
AI Terms You Need to Know. Part One – 13 Basic Artificial Intelligence Phrases

After the „AI revolution of 2022,” there is one simple conclusion – AI isn’t a fad that will go away anytime soon, but it will stay with us for some time. This spawned new positions within the industry and a lot of new phrases. There are many terms when discussing AI. Some of them are self-explanatory, and some can be confusing and unclear. Hopefully, after reading our articles on this topic, you won’t be surprised when someone throws this new terminology at you.
Basic artificial intelligence terms
We divide the explanation of AI terms into two parts. In this article, we'll cover some basic artificial intelligence terms that will help you stay on top of the conversation and ground your understanding of AI-related knowledge. In the following article, we'll focus on more specialized terminology and explain the inner mechanisms of existing AI solutions.
Artificial Intelligence (AI)
Artificial Intelligence (AI) is a broad field of computer science aimed at creating machines capable of performing tasks that typically require human intelligence. This includes problem-solving, recognizing patterns, and understanding natural language. This term doesn’t cover only Artificial Neural Networks but also solutions like Genetic Algorithms, Fuzzy Logic, etc.
AI Model/Checkpoint/Model Deployment
This is one of the most confusing parts of general discourse.
- AI Model – this refers to the architecture of an artificial intelligence system. It includes the structure of the neural networks (like layers, neurons, etc.), the algorithms it uses, and the parameters that define its behavior. A model is a theoretical construct that defines how the AI processes input data to produce outputs.
- Checkpoint – a checkpoint is a saved state of a trained model at a specific point in time. It includes all the parameters, weights, and biases that the model has learned up to that point. Checkpoints are used to pause and resume training, for recovery in case of interruptions, and for deploying a trained model in different environments. They represent a specific instance of a model with its learned knowledge at a certain stage of training.
- Model Deployment – when you have a model, then you need to „deploy” it. This encompasses creating or using available applications or scripts (more on this in the second article) to provide an interface for interaction with the model. This also contains infrastructure like a server with GPU, web interface, or API for users to interact with the model.
To reiterate, when you say, „I’m using ChatGPT,” you‘re referring to the whole system that allows interaction with the „ChatGPT” model.
Big Data
This AI term refers to extremely large data sets that are so complex and voluminous that traditional data processing tools are inadequate to manage and analyze them.
The significance of Big Data lies not just in its size but also in its complexity and the speed at which it’s generated and processed. It’s traditionally characterized by what are known as the three V's – Volume, Velocity, and Variety:
- Volume – refers to the sheer size of the data collected from various sources like transactions, social media, sensors, etc. The growth in data volume has been facilitated by the availability of cheaper storage options like data lakes, Hadoop, and cloud storage.
- Velocity – this aspect of Big Data is about the speed at which data is generated and needs to be processed.
- Variety – Big Data comes in various formats – from structured, numeric data in traditional databases to unstructured text, videos, audio, and more.

Chatbot
It’s a software application designed to conduct online conversations either through text or text-to-speech, simulating human-like interaction. The first notable example was “Eliza,” created in 1966 by Joseph Weizenbaum. Eliza functioned by analyzing sentence patterns from user inputs and employing keyword substitution and word order rearrangement to craft responses, creating an illusion of understanding. Its "DOCTOR" script, mimicking a Rogerian psychotherapist, was particularly renowned for engaging users in seemingly meaningful conversations.
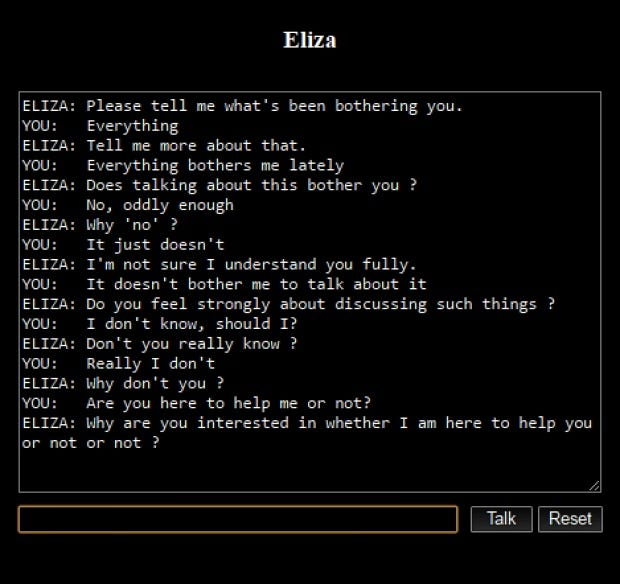
Source: medium.com
The field of chatbots has significantly evolved from these early examples. Modern chatbots like ChatGPT and Google Bard leverage advanced AI and machine learning technologies. These contemporary versions excel in understanding context, managing complex dialogues, and providing informative, coherent responses, far surpassing the capabilities of their predecessors.
Diffusion model
The diffusion model is a class of generative models. They usually consist of three major components: sampling, forward, and reverse process. In the modern context, this term usually refers to the image generation process.
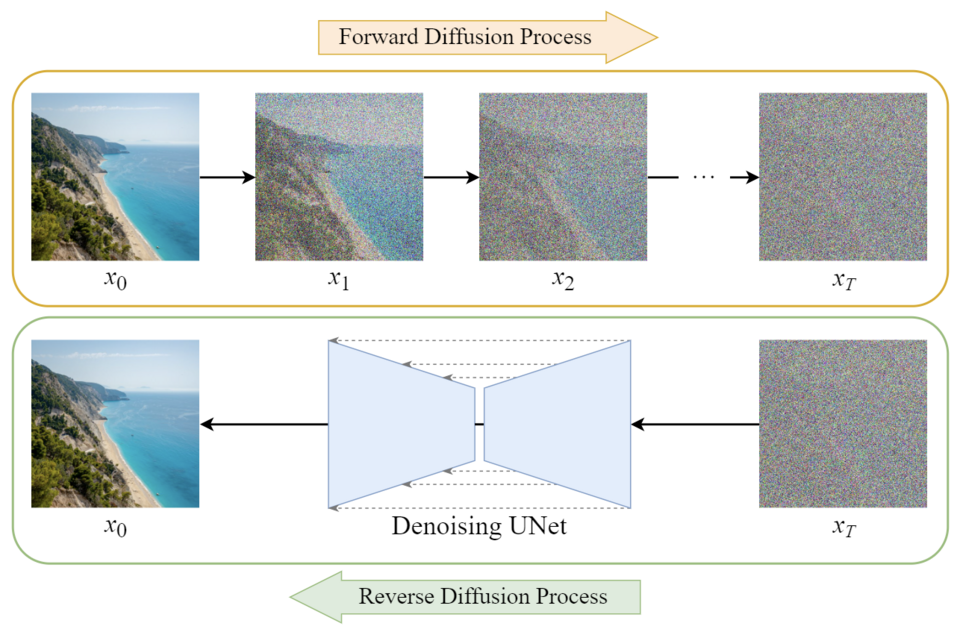
Source: towardsai.net
In the realm of image generation, diffusion models are trained on sets of images with added artificial noise. The model's task is to iteratively remove this noise, effectively "learning" to recreate the original image.
This process enables the model to generate new images based on a combination of user input and a sample of latent noise. The operation of diffusion models can be colloquially summarized by the phrase "I see a face in this rainbow," which metaphorically illustrates how these models discern structured images from seemingly random noise patterns.
Example of a diffusion model in action, generated in Midjourney
Fine-tuning
This AI phrase refers to the process of modifying an already trained AI model to adapt it to a new, specific dataset or task. This involves "inserting new knowledge" into the model. For instance, if you wish to adapt an OpenAI model to answer questions based on your website’s data, you would fine-tune the existing model with a dataset derived from your web page.
Fine-tuning can be time-consuming for larger models and often requires additional mechanisms to accommodate changes in data. For example, adding a new blog post to your website might necessitate retraining the model to incorporate this new information. Fine-tuning allows for the customization of AI models to specific domains or requirements without the need to train them from scratch.
Generative AI
The generative AI term refers to a subset of AI models. They’re designed to generate new content, drawing upon patterns and knowledge learned from their training data and user inputs. Such models are capable of creative tasks, such as writing new pieces with the tone of voice of specific authors or creating art and music that mimic certain styles.
For example, a model trained in the works of Shakespeare would be able to generate new poems or text passages that emulate his unique style and linguistic nuances. The key aspect of Generative AI is its ability to produce original outputs that are coherent and contextually relevant, often appearing as if a human created them.
A conversation with ChatGPT
Large Language Model (LLM)
This term describes a class of AI models that are trained on vast quantities of natural language data. Their primary function is to understand, process, and generate human-like text. LLMs achieve this by learning from a broad spectrum of language inputs and utilizing statistical probabilities to recreate and produce new content.
These models are not only adept at generating text that is coherent and contextually relevant. They’re also capable of performing various language-related tasks such as translation, summarization, and question-answering. The size and diversity of the training data enable these models to have a wide-ranging „understanding” of language, context, and nuances.
Natural Language Processing (NLP)
NLP is a field at the intersection of computer science, artificial intelligence, and linguistics. It focuses on enabling computers to understand, interpret, and generate human language in a valuable and meaningful way. Critical tasks in NLP include language translation, sentiment analysis, speech recognition, and text summarization.
The goal is to create systems that can interact with humans through language, extracting insights from text or speech data and generating human-like responses. NLP combines computational techniques with language-specific knowledge to effectively process and analyze large amounts of natural language data.
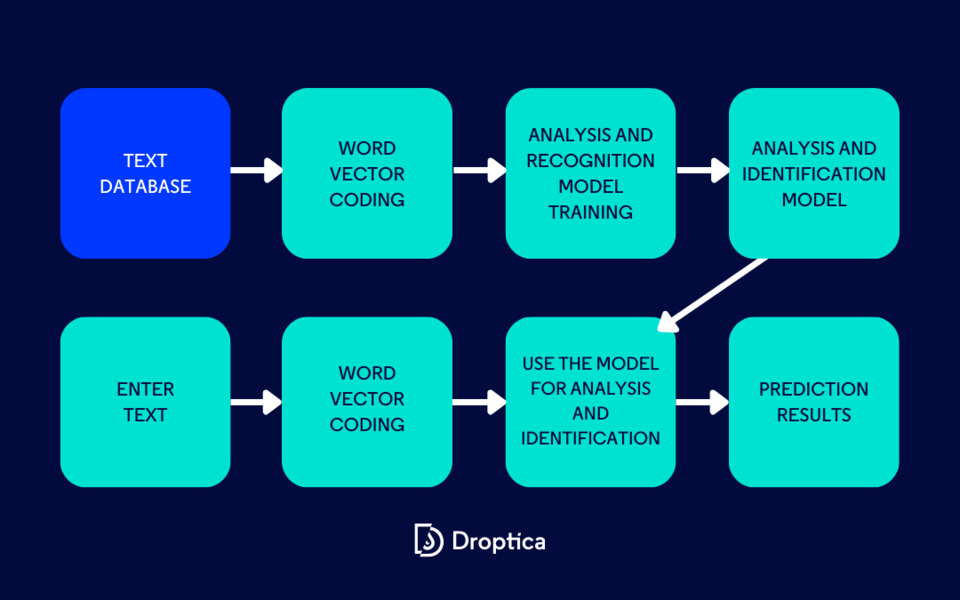
Optical Character Recognition (OCR)
OCR is the process of converting images of handwritten or printed text into machine-encoded text. Widely used as a form of data entry, it’s a common method used in digitizing printed text so it can be stored, edited, searched, or passed into a Large Language Model.
Prompt
In the context of AI, a prompt is a user-provided input that directs an AI model to generate a specific output. It acts as a guide or instruction to the AI, shaping its responses or the content it generates. Prompts can vary widely – from simple questions to complex scenarios – and are essential in determining how the AI model interprets and responds to user requests.
Prompt Engineering
This emerging field is centered around optimizing interactions with AI models to achieve desired outputs. Prompt engineering involves a deep understanding of how AI models process natural language and crafting prompts to guide the AI toward specific solutions or responses.
It's particularly relevant in the context of large language models, where the way a prompt is phrased can significantly impact the model's output. This field is gaining importance as AI systems become more prevalent and sophisticated, necessitating skilled techniques to effectively harness their capabilities.
Token
In the realm of Large Language Models, a token is a fundamental unit of text that the model processes. The concept of a token arises from the process of "tokenization," where the input text is divided into smaller pieces or tokens. These tokens are then used by the model to understand and generate text. It's important to note that a token doesn’t necessarily correspond to a single character. In English, for instance, a token might represent a word or part of a word, typically averaging around four characters in length.
The precise definition of a token can vary depending on the language model and the specifics of its tokenization algorithm. Tokens are crucial for models to process natural language inputs and generate coherent responses or text, as they determine the granularity at which the model interprets the input.
Basic AI terms – summary
In this article, we've uncovered the significance of AI terms and concepts and hopefully clarified some jargon and confusion. Understanding these basic phrases is essential for anyone who wants to get involved in the growing field of artificial intelligence – whether for career advancement or personal curiosity. If you need to turn any of these areas into a specific project, you can get help from our specialists experienced in AI development services.










