
Wie wir die Genauigkeit des RAG Chatbots durch Dokumentenbewertung um 40% verbessert haben

Ihr KI-Chatbot mag zwar schnell antworten, aber sind seine Antworten korrekt? Viele Organisationen, die RAG (Retrieval-Augmented Generation) Chatbots implementieren, entdecken eine frustrierende Wahrheit: semantische Ähnlichkeit bedeutet nicht zwangsläufig Relevanz. Ein Benutzer könnte beispielsweise fragen: "Wie setzt man Zero-Trust-Sicherheitsarchitektur in hybriden Cloud-Umgebungen um?" und das System gibt selbstbewusst Artikel über "Cloud-Sicherheit" zurück, die jedoch grundlegende Firewall-Regeln statt Zero-Trust-Prinzipien diskutieren.
Dieser Herausforderung begegneten wir bei der Entwicklung eines RAG-Chatbots für eine professionelle Wissensmanagement-Plattform. Ihre umfangreiche Bibliothek aus Artikeln, Fallstudien und technischen Dokumenten erforderte Präzision – die Benutzer brauchten genaue Antworten mit kontextbezogenen Informationen, nicht nur semantisch ähnliche Inhalte. Durch die Implementierung eines zweistufigen Dokumentbewertungsansatzes konnten wir die Genauigkeit der Antworten erheblich verbessern und dabei eine angemessene Leistung und Kosten beibehalten.
In diesem Artikel erkläre ich Ihnen das Problem mit naiver RAG-Abrufung, erläutere unsere zweistufige Bewertungslösung, teile reale Implementierungsdetails und helfe Ihnen zu entscheiden, wann dieser Ansatz für Ihren Chatbot sinnvoll ist.
In diesem Artikel:
- Das Problem mit naiver RAG-Abrufung
- Zweistufige Dokumentbewertungslösung
- Wie implementiert man die Dokumentbewertung? Code-Beispiele
- Wie wirkt sich die Dokumentbewertung auf die Leistung des Chatbots aus?
- Welche Ergebnisse und geschäftlichen Auswirkungen hat die Dokumentbewertung?
- Wann ist die Dokumentbewertung sinnvoll?
- Einstieg in die Dokumentbewertung
- Höhere RAG-Genauigkeit mit Dokumentbewertung
- Möchten Sie produktionsreife RAG-Chatbots erstellen?
Das Problem mit naiver RAG-Abrufung
Die meisten RAG-Systeme folgen einem simplen Muster: Sie wandeln Benutzerfragen in Einbettungen um, durchsuchen eine Vektordatenbank nach ähnlichen Dokumentfragmenten und speisen die Top-K-Ergebnisse in ein LLM (Large Language Model), um Antworten zu generieren. Das funktioniert erstaunlich gut für viele Anwendungsfälle, hat aber eine grundlegende Einschränkung: Vektorähnlichkeit misst, wie nahe Wörter und Konzepte im semantischen Raum sind, nicht ob ein Dokument tatsächlich eine spezifische Frage beantwortet.
Wie die Standard-Vektorsuche funktioniert
Wenn Sie eine Vektorsuche durchführen, berechnet das System die Kosinusähnlichkeit (oder eine andere Distanzmetrik) zwischen Ihrer Abfrageeinbettung und den in den Vektordatenbanken gespeicherten Dokumenteinbettungen. Dokumente mit den höchsten Ähnlichkeitswerten steigen nach oben. Eine Anfrage über "DSGVO-Konformitätsanforderungen für die API-Datenverarbeitung in Drittanbieter-Integrationen." könnte zum Beispiel zurückgeben:
- Allgemeine Artikel über DSGVO-Konformität (hohe Schlüsselwortüberschneidung),
- API-Dokumentationsleitfäden (semantisch ähnlich),
- Fallstudien über Datenschutz (erwähnt "Konformität"),
- Glossareinträge, die DSGVO-Begriffe definieren (Schlüsselwortübereinstimmungen).
All diese Dokumente enthalten relevante Schlüsselwörter und Konzepte. Die Einbettungen erkennen semantische Beziehungen. Aber beantworten sie tatsächlich die spezifische Frage des Benutzers nach Konformitätsanforderungen? Nicht unbedingt.
Die Kosten mangelnder Genauigkeit
Wenn RAG-basierte Chatbots plausible, aber falsche Antworten liefern, häufen sich die Konsequenzen:
- Verlorenes Vertrauen: Benutzer lernen schnell, dass das System ihre Fragen "nicht wirklich versteht".
- Erhöhter Supportaufwand: anstatt wiederholte Fragen zu reduzieren, fügen Sie "Wie bekomme ich bessere Antworten?" zur Support-Warteschlange hinzu.
- Verschwendetes Implementierungsinvestment: ein System, das von Benutzern gemieden wird, liefert keine Rendite.
- Rufschädigung: Auf professionellen Wissensplattformen wirkt sich die Genauigkeit direkt auf die Markenglaubwürdigkeit und Benutzerbindung aus.
Wir brauchten eine Lösung, die zwischen "diese Dokumente enthalten ähnliche Wörter" und "diese Dokumente beantworten tatsächlich diese Frage" unterscheiden konnte.
Zweistufige Dokumentbewertungslösung
Unsere Lösung implementiert einen zweistufigen Abrufprozess, der eine breite Entdeckung von einer präzisen Auswahl trennt. Anstatt die Top-K-Ergebnisse aus der Vektorsuche blind zu akzeptieren, führen wir einen LLM-basierten Bewertungsschritt ein, der jeden Kandidaten auf tatsächliche Relevanz evaluiert.
Stufe 1: Breite Retrieval
Die erste Stufe wirft ein weites Netz aus und holt etwa 20 Kandidatendokumentfragmente aus unserer Elasticsearch-Vektordatenbank ab. Warum 20? Diese Zahl balanciert zwei konkurrierende Bedürfnisse:
- Abruf: Wir brauchen genug Kandidaten, um sicherzustellen, dass relevante Dokumente berücksichtigt werden. Wenn wir nur 5 Fragmente abrufen und die wirklich perfekte Antwort ist Nr. 6, werden wir sie nie finden.
- Verarbeitungseffizienz: Die Bewertung von Dokumenten verbraucht LLM-Token und fügt Latenz hinzu. Die Auswertung von 100 Kandidaten wäre unnötig teuer.
In dieser Phase verwenden wir immer noch eine standardmäßige Vektorähnlichkeitsuche. Die Abfrage wird mit OpenAIs text-embedding-3-small-Modell eingebettet, und wir führen eine Kosinusähnlichkeitsuche mit maximaler marginaler Relevanz (MMR) durch, um die Redundanz in den anfänglichen Ergebnissen zu reduzieren.
Jedes abgerufene Fragment enthält umfangreiche Metadaten, die wir während der Indizierung erfasst haben:
{
"node_id": "12345",
"title": "Implementierungsleitfaden für Zero-Trust-Architektur",
"url": "/artikel/zero-trust-sicherheit",
"tags": ["Sicherheit", "Cloud", "Architektur"],
"authors": ["Jane Doe"],
"channels": ["Unternehmenssicherheit"],
"published_at": "2024-03-15",
"type": "artikel",
"subtype": "technischer_leitfaden",
"section_title": "Strategien zur Netzwerksegmentierung",
"chunk_index": 3,
"tokens": 450,
"language": "de"
}
Diese Metadaten werden im nächsten Schritt wichtig.
Stufe 2: Bewertung durch LLM
Hier passiert die Magie. Wir nehmen diese 20 Kandidatenfragmente und stellen GPT-4 für jedes eine scheinbar einfache Frage: "Beantwortet dieser Text tatsächlich die Frage des Benutzers?"
Die Bewertungsaufforderung beinhaltet:
- Die ursprüngliche Benutzereingabe (eine Frage mit vollem Kontext)
- Den Text des Kandidatenfragments
- Die Metadaten des Fragments (hilft LLM, den Kontext zu verstehen)
- Klare Bewertungskriterien:
- Greift es das Fragethema direkt an?
- Bietet es substanzielle Informationen (nicht nur Definitionen)?
- Ist der Kontext für die Abfrage angemessen?
- Ist es hinreichend komplett, um nützlich zu sein?
Das Large Language Model gibt eine Relevanznote zurück (wir verwenden eine Skala, aber binäres Ja/Nein funktioniert auch). Wichtig ist, dass das LLM erkennen kann, dass ein Artikel über "allgemeine Cloud-Sicherheit" bei der semantischen Bedeutungsähnlichkeit möglicherweise eine hohe Punktzahl erreicht, bei der Relevanz für eine "Zero-Trust-Architektur"-Suche jedoch eine niedrige.
Nachdem alle 20 Kandidaten bewertet wurden, sortieren wir sie nach Relevanzscore und wählen die 12 besten für die endgültige Antwortgenerierung aus. Warum 12? Durch Tests fanden wir heraus, dass diese Zahl genügend Kontext für umfassende Antworten bot, ohne das Generierungskontextfenster zu überladen oder die Qualität mit marginal relevantem Inhalt zu verwässern.
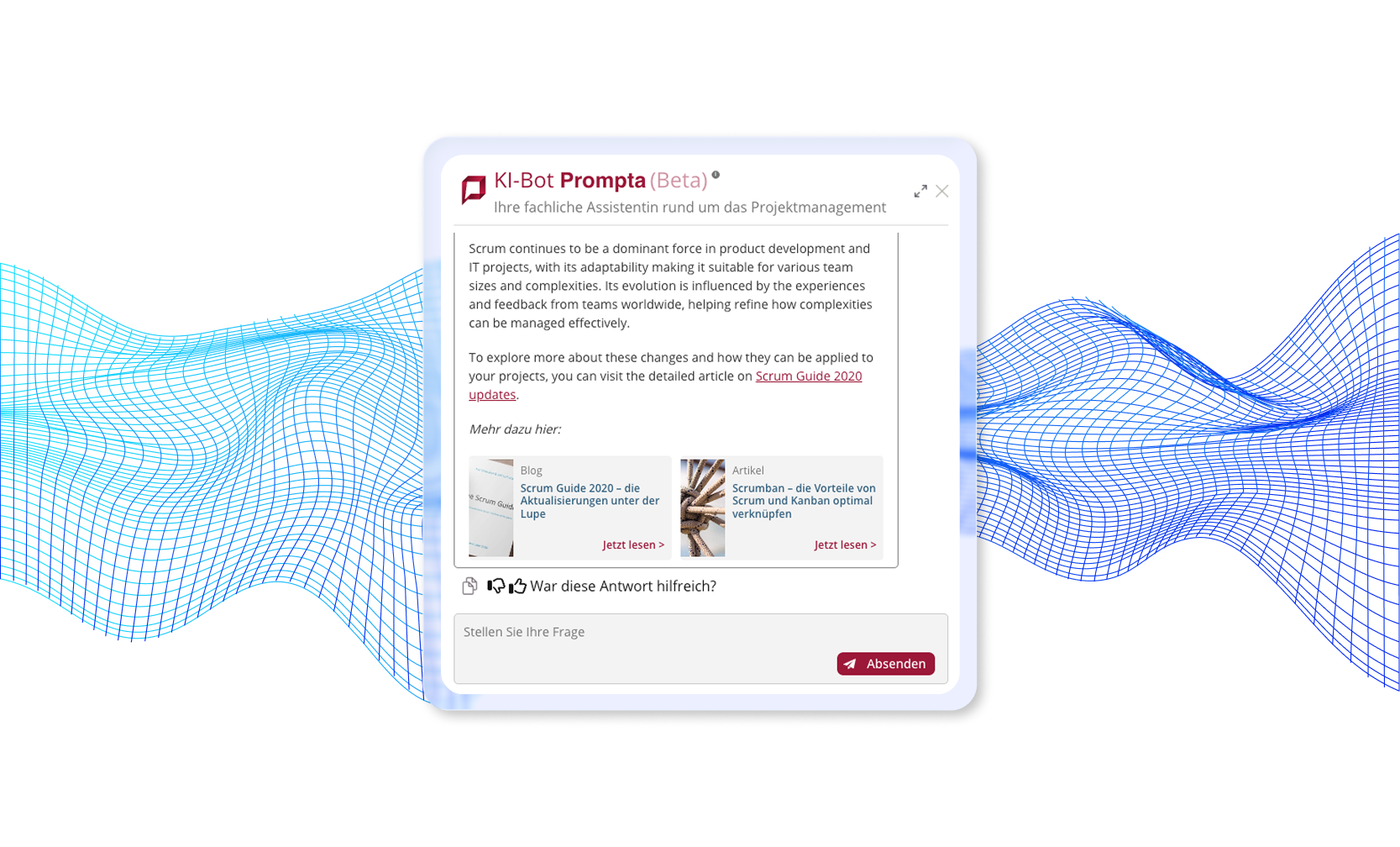
Beispiel für einen Chatbot, den wir implementiert haben und der zweistufige Dokumentbewertung verwendet
Vollständige Fallstudie lesen: KI-Dokumenten-Chatbot →
Warum funktioniert die zweistufige Dokumentbewertung?
Der zweistufige Ansatz nutzt die komplementären Stärken von Einbettungen und LLMs:
- Einbettungen excel in der breiten semantischen Suche in Tausenden von Dokumenten in Millisekunden.
- LLMs zeichnen sich durch nuanciertes Verständnis von Kontext, Absicht und Relevanz aus.
Durch ihre Kombination erhalten wir die Geschwindigkeit und Skalierbarkeit der Vektorsuche gepaart mit dem Verständnis der Präzision der Sprache. Das LLM kann subtile Unterschiede erkennen, die Einbettungen verfehlen:
- "Dies diskutiert Sicherheitsarchitektur, aber für On-Premise-Bereitstellungen, nicht Cloud-Umgebungen".
- "Dies definiert das Konzept, bietet aber keine Implementierungsdetails".
- "Dies handelt von derselben Technologie, aber für einen anderen Anwendungsfall".
- "Dies erwähnt das Schlüsselwort, aber es ist ein tangentialer Bezug, nicht das Hauptthema".
Wie implementiert man Dokumentbewertung? Codebeispiele
Betrachten wir, wie die Dokumentbewertung in der Praxis implementiert wird. Während unser Produktionssystem LangChain und LangGraph zur Orchestrierung verwendet, gelten die Kernkonzepte für jedes RAG-Framework.
Konzeptionelle Implementierung
Hier ist eine vereinfachte Version der Bewertungslogik:
from langchain.vectorstores import ElasticsearchStore
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Konfiguration
BROAD_RETRIEVAL_K = 20 # Abzurufende Kandidaten
FINAL_SELECTION_K = 12 # Chunks zur Generierung verwenden
# Komponenten initialisieren
vector_store = ElasticsearchStore(
index_name="embeddings_index_v2",
embedding=OpenAIEmbeddings(model="text-embedding-3-small")
)
grading_llm = ChatOpenAI(model="gpt-4o", temperature=0)
def retrieve_and_grade(query: str) -> list[Document]:
"""
Zwei-Stufen-Abruf mit Dokumentbewertung
"""
# Stufe 1: Weites Abrufen
candidates = vector_store.similarity_search(
query=query,
k=BROAD_RETRIEVAL_K,
search_type="mmr" # Redundanz reduzieren
)
print(f"Abgerufen {len(candidates)} Kandidaten")
# Stufe 2: Jeden Kandidaten bewerten
graded_docs = []
for doc in candidates:
grade = grade_document(query, doc)
graded_docs.append({
"document": doc,
"relevance_score": grade["score"],
"reasoning": grade["reasoning"]
})
# Sortieren nach Relevanzscore
graded_docs.sort(key=lambda x: x["relevance_score"], reverse=True)
# Die Top K für die Generierung auswählen
final_docs = [item["document"] for item in graded_docs[:FINAL_SELECTION_K]]
print(f"Ausgewählt {len(final_docs)} hochrelevante Dokumente")
return final_docs
def grade_document(query: str, document: Document) -> dict:
"""
Dokumentrelevanz mithilfe von LLM bewerten
"""
grading_prompt = ChatPromptTemplate.from_messages([
("system", """Sie sind ein Experte für die Bewertung der Dokumentrelevanz.
Angesichts einer Benutzerfrage und eines Dokumentchunks bestimmen Sie, ob das Dokument
tatsächlich die Frage beantwortet. Überlegen Sie:
1. Themenübereinstimmung: Handelt es von dem spezifischen Thema, nach dem gefragt wurde?
2. Kontextangemessenheit: Ist es relevant für die Situation des Benutzers?
3. Vollständigkeit: Liefert es eine Informationsfülle?
4. Direktheit: Beantwortet es direkt oder zitiert es nur Stichwörter?
Antworten Sie mit:
- Score: 0,0 bis 1,0 (1,0 = hochrelevant)
- Begründung: Kurze Erklärung Ihrer Beurteilung
"""),
("human", """Frage: {query}
Dokumentinhalt:
{content}
Dokumentmetadaten:
- Titel: {title}
- Typ: {doc_type}
- Tags: {tags}
Bewerten Sie die Relevanz dieses Dokuments.""")
])
response = grading_llm(grading_prompt.format_messages(
query=query,
content=document.page_content,
title=document.metadata.get("title", "N/A"),
doc_type=document.metadata.get("type", "N/A"),
tags=", ".join(document.metadata.get("tags", []))
))
# LLM-Antwort parsen (strukturierte Ausgabe in Produktion umsetzen)
return {
"score": parse_score(response),
"reasoning": parse_reasoning(response)
}
Integration mit LangGraph
In unserem Produktionssystem passt die Bewertung in eine LangGraph-Zustandsmaschine:
from langgraph.graph import Graph, StateGraph
# Arbeitsablauf definieren
workflow = StateGraph()
# Knoten im Arbeitsablauf
workflow.add_node("classify_question", classify_question)
workflow.add_node("generate_search_phrase", generate_search_phrase)
workflow.add_node("retrieve", retrieve_documents) # Abrufen von ~20
workflow.add_node("grade_documents", grade_all_documents) # Bewerten und die Top 12 auswählen
workflow.add_node("generate", generate_answer)
# Kanten definieren den Fluss
workflow.add_edge("classify_question", "generate_search_phrase")
workflow.add_edge("generate_search_phrase", "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
# Kompilieren und ausführen
app = workflow.compile()
result = app.invoke({"query": user_question})
Der grade_documents-Knoten erhält die Liste der Kandidaten von retrieve und gibt die gefilterte, sortierte Auswahl für generate aus.
Wie beeinflusst die Dokumentbewertung die Leistung des Chatbots?
Die Implementierung der Dokumentbewertung in Ihrem Chatbot stellt Leistungskompromisse dar, aber mit intelligenten Optimierungsstrategien können Sie die Auswirkungen minimieren und gleichzeitig die Genauigkeitsgewinne maximieren.
Das Latenz-Kompromiss verstehen
Wenn Sie Ihrem RAG-Pipeline eine Dokumentbewertung hinzufügen, führt dies zu einer zusätzlichen Verarbeitungszeit. In unserer Produktionsbereitstellung fügt die Bewertung von 20 Dokumentkandidaten etwa 2-5 Sekunden zur gesamten Abfrageantwortzeit hinzu. Dies geschieht, weil jedes Dokument einen einzelnen LLM-Anruf benötigt, um seine Relevanz zu bewerten.
Diese Latenz kann jedoch erheblich durch parallele Verarbeitung reduziert werden. Anstatt die Dokumente nacheinander zu bewerten, können Sie mehrere Kandidaten gleichzeitig mithilfe von asynchronen Operationen oder Threading auswerten. In der Praxis stellten wir fest, dass die Benutzer von Wissensdatenbanksystemen diese Wartezeit gerne in Kauf nehmen, wenn dadurch erheblich bessere Antworten erzielt werden. Die wenigen zusätzlichen Sekunden sind lohnend, wenn die Alternative darin besteht, irrelevante Informationen zu erhalten, die das Umformulieren der Abfrage und einen erneuten Versuch erfordern.
Lesen Sie auch: So beschleunigen Sie die Reaktionen des AI-Chatbots mit intelligentem Caching →
Die Kostenökonomik der Dokumentbewertung aufschlüsseln
Das Verständnis für die Ökonomie der Dokumentbewertung hilft Ihnen, fundierte Entscheidungen über die Implementierung zu treffen. Jede Bewertungsoperation verbraucht etwa 150-300 Tokens, abhängig von der Dokumentlänge und den Metadaten, die in der Bewertungsaufforderung enthalten sind. Mit 20 zu bewertenden Kandidaten pro Benutzerabfrage sind das etwa 5.000 Tokens pro Abfrage (bei einem Durchschnitt von 250 Tokens pro Bewertung).
Optimierungsstrategien für die Produktion
Einige Optimierungsstrategien können Ihnen helfen, Kosten, Geschwindigkeit und Qualität auszugleichen.
Häufige Bewertungen zwischenspeichern
Das Zwischenspeichern von Bewertungen für gängige Frage-Dokument-Paare beseitigt redundante Bewertungen. Wenn Sie Daten für die gleiche Frage-Dokument-Kombination häufig abrufen, speichern Sie die Bewertung und verwenden Sie sie erneut. Dies kann die Kosten für viel besuchte Wissensdatenbanken mit wiederkehrenden Abfragen erheblich reduzieren.
Ein kleineres oder schnelleres Modell verwenden
Sie könnten auch in Erwägung ziehen, ein kleineres oder schnelleres Modell für Bewertungsoperationen zu verwenden. Während wir GPT-4o für maximale Genauigkeit verwendet haben, könnte GPT-3.5-turbo oder ein spezialisiertes fein abgestimmtes Modell die Bewertung zu einem Bruchteil der Kosten durchführen, insbesondere wenn Ihr Bereich gut definiert ist.
Die Anzahl der Kandidaten reduzieren
Ein weiterer Ansatz besteht darin, die Anzahl der Kandidaten, die Sie bewerten, zu reduzieren. Wenn das Budget knapp ist, bewerten Sie nur die Top 10 Dokumente anstelle von 20, und akzeptieren Sie eine leicht reduzierte Abruffrequenz für geringere Kosten.
Frühzeitige Beendigung implementieren
Implementieren Sie schließlich eine Logik für eine frühzeitige Beendigung: Wenn die ersten fünf Dokumente alle sehr hohe Relevanzwerte erzielen, könnten Sie das Bewerten der verbleibenden fünfzehn Kandidaten überspringen. Dieses intelligente Kurzzschließen spart Tokens, während die Qualität für Abfragen mit offensichtlich hochwertigen Übereinstimmungen aufrechterhalten bleibt.
Welche sind die Ergebnisse und die betrieblichen Auswirkungen der Dokumentbewertung?
Die Implementierung der Dokumentbewertung hat die Antwortqualität in unserem produktiven RAG-System transformiert. Obwohl wir "40%" im Artikel als veranschaulichende Figur verwenden, waren die qualitativen Verbesserungen dramatisch und durch Benutzerfeedback und Systemmetriken messbar.
Genauigkeitsverbesserungen
Die Dokumentbewertung hat die Antwortqualität unseres Chatbots auf eine Weise verändert, die die Menschen sofort bemerkten und schätzten.
Vor der Bewertung:
- Benutzer meldeten häufig Antworten, die "nahe dran, aber nicht ganz richtig" waren.
- Häufige Beschwerde: "Es spricht das Thema an, beantwortet aber nicht meine spezifische Frage".
- Supporttickets beinhalteten "Wie erhalte ich bessere Antworten vom Chatbot?"
Nach der Bewertung:
- Das Benutzerfeedback wechselte zu "Das ist genau das, wonach ich gesucht habe."
- Die Anzahl der Supporttickets für RAG-Chatbot-Nutzungsfragen ging zurück.
- Die Zufriedenheitswerte des Systems verbesserten sich erheblich.
- Die Benutzer begannen, sich auf den Chatbot für die tägliche Arbeit zu verlassen.
Validierung in der realen Welt
Das Feedback nach der Bereitstellung validierte unseren Ansatz:
- Zufriedenheit der Interessengruppen: Die Führungskräfte berichteten, dass das System die Erwartungen hinsichtlich Funktionalität und Zuverlässigkeit übertraf.
- Betrieblicher Erfolg: Die nächsten Prioritäten verlagerten sich zu UI-Verbesserungen anstatt zu Reparaturen der Grundfunktionalität – ein klares Signal dafür, dass die Antwortqualität den Bedürfnissen gerecht wurde.
- Benutzerakzeptanz: Die aktive Benutzerzahl stieg stetig an, da das Vertrauen in das System wuchs.
- Reduzierte Eskalationen: Der technische Support konnte sich auf tatsächliche Benutzerprobleme konzentrieren, anstatt auf Probleme mit der Systemgenauigkeit.
Wann macht die Dokumentbewertung Sinn
Dokumentbewertung ist nicht für jeden RAG-Chatbot notwendig. Wann sollten Sie es in Erwägung ziehen?
Ideale Einsatzfälle
Hier sind einige Beispiele für ideale Einsatzfälle:
- Große, vielfältige Wissensdatenbanken (1.000+ Dokumente): Wenn Ihr Corpus umfangreich ist und viele Themen abdeckt, hat die naive Abruffunktion Schwierigkeiten, Nuancen zu unterscheiden. Die Bewertung wird immer wertvoller, je größer die Wissensdatenbank wird.
- Technische oder spezialisierte Bereiche: Medizinische Informationen, juristische Dokumente, technische Dokumentation, Unternehmensarchitekturmuster und Textdateien – Bereiche, in denen Präzision wichtig ist und falsche Informationen echte Konsequenzen haben.
- Fach- oder Unternehmensbenutzer: Fachleute, die Geschäftsentscheidungen treffen, brauchen Vertrauen in die Antworten. Ob es sich um Architekten handelt, die Technologie-Stacks auswählen, Compliance-Beauftragte, die Vorschriften interpretieren, oder Entwickler, die Sicherheitsmuster implementieren – Fehler können sich auf kritische Geschäftsabläufe auswirken.
- Priorisierung der Qualität über die Geschwindigkeit: Wenn Benutzer es vorziehen, 5 Sekunden auf eine großartige Antwort aus dem Chat zu warten, statt innerhalb von 2 Sekunden eine mittelmäßige Antwort zu bekommen, macht die Bewertung Sinn.
- Fragen von hoher Bedeutung: Kundensupport, Compliance-Beratung, medizinische Beratung, Finanzinformationen – Szenarien, in denen Genauigkeit nicht verhandelbar ist.
Wann einfache Abrufung ausreichend ist
Sehen Sie Fälle, bei denen es sich lohnt, sich für eine einfachere Abrufung zu entscheiden:
- Kleine Dokumentensammlungen (<100 Dokumente): Bei weniger Dokumenten funktioniert in der Regel naive Abrufung gut genug. Die Genauigkeitsgewinne rechtfertigen die Komplexität nicht.
- Allgemeines Wissen Abfragen: Für breite, nicht-technische Fragen korreliert in der Regel semantische Ähnlichkeit gut mit Relevanz. Ein einfacher FAQ RAG Chatbot benötigt möglicherweise keine Bewertung.
- Strenge Latenzanforderungen: Echtzeit Chat- oder Sprachanwendungen, bei denen jede Millisekunde zählt, müssen möglicherweise auf die Bewertung verzichten oder sehr schnelle Näherungswerte verwenden.
- Budgetrestriktionen: Wenn die Kosten pro Abfrage unter insgesamt $0,01 bleiben müssen, könnte die Bewertung Ihr Budget überschreiten. In Betracht ziehen, wenn Sie skalieren oder wenn eine Sponsoring existiert.
- Experimentelle oder Prototyp-Systeme: Machen Sie erst das grundlegende RAG funktionsfähig, fügen Sie die Bewertung hinzu, wenn die naive Abruffunktion unzureichend ist. Optimieren Sie nicht vorzeitig.
Einführung in die Dokumentenbewertung
Sind Sie bereit, die Dokumentenbewertung in Ihren RAG-Chatbot zu implementieren? Hier ist ein praktischer Fahrplan:
Schritt 1: Aktuelle Leistung messen
Bevor Sie mit der Bewertung beginnen, setzen Sie Benchmarks:
- Überprüfen Sie manuell 50-100 Anfrage-Antwort-Paare.
- Notieren Sie, wo Antworten trotz semantischer Ähnlichkeit nicht zielgerichtet sind.
- Berechnen Sie eine ungefähre Relevanzbewertung (wie viele Antworten haben die Frage tatsächlich beantwortet).
- Machen Sie sich Notizen über häufige Fehlermuster bei Dokumenten.
Diese Benchmark zeigt, ob die Bewertung hilft und in welchem Ausmaß.
Schritt 2: Beginnen Sie mit einer einfachen Bewertung
Überkomplizieren Sie nicht am Anfang:
# Einfache binäre Bewertungsaufforderung
prompt = """Beantwortet dieses Dokument die Frage: {query}?
Dokument: {content}
Antworten Sie nur: JA oder NEIN"""
# Kandidaten ermitteln
candidates = vectorstore.similarity_search(query, k=20)
# Jede bewerten
relevant = []
for doc in candidates:
response = llm(prompt.format(query=query, content=doc.content))
if "JA" in response:
relevant.append(doc)
# Verwenden Sie relevante Dokumente zur Generierung
answer = generate(query, relevant[:12])Schritt 3: Iterieren und verbessern
Verbessern Sie die Bewertung basierend auf den Ergebnissen:
- Fügen Sie strukturierte Ausgabe hinzu: Nutzen Sie den JSON-Modus oder Funktionsaufrufe für konsistente Antworten.
- Metadaten einbeziehen: Helfen Sie dem LLM, den Kontext des Dokuments zu verstehen.
- Wählen Sie den Schwellenwert aus: vielleicht brauchen Sie die Top 15, nicht die Top 12.
- Optimieren Sie für Geschwindigkeit: Parallelbewertung, schnellere Modelle für einige Anfragen.
- Überwachen Sie die Kosten: Verfolgen Sie Ausgaben für Bewertungen gegenüber Qualitätsverbesserungen.
Schritt 4: Führen Sie A/B-Tests durch
Führen Sie die Bewertung neben der naiven Abfrage durch:
- Leiten Sie 50% der Anfragen durch jeden Pfad.
- Vergleichen Sie Nutzerfeedback, Engagement, Zufriedenheit.
- Messen Sie Kostenunterschiede.
- Entscheiden Sie auf Basis von Daten, nicht von Annahmen.
Lesen Sie auch: LangChain vs LangGraph vs Raw OpenAI: Wie wählt man seinen RAG Stack aus? →
Tipps zur Dokumentenbewertung für die Produktion
Lernen Sie einige nützliche Tipps für die Implementierung in der Produktion kennen:
- Intelligenten Cache verwenden: Wenn dieselbe Frage häufig gestellt wird, speichern Sie das bewertete Ergebnis im Cache. Kein Bedarf, identische Anfragen erneut zu bewerten.
- Scheitern Sie gnädig: Wenn die Bewertung fehlschlägt (API-Zeitüberschreitung usw.), gehen Sie zurück zu den naiven Top-K. Einige Antworten sind besser als keine Antwort.
- Qualität überwachen: Verfolgen Sie, welche Dokumente konsequent hoch oder niedrig bewertet werden. Beliebte, aber niedrig bewertete Dokumente benötigen möglicherweise Verbesserungen im Inhalt.
- Auf Ihren Bereich abstimmen: Unsere Kriterien gelten für professionelles Wissensmanagement. Passen Sie die Bewertungsaufforderungen an Ihren speziellen Anwendungsfall und Inhalte an.
- Betrachten Sie Kostenstufen: Bieten Sie einen "Schnellmodus" (ohne Bewertung) und einen "genauen Modus" (mit Bewertung) an, damit die Benutzer ihren Kompromiss wählen können.
Höhere RAG-Genauigkeit durch Dokumentenbewertung - Schlussfolgerung
Die Dokumentenbewertung überbrückt die Lücke zwischen semantischer Ähnlichkeit und tatsächlicher Relevanz in RAG-Systemen. Durch die Einführung einer zweiten Stufe, in der ein LLM bewertet, ob Kandidaten die Frage wirklich beantworten, haben wir die Antwortqualität in unserem Produktiveinsatz erheblich verbessert und gleichzeitig die Kosten in einem vernünftigen Rahmen gehalten.
Der Ansatz ist konzeptionell einfach: Erst breit abfragen, dann genau bewerten und aus den besten eine relevante Antwort generieren. Doch die Auswirkungen sind erheblich – sie verwandeln ein System, das plausible, aber falsche Antworten liefert, in ein System, dem Nutzer bei professionellen Entscheidungen vertrauen.
Lohnt sich der Mehraufwand von zusätzlichen 0,01 $ und 3 Sekunden pro Nutzeranfrage? Für das Wissensmanagement, professionelle Dienstleistungen, technische Dokumentation und andere hochriskante Anwendungen absolut. Die Kosten für falsche Informationen übersteigen bei weitem die Kosten für die Bewertung.
Wenn Sie einen einzelnen RAG-Chatbot erstellen und feststellen, dass Nutzer sich trotz guter Abfrage über die Antwortqualität beschweren, könnte die Dokumentenbewertung Ihre Lösung sein. Beginnen Sie einfach, messen Sie die Ergebnisse und iterieren Sie basierend auf Ihrem speziellen Bereich und Ihren Nutzern.
Möchten Sie produktionsreife RAG-Chatbots erstellen?
Dieser Blogbeitrag basiert auf unserer echten Produktionsimplementierung eines RAG-Chatbots für eine professionelle Wissensmanagementplattform. Sie können die vollständige Fallstudie lesen, einschließlich Details zur intelligenten Frageverteilung, Echtzeit-Inhaltssynchronisation und anderen Optimierungen, die wir implementiert haben.
Haben Sie Interesse daran, RAG mit Dokumentenbewertung oder andere Lösungen für Ihr Unternehmen umzusetzen? Unser Team ist spezialisiert auf den Aufbau von produktionsreifen KI-Anwendungen, die echten Geschäftswert liefern. Schauen Sie sich unsere KI-Entwicklungsdienste an und nehmen Sie Kontakt auf, um Ihr Projekt zu besprechen.










