
Environnement fiable alimenté par AWS

Les sites Web jouent un rôle de plus en plus important sur Internet, générant parfois même des profits énormes. Même les plus petites interruptions de leur fonctionnement peuvent entraîner des pertes pouvant atteindre des centaines voire des milliers de dollars. C'est pourquoi, lors de la réalisation de services de développement Drupal, nous attachons une grande importance à garantir que notre travail soit le plus fiable possible. Comment ? Grâce à des solutions qui garantissent une haute disponibilité, offertes par Amazon Web Services.
Qu'est-ce que la haute disponibilité ?
Aux fins de cet article, nous définirons la haute disponibilité comme un besoin d'un site Web concernant son temps de fonctionnement, défini comme un pourcentage du temps de fonctionnement en un mois. Une disponibilité à 100 % signifie que les utilisateurs peuvent utiliser le site pendant 43 200 minutes, soit exactement 30 jours dans un mois.
Si pour une raison quelconque, qu'il s'agisse d'une mise à jour, d'une panne ou d'une attaque, le site ne fonctionne pas correctement pendant 12 heures, le paramètre de disponibilité sera de 98,3 % (42 480 minutes sur 43 200).
Quel est le niveau de disponibilité requis ?
Il n'existe pas de réponse claire à cette question, car elle dépend principalement des exigences définies par le client, et si ce paramètre n'a pas été spécifié, nous devrons le définir nous-mêmes. Dans ce cas, il est utile de répondre à ces deux questions simples :
- combien de temps est nécessaire pour les mises à jour du site (nécessitant la mise hors ligne pour les utilisateurs) ?
- combien de temps doit être consacré à d'autres activités nécessitant la mise hors ligne du site ?
La somme des deux réponses, augmentée d'une éventuelle marge de sécurité, permet de déterminer le temps de disponibilité souhaité. Chez Droptica, pour nos sites clés, ce paramètre est de 99,99 %, ce qui se traduit par seulement 4 minutes d'indisponibilité des services tout au long du mois !
Qu'est-ce qui distingue l'infrastructure HA ?
Dans l'approche standard, utilisée sur de nombreuses plateformes d'hébergement, nous avons affaire à un seul serveur, sur lequel toutes les applications nécessaires à la fourniture des services - comme le serveur HTTP (apache2 ou nginx), MySQL, parfois aussi solr, redis, memcached et, bien sûr, l'espace disque - sont configurées. Un schéma de cette solution est illustré dans l'image ci-dessous.
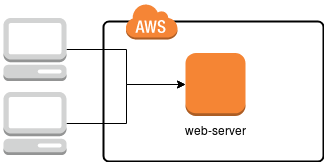
Dans ce cas, il suffit d'endommager un serveur (ou l'un des composants installés) pour rendre le site qu'il héberge inaccessible, réduisant ainsi le temps de disponibilité. Comment cela peut-il être évité ? Il suffit de dupliquer l'infrastructure de telle manière que, si l'un des serveurs tombe en panne, un autre prenne le relais, comme illustré dans le schéma ci-dessous.
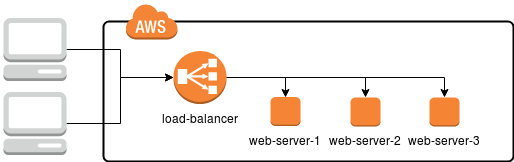
Grâce à cette approche, chaque serveur Web a la même fonctionnalité et fournit exactement les mêmes services. Cependant, entre le serveur et l'utilisateur se trouve également un répartiteur de charge, un serveur spécial chargé de recevoir les requêtes des utilisateurs et de les diriger vers l'une des trois machines cibles.
Bien que dans notre schéma, le répartiteur de charge ressemble à un élément unique et puisse sembler être le nœud le plus vulnérable et un point de défaillance unique, en réalité, Amazon propose une gamme de solutions évolutives, efficaces et fiables pour les répartiteurs de charge :
Exemple pratique
Chez Droptica, nous avons créé le modèle qui, dans la plupart des cas, est plus que suffisant pour les besoins de nos clients. Une infrastructure comme celle de l'image ci-dessous assure la redondance et la haute disponibilité à des coûts minimaux.
Pour obtenir ce résultat, nous utilisons :
- des machines EC2 - la base de tout l'environnement, elles sont des machines virtuelles où les services fonctionnent,
- Application Load Balancer (ALB) - un répartiteur de charge, redirigeant dynamiquement les demandes entre les instances EC2, vérifie les dysfonctionnements et prend en charge la connexion HTTPS,
- Relational Database Service (RDS) - service de base de données distribué de bout en bout (MySQL),
- Elastic File System (EFS) - système de fichiers distribué, où sont stockées les données partagées (c'est-à-dire, images, vidéos et autres)
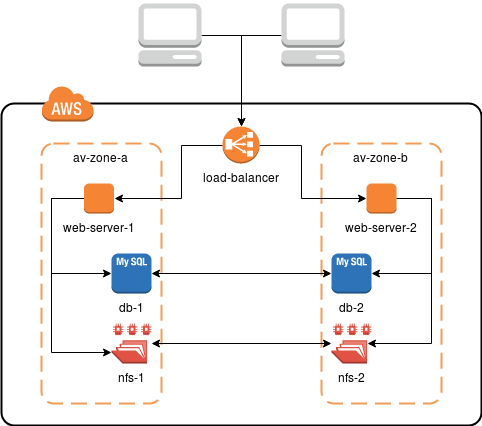
Dans l'exemple ci-dessus, tous les composants de l'infrastructure sont définis dans différentes zones de disponibilité. Physiquement, ce sont deux centres de données distincts reliés par des liens stables et rapides. Avec EFS et RDS, nous n'avons pas à nous soucier de la configuration et de la synchronisation des données. Nous les utilisons simplement. De RDS, nous recevons des données vers MySQL, tandis que EFS est monté comme un partage NFS ordinaire.
Problèmes liés à la haute disponibilité
L'implémentation de systèmes de haute disponibilité apporte non seulement de nombreux avantages mais peut également entraîner de nombreux problèmes. Cela est dû au fait que vous devez introduire des structures beaucoup plus complexes dans l'environnement.
L'un des premiers processus qui deviennent considérablement plus compliqués est le déploiement d'applications, qui doit être adapté pour prendre en charge plusieurs serveurs, afin de ne pas mener à une situation où l'application met à jour sa base de données sur un hôte, tandis que l'autre sert le contenu aux utilisateurs.
En ce qui concerne les différences entre les services particuliers, il y a un problème avec les services qui fonctionnent sur des fichiers, comme Solr. Exécuter trois instances indépendantes entraînera des situations où certaines d'entre elles sont plus ou moins à jour que d'autres. Cela peut être résolu grâce à un système de fichiers partagé (NFS, EFS, etc.), un cluster Solr ou des solutions dédiées telles que CloudSearch.
Consulter les journaux devient également beaucoup plus difficile. Le trafic lié à une session utilisateur spécifique est dirigé vers différents serveurs, ce qui rend un point de connexion central basé, par exemple, sur Logstash une bonne pratique.
Les coûts sont également un inconvénient majeur de la mise en œuvre d'une infrastructure de haute disponibilité. La plupart des serveurs et des services doivent être configurés en parallèle, au moins doublés, et parfois en grand nombre. En réalité, ces serveurs peuvent être moins performants (après tout, le trafic est distribué proportionnellement), mais en général, en tenant également compte des coûts des clusters d'applications, cela sera plus coûteux, beaucoup plus coûteux. D'un autre côté, toutefois, c'est un investissement qui se traduira par moins de stress et par la certitude que, en cas de panne, nous serons encore capables de livrer le contenu à l'utilisateur final.







