessorlast, Netzwerkkarten und Speicher, die Menge an freiem Speicherplatz auf Festplatten,
- Webseiten und Webanwendungen,
- Standardnetzwerkprotokolle: SMTP, ICMP, SSH, TELNET, IPMI, JPX, HTTP/HTTPS,
- verteilte Standorte (Filialen oder Tochtergesellschaften),
- Gültigkeit von SSL-Zertifikaten auf Webseiten,
- Temperatur der einzelnen Komponenten,
- korrekte Ausführung einer SQL-Abfrage.
Um die oben aufgeführten Ressourcen zu überwachen, können Sie die fertigen, kostenlosen Templates verwenden oder Ihre eigenen erstellen.
Die Architektur von Zabbix besteht aus mehreren Elementen. Das wichtigste davon ist der Zabbix-Server, der für die Datenaufnahme, Aggregation und Verarbeitung sowie für die Generierung von Ereignissen auf dieser Basis und die Erkennung von Anomalien verantwortlich ist. Für ausgewählte Vorfälle können Sie Alarme in Form einer SMS, E-Mail oder per Webhook zur Integration mit den beliebtesten Helpdesk-Systemen, Chats und Messengern (z. B. Microsoft Teams, Messenger) senden. Ein weiteres Element ist der Zabbix-Agent, der die Metriken des Betriebssystems lokal sammelt. Dieser Daemon, der in UNIX- und Windows-Systemen verfügbar ist, hat einen geringen Ressourcenverbrauch und kann sowohl im passiven als auch im aktiven Modus ausgeführt werden. Im passiven Modus verarbeitet der Agent die Anfrage vom Server zusammen mit der Liste der Parameter, die er überwachen soll, und gibt die gesammelten Daten zurück. Im aktiven Modus stellt der Agent zuerst die Kommunikation mit dem Server her und sendet ihm regelmäßig Daten. Dieser Modus ist nützlich, wenn der Server aus irgendeinem Grund nicht direkt mit dem Agent kommunizieren kann. Dank seiner zahlreichen eingebauten Templates kann der Agent viele Parameter ohne zusätzliche Konfiguration überprüfen. Ein optionales Element, das Sie verwenden können, ist der Zabbix-Proxy-Server, der die Kommunikation zwischen Zabbix-Agent und Zabbix-Server vermittelt. Eine solche Lösung ist in einer Infrastruktur, die sich über viele Standorte verteilt, z. B. Unternehmensabteilungen, Standorte mit schlechter Konnektivität oder Orte ohne lokale Administratoren, zu empfehlen.
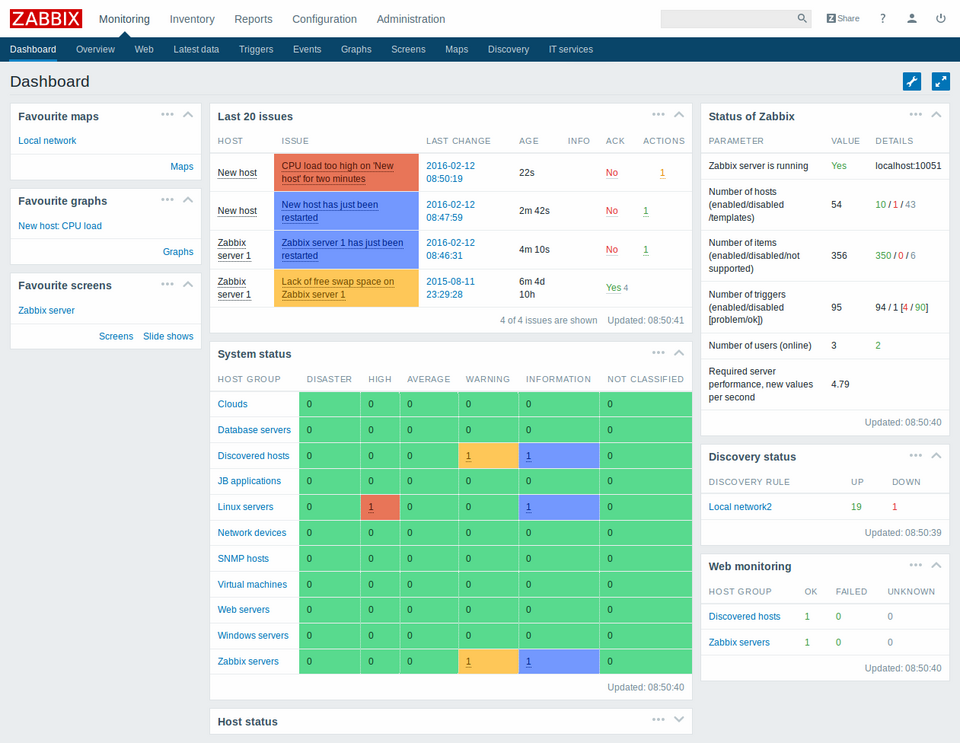
Quelle: Zabbix
Zabbix bietet auch eine breite Palette an Integrationen mit verschiedenen Systemen und Plattformen. Unter den zahlreichen, über 500, Tools finden sich die Integrationen mit:
- den größten Cloud-Service-Providern (z. B. AWS, Azure, Google),
- Containern (z. B. Docker, LXC),
- Ticktesystemen (z. B. Jira, OTRS),
- Konfigurationsmanagementsystemen (z. B. Ansible, Puppet),
- Nachrichtensystemen (z. B. PagerDuty, Slack).
Ein großer Vorteil von Zabbix ist seine Community und die Möglichkeit, Wissen über viele Support-Kanäle zu erwerben (einschließlich Support-System, Telegram, Discord, Zabbix-Forum). Für anspruchsvollere Kunden hat der Hersteller fünf verschiedene Unterstützungsstufen vorbereitet – abhängig von den erwarteten Bedürfnissen.
2. Nagios XI
Nagios XI ist ein System zur Überwachung von Unternehmensinfrastrukturen, das aus der Open Source-Welt stammt. Diese Software wurde basierend auf dem Nagios Core-Engine erstellt, die mit der Zeit um die für Geschäftskunden angepassten Funktionen erweitert wurde. Nagios Core blieb ein kostenloses Tool, das unter der GNU GPL v2-Lizenz entwickelt wurde, während Nagios XI zu einer vollständig kommerziellen Lösung geworden ist.
Die Architektur von Nagios XI basiert auf der Familie der Linux/Unix-Systeme mit dedizierten Systemen für die Installation: CentOS, Redhat Enterprise Linux, Ubuntu und Debian. Das Tool kann jedoch auch auf Windows bereitgestellt werden, indem der VMware Workstation Player oder die Hyper-V-Umgebung verwendet wird. Dieses Tool hat unbegrenzte Möglichkeiten und wird zur umfassenden Infrastrukturüberwachung eingesetzt. Neben der Überwachung kritischer Infrastrukturelemente, d. h. Netzwerkgeräte und -protokolle, Anwendungen, Betriebssysteme, Datenbanken, bietet Nagios XI die Überwachung von Computerressourcen, die Kontrolle von Umweltparametern und IoT. Die Kunden können zwischen zwei Versionen des Produkts wählen: Standard Edition und Enterprise Edition.
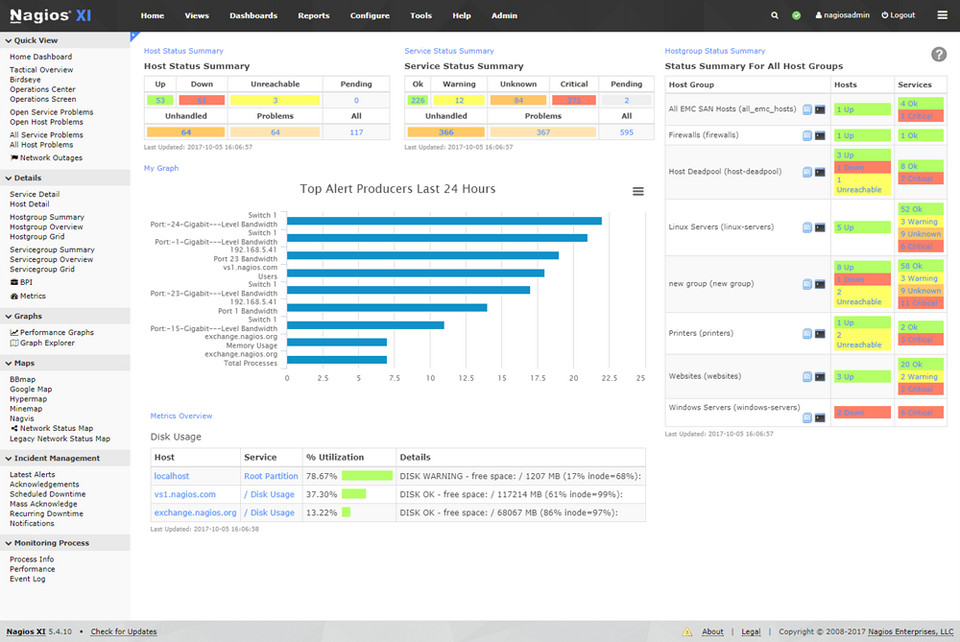
Quelle: Nagios
Obwohl Nagios XI ein kommerzielles Tool ist, bietet der Hersteller eine kostenlose Lizenz für bis zu sieben Nodes an, die für den Heimgebrauch äußerst vorteilhaft sein kann – unter den Beispielen sind:
- Überwachung des Zustands des Heimdateiservers (Speicher, Temperatur),
- Überwachung des Druckerstatus (Tinten- und Papierstand im Drucker), Router oder Switch,
- Verwendung in einem Smart Home zusammen mit Raspberry Pi und Sammeln von Sensordaten und Bereitstellen von Daten zu, z. B., Grundwasserstand, Sonnenlicht oder sogar Säuregrad (pH) des Bodens und Garagentorstatuswarnungen basierend auf der Tageszeit.
Das Tool wird auf Browserebene bedient, und das Interface selbst ist einfach und klar. Es gibt jedoch noch Verbesserungsmöglichkeiten, da die Benutzeroberfläche deutlich von den aktuellen Trends abweicht.
Auf der anderen Seite sind die Konfigurationsassistenten von Nagios XI intuitiv, benutzerfreundlich und erfordern kein komplexes Wissen über den IT-Infrastrukturüberwachungsprozess. Die gesammelten Daten werden für Diagramme, Ereignisprotokolle, Statistiken, Trendanalysen sowie Ressourcen- und Leistungsplanung verwendet. Alle Warnungen in Bezug auf z. B. Nichtverfügbarkeit von Diensten oder Überschreitung kritischer Werte werden per E-Mail und SMS gesendet.
Die Systemfähigkeiten können durch eine breite Palette von Drittanbieter-Add-ons, die unter der GPL-Lizenz verfügbar sind, erweitert werden. Nagios XI hat auch eine erweiterbare Architektur mit der Möglichkeit, jede bevorzugte Programmiersprache zu verwenden. Das System bietet viele APIs und ermöglicht eine einfache Integration mit internen und externen Anwendungen.
3. Prometheus
Prometheus, bekannt als Open Source-System für die Überwachung und Alarmierung, wurde 2012 von ehemaligen Google-Mitarbeitern entwickelt. Ursprünglich war es nur für die Überwachung von containerisierten Umgebungen gedacht, doch über die Zeit erweiterte es seine Fähigkeiten auf Anwendungen, Server, Datenbanken und virtuelle Maschinen. Derzeit wird das System intensiv in Cloud-Umgebungen entwickelt.
Prometheus ist ein unabhängiges Open Source-Tool, das aktiv von einer Entwickler-Community unterstützt wird, und alle seine Komponenten sind unter der Apache 2-Lizenz auf GitHub verfügbar. Dies hindert jedoch große Unternehmen nicht daran, dieses System als Schlüsselelement ihrer Infrastruktur zu verwenden. Zu den Kunden zählen z. B. DigitalOcean, Docker, Showmax oder SoundCloud. Darüber hinaus zeigt die Stärke des Tools die Tatsache, dass Prometheus nach Kubernetes als zweites Projekt der Cloud Native Computing Foundation beigetreten ist. Nur die Anbieter der am schnellsten wachsenden Open Source-Projekte erhalten eine solche Auszeichnung.
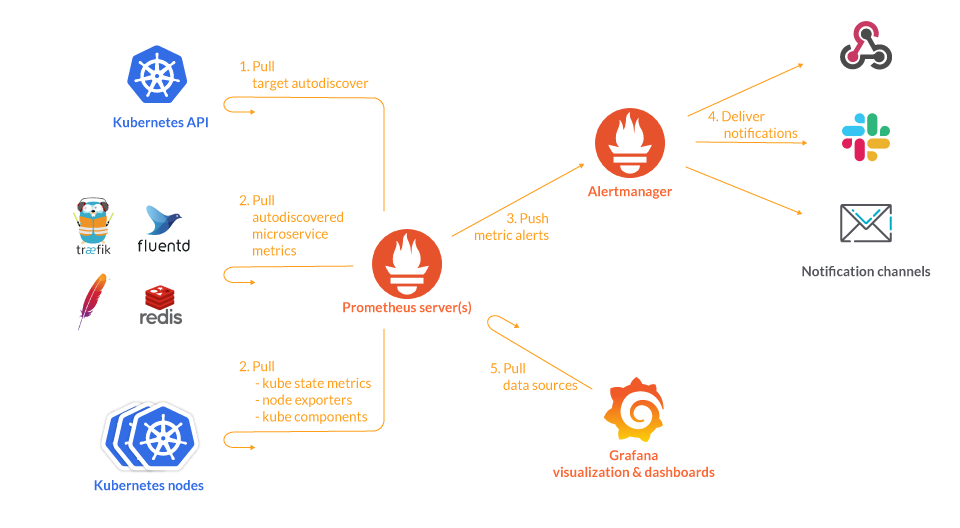
Das Schlüsselelement des Betriebs dieses Tools sind die Metriken, die eine bestimmte Anwendung oder Instanz charakterisieren und Informationen über sie bereitstellen. Kundenbibliotheken für Prometheus bieten vier Haupttypen von integrierten Metriken, die verschiedene Daten bereitstellen können, z. B. die Anzahl der HTTP-Anfragen und Fehler (die Counter-Metrik), die Antwortzeit (Histogramm), die Speichernutzung (Gauge) und die Anzahl der aktiven Benutzer (Summary). Jede Metrik wird einem Namen zugewiesen, auf den zusammen mit optionalen Schlüssel-Wert-Paaren, sogenannten Labels, verwiesen werden kann. Prometheus sammelt Metriken basierend auf Push- und Pull-Methoden. Bei der ersten Methode ist die überwachte Anwendung selbst dafür verantwortlich, ihre eigenen Metriken über Pushgateway an das Überwachungssystem zu senden. Bei der Pull-Methode ist die Anwendung passiv und bereitet nur ihre Metriken in Form eines Endpunkts vor, während Prometheus entscheidet, wann sie heruntergeladen werden sollen, basierend auf den Regeln. Dieses Tool zur Überwachung der Serververfügbarkeit hat eine effiziente integrierte Zeitreihendatenbank, sodass die Informationen über Metriken mit dem Zeitstempel gespeichert werden, der die Zeit angibt, zu der sie erfasst wurden.
Einer der Säulen des Tools ist die Prometheus Query Language (PromQL), die verwendet wird, um Abfragen und Aggregationen von Überwachungsdaten in Echtzeit mit einer Vielzahl von Operatoren und Funktionen durchzuführen. Die unabhängige Alertmanager-Anwendung wird verwendet, um die Überwachung zu automatisieren, die Warnungen generiert und sendet, wenn bestimmte Bedingungen beobachtet werden. Prometheus bietet eine breite Palette an Exportern, um praktisch alles zu überwachen, hat jedoch nicht die Fähigkeit, die gesammelten Daten selbst zu visualisieren. Hier kommt Grafana ins Spiel, wo Dashboards mit Datenquellen verbunden werden, um Metriken fast in Echtzeit zu visualisieren. Die Spezialisten beider Lösungen arbeiten intensiv miteinander zusammen, entwickeln die bereits fortschrittliche Integration mit Prometheus in Grafana weiter und bieten den Grafana-Kunden Zugang zu den benötigten Prometheus-Funktionen.
Die Zusammenarbeit mit dem größten Anbieter von Cloud-Services, Amazon Web Services, bringt ebenfalls große Ergebnisse. Letztes Jahr wurde Amazon Managed Service for Prometheus eingeführt. Es ist vollständig kompatibel mit Prometheus, verfügt über hohe Verfügbarkeit, skaliert automatisch bei wachsendem Bedarf und enthält die AWS-Compliance- und Sicherheits-Suite. Der Service ermöglicht das Sammeln von Metriken aus den Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS) und Amazon Elastic Kubernetes Service (Amazon EKS) Umgebungen.
Quelle: Sysdig
4. Datadog
Es ist eine vollständige Lösung zur Überwachung und Analyse von Infrastruktur und Anwendungen. Das Tool ermöglicht die Visualisierung der gesammelten Daten und das Senden von Benachrichtigungen bei technischen Problemen und hilft den Administratoren, kritische Fehler zu erkennen und die IT-Systeme vollständig zu kontrollieren. Datadog funktioniert im SaaS-Modell und wird in cloudbasierten, hybriden oder lokalen Infrastrukturumgebungen eingesetzt. Der Umfang umfasst traditionelle Infrastrukturüberwachung, Echtzeit-Anwendungsleistungsüberwachung, Netzwerkaktivität und Verkehrsanalysen, Überwachung der Datenbank-, DNS- und Bandbreitenleistung.
Datadog aggregiert Metriken und Ereignisse an einem Ort, ermöglicht ihre einfache Analyse und unterscheidet die aktuellen Werte kritischer KPIs, SLOs und SLAs. Transparente und dynamische Dashboards werden dafür verwendet, ohne dass eine Abfragesprache oder Programmierung erforderlich ist, mit einer Vielzahl von Bibliotheken mit Formeln, Funktionen und Drag-and-drop-Widgets.
Problemlösungen, Warnungen und Diagrammerstellung sind dank über 500 Integrationen möglich, darunter Zusammenarbeit mit Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, OpenStack oder Red Hat OpenShift. Darüber hinaus ist Datadog kompatibel mit den Metriken der immer beliebter werdenden DevOps-Tools – Kubernetes und Prometheus. Ein weiterer Vorteil des Systems ist das Log-Management. Logs von allen Diensten, Anwendungen und Plattformen bereitgestellt, suchen und filtern, automatische Markierung, Visualisierung und Alarmierung von Log-Daten – das bedeutet eine effektivere Überwachung. Lösungen basierend auf künstlicher Intelligenz werden verwendet, um Anomalien zu erkennen. Warnungen über Probleme in der Umgebung werden per E-Mail, PagerDuty, Slack, Hangouts Chat und Microsoft Teams gesendet. Die Stärke des Datadog-Systems wird durch die Größe seiner Kunden demonstriert. Es wird von Marken wie Samsung, Siemens, Lego System, Sony und Lufthansa Systems verwendet.
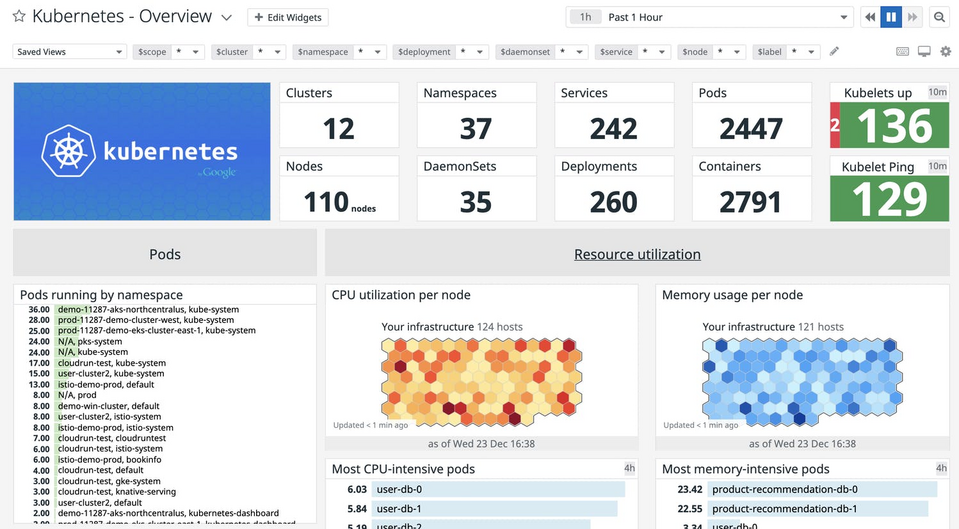
Quelle: Datadog
5. Sematext
Sematext ist eine Lösung zur Überwachung der Infrastruktur- und Anwendungsleistung sowie des Log-Managements. Das Tool kann in der Cloud- oder Enterprise-Version verwendet werden. Während Sematext Cloud ein vollständig verwalteter SaaS-Dienst ist, ist Sematext Enterprise ein sofort einsatzfähiges Paket, das heruntergeladen und in Ihrer Infrastruktur ausgeführt werden kann. Beide Versionen enthalten das gleiche Dienstleistungspaket und ermöglichen vollständige Infrastruktursichtbarkeit, Container- und Datenbanküberwachung, Anwendungsleistungssteuerung, Log-Management und Alarmierung. Die zunehmend beliebte Cloud-Version zeichnet sich durch hohe Verfügbarkeit, Skalierbarkeit und Leistung sowie die Überwachung von Diensten in privaten, öffentlichen und hybriden Clouds aus. Um auf Hosts zu arbeiten, wird ein Agent benötigt, der automatisch die zu überwachenden Elemente erkennt. Hosts können jede physische Maschine, Systeme in virtuellen Umgebungen, Container (Docker, ECS) oder Cluster (EKS, Kubernetes) sein.
Sematext bietet vollständig verwaltete Elasticsearch- und Kibana-Dienste, ohne dass teure Spezialisten und Infrastruktur erforderlich sind, wodurch Ihnen Zeit für die Systemwartung gespart wird. Das Interface und der Betrieb des Dashboards sind benutzerfreundlich und ermöglichen:
- Filtern und Analysieren von Metriken und Ereignissen,
- Suche nach Daten,
- Erstellung benutzerdefinierter Dashboards und Berichte,
- Erzeugung benutzerdefinierter Warnungen basierend auf der Serviceleistung,
- Lösen von Leistungsproblemen,
- und Erkennen von Trends und Mustern.
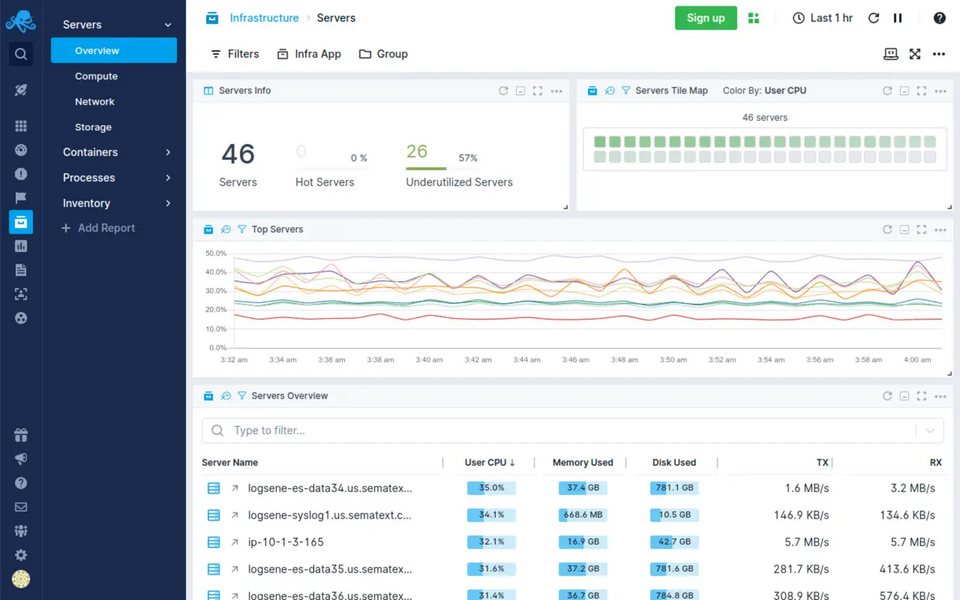
Quelle: Sematext
Das Log-Management wird vom Sematext Logs-Dienst durchgeführt, der Log-Nachrichten sammelt und mithilfe einer gehosteten Version des ELK-Stacks in der Cloud oder lokal in Echtzeit analysiert. Das Tool ermöglicht das Speichern, Indizieren und Suchen von Logs verschiedener Typen (Anwendung, Server, Container, benutzerdefiniertes Ereignis, mobile Applikationslogs) und das Aggregieren von Logs aus mehreren Quellen. Der Log-Sendungsprozess erfolgt über die Elasticsearch-API oder Syslog.
Alerts in Sematext werden verwendet, um über die Erfüllung mindestens einer der vordefinierten Bedingungen in Metriken, Logs oder Daten basierend auf historischen Daten zu benachrichtigen. Die wichtigsten Arten von Alerts umfassen:
- klassische Alerts – basierend auf Schwellenwerten und ausgelöst, wenn ein gegebener Schwellenwert überschritten wird,
- Anomalien – sie basieren auf Statistiken und werden ausgelöst, wenn Werte sich plötzlich ändern und von der kontinuierlich berechneten Basislinie abweichen,
- Heartbeat – aktiviert, wenn Sematext für einen bestimmten Zeitraum keine Daten mehr von dem Server, Container, der Applikation usw. erhält.
Warnungen integrieren z. B. mit Slack, PagerDuty, Teams, Google Chat sowie E-Mail.
Sematext entwickelt sich hauptsächlich in Richtung Cloud, daher arbeitet es sehr gut mit den größten Cloud-Providern, d. h. AWS, Microsoft Azure, Google Cloud Platform, DigitalOcean und IBM Cloud zusammen.
Sematext ist ein großer Spieler auf dem IT-Überwachungsmarkt, wie die Tatsache zeigt, dass zu seinen Kunden Unternehmen wie eBay, Dell, Instagram und Microsoft gehören. Für seine Kunden hat der Hersteller drei Pläne vorbereitet: Basic, Standard und Pro für jedes der vier Module: Logs, Monitoring, Experience, Synthetics. Jedes Modul kann in einem 14-tägigen Testzeitraum getestet werden. Sematext bietet die InfluxDB- und Elasticsearch-APIs für Metriken, Logs und Ereignisse, wodurch die Integration mit externen Systemen erleichtert wird.
Tools zur Überwachung der Serververfügbarkeit – Zusammenfassung
Ein Serverüberwachungssystem ermöglicht die ununterbrochene Kontrolle der IT-Umgebung. Die richtige Auswahl und Implementierung eines Überwachungstools gewährleistet die ordnungsgemäße Wartung von Diensten sowie Sicherheit, Stabilität und Komfort beim Betreiben eines Unternehmens. Eine angemessene Konfiguration mit der Alarmierungsfunktion ermöglicht eine schnelle Reaktion, noch bevor ein Problem in der Infrastruktur auftritt. Im Rahmen unserer DevOps-Dienste können wir Ihnen bei der Auswahl und Implementierung einer Lösung helfen, die den Bedürfnissen Ihres Unternehmens am besten gerecht wird.









