
AI-Begriffe, die Sie kennen müssen. Teil Zwei – 31 fortgeschrittene Phrasen und KI-Lösungen

Unser vorheriger Artikel über KI-Begriffe führte Sie in das grundlegende Wörterverzeichnis ein. In diesem Teil vertiefen wir uns in spezialisiertere Ausdrücke, die Ihnen helfen werden, den technischen Diskurs zu verstehen, und Ihnen ermöglichen, mit technikorientierteren Menschen über KI-Systeme zu diskutieren. Sie werden auch einige Erklärungen zu den inneren Abläufen bestehender KI-Lösungen wie ChatGPT, Stable Diffusion, HuggingFace usw. finden
Erweiterte KI-Begriffe
Unser früherer Artikel enthielt grundlegende KI-Begriffe, wie Big Data, Chatbot, Feinabstimmung und großes Sprachmodell (LLM). Dieser Blogbeitrag wird fortgeschrittenere Informationen präsentieren, aber das Verständnis dieser grundlegenden Terminologie wird von Vorteil sein
Künstliches Neuronales Netzwerk
Es ist ein Rechensystem, das von den biologischen neuronalen Netzwerken tierischer Gehirne inspiriert ist. Diese Netzwerke bestehen aus miteinander verbundenen Einheiten (Neuronen), die Daten verarbeiten und lernen können, Aufgaben auszuführen. Ein einzelnes Neuron wird als „Perzeptron“ bezeichnet. Es besteht aus Eingaben, die mit zugehörigen Gewichten multipliziert werden, einem Summationsknoten und einer Aktivierungsfunktion, die den Ausgang eines Neurons bestimmt.
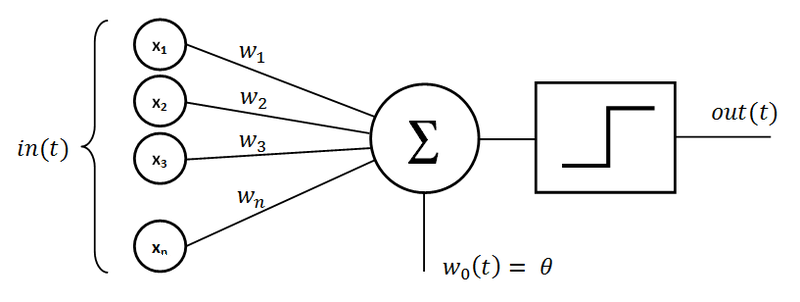
Quelle: wikipedia.org
Klassifikator
Ein Klassifikator ist eine Art von KI-Modell, das in der maschinellen Lernverarbeitung für Kategorisierungsaufgaben verwendet wird. Es weist Eingabedaten basierend auf erlernten Mustern Labels oder Kategorien zu. Klassifikatoren werden häufig in Anwendungen wie Spam-Erkennung, Bilderkennung und Stimmungsanalyse eingesetzt.
Kontextfenster
Dieser Begriff bezieht sich auf ein wesentliches Merkmal großer Sprachmodelle (LLMs), das bestimmt, wie viele Eingabedaten sie zu einem bestimmten Zeitpunkt berücksichtigen können. Das Kontextfenster stellt die Anzahl der Token dar, die ein LLM während einer Interaktion verarbeiten oder „merken“ kann. In der Praxis ist dieses Merkmal entscheidend, um die Kohärenz und Kontinuität von Gesprächen oder Textgenerierungsaufgaben aufrechtzuerhalten.
Während LLMs, wie die in der GPT (Generative Pre-trained Transformer) Serie, Eingaben verarbeiten, integrieren sie den Gesprächsverlauf zusammen mit neuen Eingaben. Ohne ein ausreichend großes Kontextfenster könnten diese Modelle jede Eingabe unabhängig behandeln, was zu Antworten führen könnte, die vom laufenden Gespräch losgelöst erscheinen. Die Größe des Kontextfensters wird normalerweise als Anzahl von Token angegeben.
Zum Beispiel, hat das GPT-3.5-turbo-Modell von OpenAI ein Kontextfenster von 16.385 Token. Das bedeutet, dass nach der Verarbeitung dieser Anzahl von Token (einschließlich Benutzereingaben und Modellantworten) das Modell beginnt, sich an die frühesten Teile der Interaktion zu „erinnern“. In solchen Fällen könnte es notwendig sein, wichtige Punkte des Gesprächs zu wiederholen oder zusammenzufassen, um das Modell mit dem Kontext der Diskussion im Einklang zu halten.
Im Vergleich dazu, kann das fortschrittlichere GPT-4-turbo-1106 mit einem erheblich größeren Kontextfenster von 128.000 Token aufwarten. Dieses weite Fenster ermöglicht viel längere Interaktionen und befähigt das Modell, ausgedehnte Texte, wie ein ganzes Buch wie „Harry Potter und der Gefangene von Askaban“, in einem einzigen Gespräch zu verarbeiten und darauf zu reagieren. Diese Weiterentwicklung verbessert erheblich die Fähigkeit des Modells, sich an detailreiche und weitläufige Dialoge zu beteiligen und relevantere sowie kontextbewusstere Antworten zu geben.
Die Bewältigung der Einschränkungen des Kontextfensters hat zu verschiedenen Lösungen geführt. Ein üblicher Ansatz ist das „rollende Kontextfenster“, bei dem dem Modell nur die letzten Token innerhalb der Begrenzung bereitgestellt werden, was effektiv die neuesten und relevantesten Teile des Gesprächs bewahrt. Hochentwickeltere Methoden umfassen die Verwendung eines anderen LLM-Verfahrens, um das Gespräch bis zu diesem Punkt zusammenzufassen, und die Optimierung der Nutzung von Token zur Kontexterhaltung.
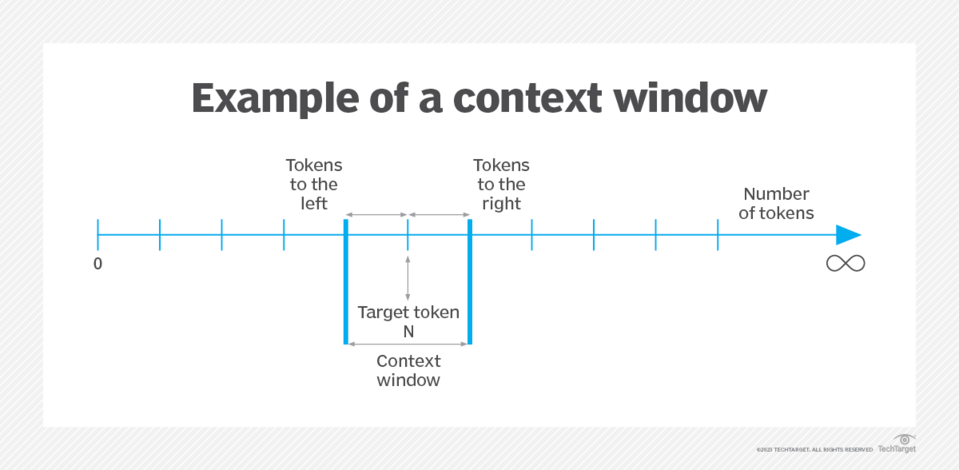
Quelle: techtarget.com
Deep Learning
Ein Teilbereich des maschinellen Lernens, Deep Learning nutzt neuronale Netzwerke mit mehreren Schichten („tief“) zur Analyse verschiedener Datenfaktoren. Es glänzt bei Aufgaben wie der Bilder- und Sprachanalyse, wo es komplexe Muster erlernen und Entscheidungen mit hoher Genauigkeit treffen kann.
Embedding
Im Kontext von KI und natürlicher Sprachverarbeitung bezieht sich Embedding auf den Prozess der Umwandlung von Daten, wie Text, in ein Set von Vektoren in einem hochdimensionalen Raum. Diese Transformation ermöglicht es, komplexe Daten wie Wörter, Sätze oder sogar ganze Dokumente in einem Format darzustellen, das KI-Modelle, insbesondere neuronale Netzwerke, verarbeiten können. Diese Vektordarstellungen erfassen semantische und syntaktische Beziehungen in den Daten, was dem Modell ermöglicht, natürliche Sprache effektiver zu verstehen und zu bearbeiten.
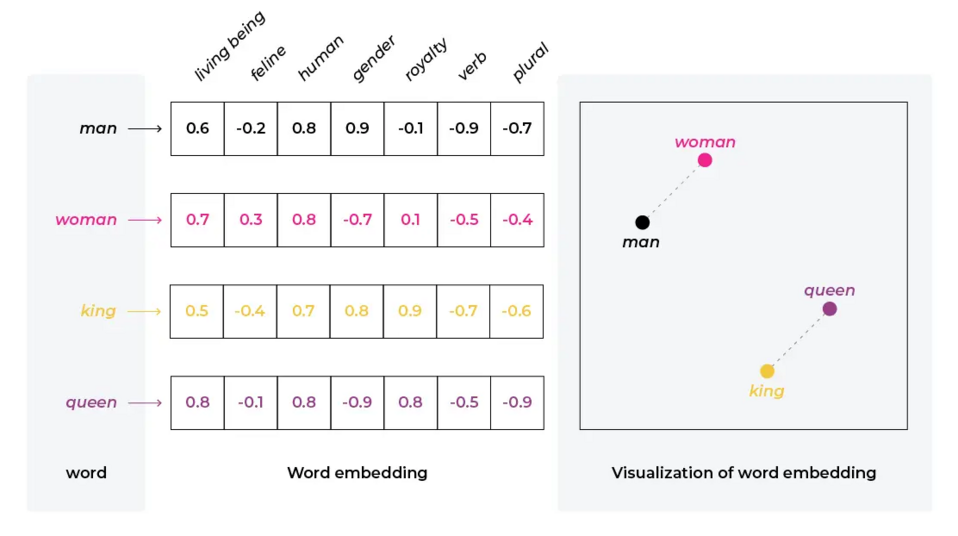
Beispiel der Vektordarstellung von Wörtern, Quelle: arize.com
Generative Pretrained Transformer
Ein Generativer Vorgeübter Transformer ist eine Reihe von großangelegten Sprachmodellen, die von OpenAI entwickelt wurden. GPT-Modelle sind auf vielfältigen Textdatensätzen trainiert und können menschenähnlichen Text generieren. Durch ihre Fähigkeit, kontextuell relevanten Text zu verstehen und zu erzeugen, sind sie in verschiedenen Sprachaufgaben vielseitig einsetzbar, einschließlich Übersetzung, Beantwortung von Fragen und Inhaltserstellung.
Halluzination
Im Bereich der großen Sprachmodelle (LLMs) bezieht sich Halluzination auf das Phänomen, bei dem das Modell falsche oder irreführende Informationen generiert, oft als Reaktion auf Fragen, die außerhalb des Trainingsdatensatzes liegen. Dieses Verhalten führt dazu, dass das Modell Details „erfindet“ oder falsche Informationen präsentiert. Zum Beispiel könnte ein LLM in Programmierkontexten nicht existierende Klassen oder Funktionen vorschlagen.
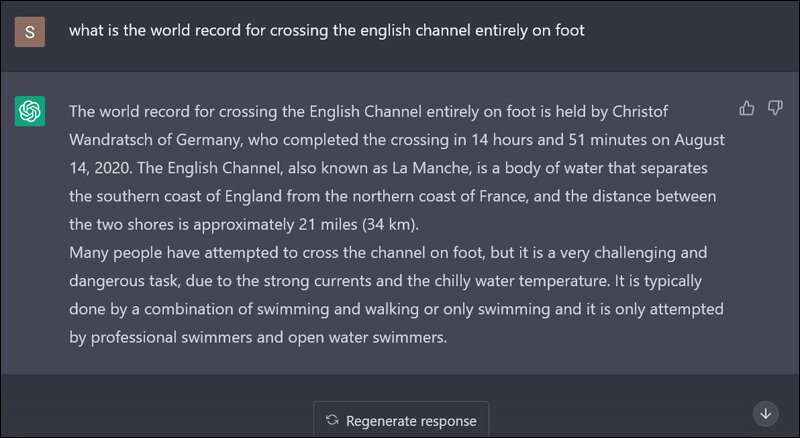
Beispiel für Halluzinationen, Quelle: sify.com
Ähnlich könnte es bei allgemeinen Wissensabfragen fälschlicherweise behaupten, dass Zair das einzige Land ist, das mit „Z“ beginnt, und Länder wie Simbabwe außer Acht lassen oder weglassen. Halluzinationen in LLMs heben die Einschränkungen dieser Modelle hervor, insbesondere wenn es um die Bewältigung von Fragen oder Aufgaben geht, die faktische Genauigkeit erfordern oder jenseits der Grenzen ihrer trainierten Wissensbasis liegen.
Hypernetzwerke
Dieser Begriff bezieht sich auf einen neuartigen Ansatz im Bereich der neuronalen Netzwerke, bei dem ein Netzwerk, bekannt als Hypernetzwerk, zur Erzeugung der Gewichte für ein anderes Netzwerk eingesetzt wird. Dieses Konzept führt eine zusätzliche Abstraktionsebene und Komplexität in das Design und das Training neuronaler Netzwerke ein.
In Hypernetzwerken liegt der primäre Fokus auf der Optimierung des Hypernetzwerks selbst, das die Konfiguration und Leistung des Zielnetzwerks bestimmt. Diese Methode kann potenziell die Effizienz des Trainings neuronaler Netzwerke verbessern und dynamischere und anpassungsfähigere Netzwerkverhalten ermöglichen.
Hypernetzwerke repräsentieren einen fortschrittlichen Bereich der Forschung über neuronale Netzwerke, der neue Wege erforscht, um die Beziehungen zwischen verschiedenen Netzwerken für effektivere Lern- und Problemlösungsstrategien zu nutzen. Für eine detaillierte Erkundung dieses Konzepts siehe dieses Forschungspapier auf arXiv.
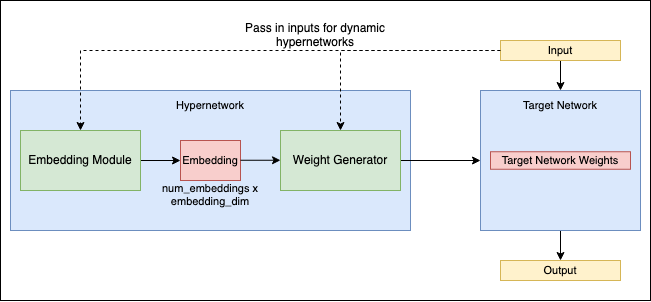
Quelle: github.com
Inferenz
In der KI bezieht sich die Inferenz auf den Prozess, bei dem ein trainiertes Modell Vorhersagen oder Entscheidungen basierend auf neuen, ungesehenen Daten trifft. Es ist die Phase, in der das Modell das Gelernte auf reale Anwendungen anwendet.
Latenter Raum
Im maschinellen Lernen bezieht sich der latente Raum auf eine komprimierte Darstellung der Eingabedaten, oft in einer niedrigdimensionalen Form. Es erfasst die wesentlichen Aspekte der Daten und wird in generativen Modellen verwendet.
Low-Rank Adaptation (LORA)
LORA stellt eine spezialisierte Technik dar, die hauptsächlich in Diffusionsmodellen genutzt wird, aber auch auf große Sprachmodelle (LLMs) anwendbar ist. Bei diesem Ansatz werden kleinere Hilfsmodelle entwickelt, die in Verbindung mit einem „Vollmodell“ arbeiten. Sie arbeiten, indem sie ihre Gewichte in eine bestimmte Komponente des größeren Modells einbringen, typischerweise in die „Kreuz-Attention-Schicht“, die eine entscheidende Rolle in der finalen Phase der Output-Generierung spielt.
Zum Beispiel, wenn das Ziel in der Bildgenerierung mit einem Diffusionsmodell darin besteht, Anime-Bilder einer bestimmten Person zu erstellen, anstatt das gesamte Diffusionsmodell auf den Bildern dieser Person fein abzustimmen, würde eine LORA mit diesen Bildern trainiert und dann mit einem Anime-fähigen Modell verwendet. Diese Kombination ermöglicht es dem größeren Modell, personalisierte Anime-Bilder der Person zu generieren.
In ähnlicher Weise kann LORA im Kontext von LLMs eingesetzt werden, um neue Konzepte oder Wissensbereiche in das Modell einzubringen, ohne eine umfangreiche Neueinstellung des gesamten Modells zu benötigen. Diese Technik bietet eine effizientere und gezielte Möglichkeit, KI-Modelle für spezifische Aufgaben oder Stile zu verbessern und anzupassen.
Maschinelles Lernen
Ein Kernbereich der KI, maschinelles Lernen beinhaltet das Training von Algorithmen, um basierend auf Daten Entscheidungen oder Vorhersagen zu treffen. Es umfasst verschiedene Techniken wie überwachtes Lernen, unüberwachtes Lernen und Verstärkungslernen. Maschinelles Lernen automatisiert die Erstellung analytischer Modelle und erlaubt Systemen, aus Erfahrung zu lernen und sich anzupassen, ohne explizit programmiert zu werden.
Verstärkungslernen
Verstärkungslernen ist eine Art des maschinellen Lernens, bei dem ein Agent lernt, Entscheidungen zu treffen, indem er Aktionen in einer Umgebung ausführt, um ein Ziel zu erreichen. Der Agent lernt aus Versuch und Irrtum und erhält Belohnungen oder Strafen für Aktionen, wodurch vorteilhaftes Verhalten verstärkt wird. Zum Beispiel kann diese Technik verwendet werden, um einem Algorithmus das Spielen eines Videospiels beizubringen, indem er einfach mit ihm interagiert.
Überwachtes Lernen
Überwachtes Lernen ist ein Ansatz des maschinellen Lernens, bei dem Modelle auf gelabelten Daten trainiert werden. Das Modell lernt, Ausgaben aus Eingabedaten vorherzusagen, und seine Leistung wird gegen bekannte Labels gemessen. Dieser Ansatz umfasst eine Reihe von Daten für das Modell zum Lernen in Form von Vektoren, die die Eingabe und die erwartete Ausgabe enthalten. Basierend auf der Differenz zur erwarteten Ausgabe wird das Verhalten des Algorithmus angepasst (zum Beispiel durch Rückpropagation in künstlichen neuronalen Netzwerken).
Transformer
Hinter diesem KI-Begriff steht eine revolutionäre Architektur neuronaler Netzwerke, die das Feld der natürlichen Sprachverarbeitung erheblich vorangebracht hat. Transformer sind darauf ausgelegt, sequenzielle Daten zu verarbeiten, und sind bekannt für ihren Selbstaufmerksamkeitsmechanismus, der es ihnen ermöglicht, die Wichtigkeit verschiedener Teile der Eingabedaten abzuwägen. Sie stehen hinter vielen hochmodernen Sprachmodellen wie GPT und BERT.
Unüberwachtes Lernen
Im Gegensatz zum überwachten Lernen beinhaltet dieser Ansatz das Training von Modellen auf Daten ohne vorab festgelegte Labels. Das Modell lernt Muster und Strukturen aus den Daten selbst.
Variational Autoencoder (VAE)
Ein VAE ist eine Art generatives Modell, das hauptsächlich für seine Fähigkeit bekannt ist, Eingangsdaten in einen komprimierten latenten Raum zu codieren und anschließend aus diesem Raum den Eingang zu rekonstruieren. Das Modell besteht aus zwei Hauptkomponenten: einem Encoder, der die Daten in den latenten Raum komprimiert, und einem Decoder, der die Daten aus diesem Raum rekonstruiert.
VAEs sind besonders effektiv bei der Bildgenerierung. Sie können lernen, neue Bilder zu erzeugen, die den originalen Trainingsdaten ähneln, was die Erstellung vielfältiger Stile und realistischer Bilder ermöglicht.
VAEs könnten zum Beispiel in einem größeren System eingesetzt werden, in dem Diffusionsmodelle ein Teil sind, insbesondere bei Aufgaben, die Bildcodierung und -rekonstruktion umfassen. Der eigentliche Prozess der Umwandlung von Rauschen in einheitliche Bilder in Diffusionsmodellen wird jedoch typischerweise durch den Diffusionsprozess selbst und nicht durch ein VAE verwaltet.
Vektor
Im Kontext des maschinellen Lernens und der KI ist ein Vektor ein Zahlenarray, das Daten darstellt. In NLP werden zum Beispiel Wörter häufig in Vektoren umgewandelt, die von Algorithmen zur Textverarbeitung und zum Textverständnis verwendet werden.
Vektordatenbank – sie ist speziell für das Speichern und Abfragen von Vektordaten entwickelt, die Darstellungen von Datenpunkten in einem hochdimensionalen Raum sind. Diese Art von Datenbank ist besonders relevant in Szenarien, in denen Embeddings beteiligt sind, wo vielfältige Datentypen wie Text oder Bilder in ein Vektorformat umgewandelt werden.
Die Kernstärke einer Vektordatenbank liegt in ihrer Fähigkeit, Operationen wie Ähnlichkeitssuche effizient durchzuführen. Diese Fähigkeit ist entscheidend in verschiedenen Anwendungen, einschließlich Empfehlungssystemen. Ihr Ziel ist es, Elemente zu finden, die den Interessen eines Nutzers ähneln, und Bilderabfrageaufgaben, wo das Ziel darin besteht, Bilder zu finden, die einem Abfragebild visuell gleichen.
Anwendungsbeispiel aus der Praxis – ein praktischer Anwendungsfall für Vektordatenbanken ist die Erweiterung der Fähigkeiten eines großen Sprachmodells (LLM). Anstelle eines Finetunings eines LLMs mit spezifischen Websitedaten, kann der Inhalt der Website als Vektoren in einer Vektordatenbank gespeichert werden. Wenn eine Benutzeranfrage eingegangen ist, kann die Vektordatenbank durchsucht werden, um die relevantesten Inhaltsvektoren zu finden, die eng mit der Anfrage übereinstimmen.
Diese relevanten Vektoren können dann als zusätzlicher Kontext an das LLM übergeben werden. Dieser Ansatz ermöglicht es dem Modell, Antworten zu generieren, die spezifischer auf den Inhalt und die Themen der Website abgestimmt sind, und so genauere und kontextuell passendere Antworten auf Benutzeranfragen zu liefern.
KI-Tools, Lösungen und nützliche Websites
Zusätzlich zu fortgeschrittenen KI-Begriffen ist es nützlich, mit Werkzeugen und Websites in diesem Bereich vertraut zu sein, die für verschiedene Aktivitäten nützlich sein können. Es ist unmöglich, eine endliche Anzahl von Beispielen für solche Lösungen aufzulisten, da ständig neue erstellt werden. Wir liefern jedoch eine subjektive Auswahl.
Automatic1111/stable diffusion webUI
Automatic1111/stable diffusion webUI - in der Community als Automatic1111 oder A1111 bekannt, ist eine beliebte Implementierung des Stable Diffusion-Modells, das häufig für Bildgenerierungsaufgaben verwendet wird. Es ist bekannt für seine benutzerfreundliche Oberfläche und effiziente Verarbeitung, die fortschrittliche Bildsynthese zugänglicher macht. Diese Implementierung ermöglicht es Benutzern, eine breite Palette von Modell-Checkpoints einzufügen, die von der Community trainiert wurden, um Bilder in verschiedenen Stilen zu erzeugen. Es ermöglicht auch die Bild-zu-Bild-Generierung, Übermalungen, das Hochskalieren von generierten Bildern, das Training und das Zusammenführen von Modell-Checkpoints.
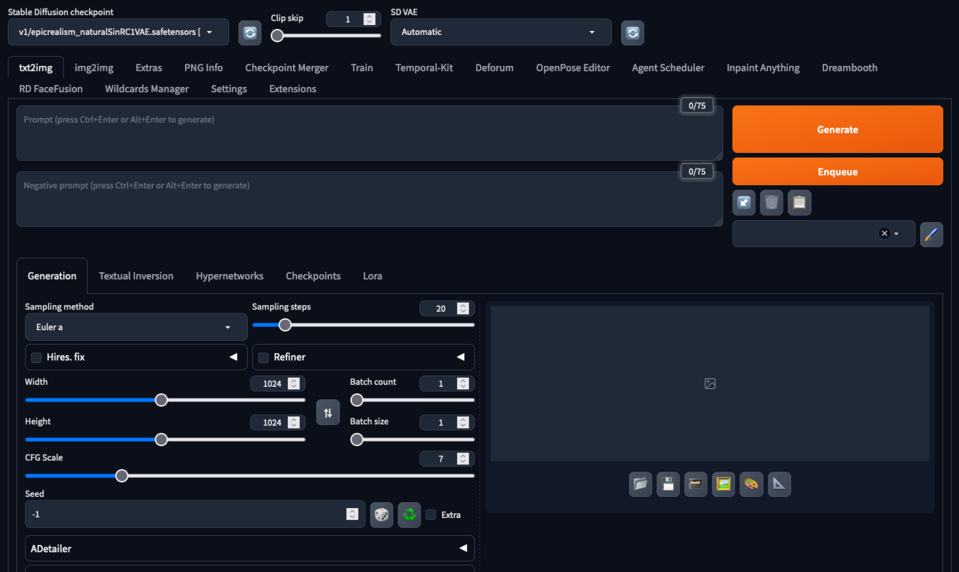
Automatic1111 Benutzeroberfläche
Google Bard
Bard ist ein generativer KI-Chatbot, der von Google entwickelt wurde. Ursprünglich basierend auf der LaMDA-Familie großer Sprachmodelle (LLMs), wurde er später auf PaLM und dann auf Gemini aufgerüstet. Bard wurde als Googles Antwort auf den Aufstieg von OpenAIs ChatGPT geschaffen und im März 2023 in begrenztem Umfang gestartet. Seine Entwicklung und Veröffentlichung waren Teil des intensivierten Fokus von Google auf KI als Reaktion auf die zunehmende Bedeutung von ChatGPT. Bard ist dazu ausgelegt, ähnlich wie ChatGPT zu funktionieren und Konversations-KI-Dienste bereitzustellen, jedoch mit Integration in Googles Suchfunktionen und andere Produkte.
ChatGPT
Entwickelt von OpenAI, ChatGPT ist eine Variante des GPT (Generative Pre-trained Transformer) KI-Modells, das speziell für die Generierung von menschenähnlichem Text in einem konversationalen Kontext konzipiert wurde. Es glänzt in verschiedenen Sprachaufgaben, einschließlich Chatten, Beantworten von Fragen und Vervollständigung von Text.
CivitAI
CivitAI ist eine Plattform, die sich auf generative KI konzentriert und eine Vielzahl von Open-Source-Modellen und Tools beherbergt. Die Website bietet eine Sammlung von Bildern und Modellen, die von der Community erstellt wurden, und zeigt Anwendungen von einfachen Formen bis hin zu komplexen Landschaften und menschlichen Gesichtern. CivitAI dient als Zentrum für Kreativität und Inspiration. Es bietet Ressourcen, Anleitungen und Tutorials zur generativen KI. Die Seite organisiert auch Herausforderungen und Veranstaltungen, um das Community-Engagement und die Zusammenarbeit im Bereich der KI-generierten Kunst und Inhalte zu fördern.
CLIP
Contrastive Language-Image Pre-Training (CLIP) ist ein von OpenAI entwickeltes neural network model, das auf einer Vielzahl von Bild- und Textpaaren trainiert wurde. Dieser innovative Ansatz ermöglicht es dem Modell, Bilder im Kontext der natürlichen Sprache zu verstehen und zu interpretieren. Eine der entscheidenden Fähigkeiten von CLIP ist seine Fähigkeit, Bilder effektiv mit Textbeschreibungen zu assoziieren.
DALL-E
Auch von OpenAI entwickelt, DALL-E ist ein KI-Diffusionsmodell, das bekannt ist für seine Fähigkeit, kreative und detaillierte Bilder aus textuellen Beschreibungen zu erzeugen. Es zeigt das Potenzial von KI in künstlerischen und kreativen Anwendungen. In der neuesten Version ist es in das ChatGPT integriert, was die Bildgenerierung über die Schnittstelle des Chatbots ermöglicht und die Fähigkeit des Chat-Modells nutzt, die Benutzereingaben zu verfeinern.

Grafiken generiert von Dall-E 2 basierend auf Eingabe "Drupal software house"

Dall-E 3 mit seiner in ChatGPT integrierten Schnittstelle
HuggingFace
HuggingFace ist ein Unternehmen und eine Plattform, bekannt für sein umfassendes Repository vortrainierter Modelle und Tools in der natürlichen Sprachverarbeitung. Diese Lösung bietet eine zugängliche Plattform für die Implementierung und das Experimentieren mit fortschrittlichen KI-Modellen. Es ist die Heimat vieler Open-Source-LLMs und Diffusionsmodelle.
Stable Diffusion
Eingeführt im Jahr 2022, Stable Diffusion ist ein Text-zu-Bild-Diffusionsmodell, das von Stability AI entwickelt wurde. Es generiert detaillierte Bilder basierend auf Textbeschreibungen unter Verwendung eines variational Autoencoder (VAE), U-Net und eines optionalen Text-Encoders. Das Modell komprimiert Bilder in einen kleineren dimensionalen latenten Raum, wendet während der Vorwärtsdiffusion iterativ Gaußsches Rauschen an. Der U-Net-Block mit einem ResNet-Kernraugerüst entnimmt das Ergebnis Rauschen, und der VAE-Decoder wandelt die Darstellung dann wieder in den Pixelbereich um.
Stable Diffusion kann auf Text und Bilder mit dem CLIP-Textencoder konditioniert werden, der Texteingaben in einen Embedding-Raum umwandelt. Mit seiner relativ leichtgewichtigen Architektur und Fähigkeit, auf Consumer-GPUs zu laufen, markierte Stable Diffusion einen Wandel von früheren proprietären Modellen wie DALL-E, die cloudbasiert waren.

Stable Diffusion Generierung für die Eingabe: „Drupal software house“, verwendeter Checkpoint - „epicRealism“
LLAMA
Large Language Model Meta AI (LLAMA) ist eine Familie von großen Sprachmodellen, die von Meta AI im Februar 2023 veröffentlicht wurde. Sie umfasst Modelle mit 7, 13, 33 und 65 Milliarden Parametern. LLaMA-Modelle zeigen bemerkenswerte Leistung bei verschiedenen NLP-Benchmarks, wobei das 13B-Parameter-Modell GPT-3 (175B Parameter) in bestimmten Aufgaben übertrifft.
Diese Modelle sind bemerkenswert für ihre Zugänglichkeit. Meta veröffentlichte die Modellgewichte von LLaMA für die Forschungsgemeinschaft unter einer nicht-kommerziellen Lizenz. Im Juli 2023 führte Meta in Partnerschaft mit Microsoft LLaMA-2 mit Modellgrößen von 7, 13 und 70 Milliarden Parametern ein. LLaMA-2 beinhaltet Basis- und feinabgestimmte Modelle für Dialoge, die als LLaMA-2 Chat bezeichnet werden, und bietet verbesserte Datenausbildung und Sicherheitsmaßnahmen. Kurz nach seiner Veröffentlichung wurden LLaMAs Gewichte online geleakt, was zu einer weitreichenden Verbreitung führte.
Midjourney
Midjourney ist ein generatives KI-Programm, das von dem in San Francisco ansässigen unabhängigen Forschungslabor Midjourney, Inc. erstellt wurde. Es generiert Bilder aus nativen Sprachbeschreibungen, ähnlich zu OpenAI's DALL-E und Stability AI's Stable Diffusion. Midjourney trat im Juli 2022 in die offene Beta ein und ist über einen Discord-Bot zugänglich. Das Tool wurde für verschiedene kreative Anwendungen, einschließlich des schnellen Prototyping in den Künsten, genutzt. Die Bildgenerierungsfähigkeiten von Midjourney waren auch Thema von Debatten und Kontroversen, insbesondere hinsichtlich der Originalität und Ethik von KI-generierter Kunst.
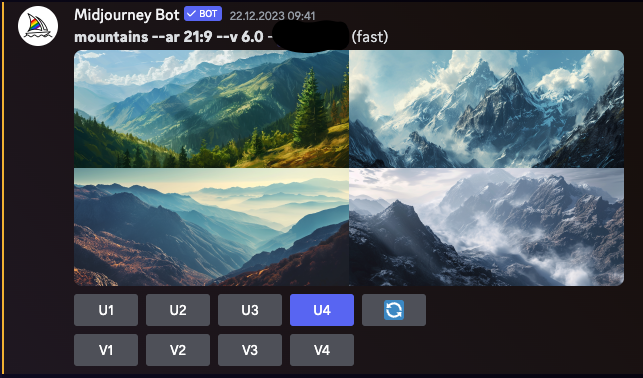
Bilder generiert mit Midjourney Version 6.0 (Discord-Schnittstelle ist klar sichtbar)
Pinecone
Pinecone ist eine Lösung für eine Vektordatenbank, die darauf ausgelegt ist, hochdimensionale Daten effizient zu verarbeiten. Pinecone ist besonders nützlich für Anwendungen der Ähnlichkeitssuche, oft im Kontext von maschinellem Lernen und KI.
Text-generation-webui
Text-generation-webui ist eine Gradio-basierte Web-Benutzeroberfläche, die für die Interaktion mit verschiedenen großen Sprachmodellen (LLMs) entwickelt wurde. Sie unterstützt eine Reihe von Modellen wie Transformer, GPTQ, AWQ, EXL2, llama.cpp (GGUF) und Llama-Modelle. Die Benutzeroberfläche zielt darauf ab, benutzerfreundlich zu sein und verschiedene Modi wie Notebook, Chat anzubieten. Sie beinhaltet zahlreiche Funktionen wie Unterstützung für unterschiedliche Modellarchitekturen, ein Dropdown-Menü für den Modell- und Checkpoint-Wechsel und die Integration mit Erweiterungen für zusätzliche Funktionalitäten wie Langzeitspeicher oder Text-zu-Sprache. Das Repository bietet detaillierte Anweisungen zur Installation und Nutzung und ist so für Benutzer zugänglich, die LLMs für Textgenerierungsaufgaben nutzen möchten.
Whisper
Entwickelt von OpenAI, Whisper ist ein Spracherkennungsmodell, das entwickelt wurde, um Sprach-in-Text (STT) Fähigkeiten bereitzustellen. Es zielt darauf ab, Audio genau in Text zu transkribieren und dabei mehrere Sprachen und Akzente zu erkennen. Whisper ist bemerkenswert für seine Effektivität im Verständnis gesprochener Sprache, was es zu einem wertvollen Tool für eine Vielzahl von Anwendungen macht, einschließlich automatisierter Transkription und Unterstützung für Barrierefreiheit für Personen mit Hörbehinderungen.
Erweiterte KI-Begriffe und Lösungen – Zusammenfassung
Wir hoffen, dass dieser Artikel (besonders in Kombination mit dem ersten Teil zu grundlegender Terminologie) als Sprungbrett in die breitere Welt der KI dient, die ein sich ständig weiterentwickelndes, neues und spannendes Feld ist. Möge dieses KI-Wörterbuch Sie inspirieren, das Potenzial der künstlichen Intelligenz zu erkunden! Und wenn Sie auf eine Projektidee kommen, die von KI-Entwicklung profitieren würde, stehen Ihnen unsere erfahrenen Entwickler zur Verfügung.










