
Reliable environment powered by AWS

Websites play an increasingly important role on the Internet, sometimes even generating huge profits. Even the smallest interruptions in their operation can cause losses amounting to hundreds or even thousands of dollars. That is why when performing Drupal development services we attach great importance to ensuring that our work is as reliable as possible. How? Thanks to solutions that guarantee high availability, offered by Amazon Web Services.
What is high availability?
For the purpose of this article, we’ll define high availability as a requirement for a website concerning its operating time, defined as a percentage of the operating time in a month. 100% availability means that users can use the website for 43,200 minutes, or exactly 30 days in a month.
If for some reason, no matter whether it is an update, failure or attack, the website does not function properly for 12 hours, the availability parameter will be 98.3% (42,480 minutes out of 43,200).
What is the level of availability required?
There is no clear answer to this question, as it depends mainly on the requirements defined by the customer, and if they did not specify this parameter, we will have to do it ourselves. In this case, it is worth answering these two simple questions:
- how much time is required for website updates (requiring the website to be switched off for users)?
- how much time should be spent on other activities that require the website to be switched off?
The sum of two answers, increased by a possible security buffer, allows you to determine the desired availability time. At Droptica, for our key websites, this parameter is 99.99%, which translates into only 4 minutes of no access to services throughout the whole month!
What distinguishes HA infrastructure?
In the standard approach, used on many hosting platforms, we are dealing with a single server, on which all the applications necessary to provide the services – such as HTTP server (apache2 or nginx), MySQL, sometimes also solr, redis, memcached and, of course, disk space – are configured. A diagram of such a solution is shown in the picture below.
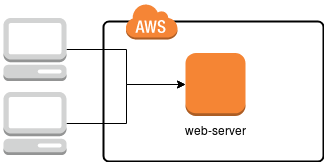
In this case, it is enough to damage one server (or one of the installed components) to render the website maintained on it inaccessible, thus reducing the availability time. How can this be prevented? Simply duplicate the infrastructure in such a way that if one of the servers fails, another one will take over, as shown in the diagram below.
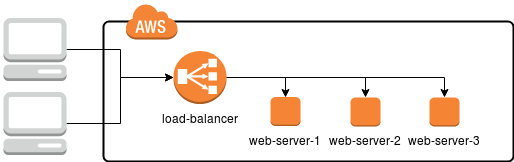
Thanks to this approach, each web server has the same functionality and provides exactly the same services. However, between the server and the user there’s also a load balancer, a special server tasked with receiving user's request and directing it to one of the three target machines.
Despite the fact that in our diagram, the load-balancer looks like a single element and may seem to be the most vulnerable node and a single point of failure, in reality, Amazon provides a range of scalable, efficient and reliable solutions for load balancers:
Practical example
In Droptica we created the pattern which in most cases is more than enough for the needs of our clients. Infrastructure like the one on the picture below ensures the redundancy and high availability with minimal costs.
To achieve said result we use:
- EC2 machines - the base of all of the environment, they are virtual machines where the services are running,
- Application Load Balancer (ALB) - load balancer, dynamically redirecting requests between instances EC2, checks for malfunctions and supports the HTTPS connection,
- Relational Database Service (RDS) - distributed end-to-end database service (MySQL),
- Elastic File System (EFS) - distributed file system, where the shared data (i.e. pictures, films and others) is stored
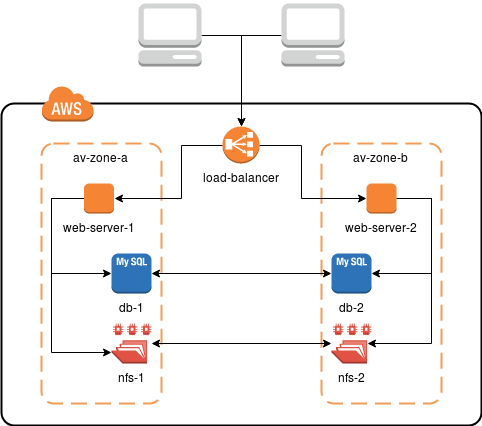
In the example above all components of the infrastructure are defined in different availability zones. Physically, they are two different data centers connected by stable and fast links. With EFS and RDS we don't have to worry about configuration and synchronization of the data. We just use them. From RDS we receive data to MySQL, while EFS is mounted just like ordinary NFS share.
Problems with high availability
Implementation of high availability systems not only brings a lot of benefits but can also cause many problems. This is because you need to introduce much more complex structures into the environment.
One of the first processes that become considerably more complicated is application deployment, which has to be adapted to support multiple servers, so as not to lead to a situation where the application updates its database on one host, while the other one is serving content to the users.
When it comes to differences between particular services, there is an issue with services that operate on files, such as Solr. Running three independent instances will lead to situations where some of them are more or less up to date than others. This can be resolved thanks to a shared filesystem (NFS, EFS, etc.), a Solr cluster or dedicated solutions such as CloudSearch.
Browsing logs also become much more difficult. The traffic related to a specific user session is directed to different servers, therefore making a central login point based on, for example, Logstash is a good practice.
Costs are also a major drawback of implementing high availability infrastructure. Most servers and services must be set up in parallel, at least doubled, and sometimes in greater numbers. In reality, these servers may be less efficient (after all, traffic is distributed proportionally), but in general, considering also the costs of application clusters, it will be more expensive, much more expensive. On the other hand, however, it is an investment that will result in less stress and certainty that, in the event of a breakdown, we will still be able to deliver content to the end-user.







