

L'extraction de métadonnées structurées à partir de documents juridiques est l'une des tâches d'IA les plus difficiles dans les industries réglementées. Grâce à une ingénierie d'invites minutieuse avec GPT-4o-mini et les sorties structurées d'OpenAI, les équipes peuvent atteindre une précision supérieure à 95% dans la catégorisation de documents réglementaires complexes à travers de multiples taxonomies. Ce guide technique révèle comment BetterRegulation a construit des modèles d'invites de production qui extraient de manière fiable les types de documents, les organisations, les domaines d'objet et les obligations juridiques à partir de textes juridiques britanniques/irlandais - réduisant le temps de correction manuelle de 15 minutes à 3 minutes par document.
Dans cet article:
- Le défi : l'extraction de données structurées à partir de textes juridiques non structurés
- Pourquoi les documents juridiques sont-ils si difficiles à traiter avec l'IA ?
- Comment l'injection de taxonomie améliore-t-elle la précision de l'extraction ?
- Comment garantir une sortie cohérente avec le schéma JSON ?
- Comment fonctionne l'appariement sémantique pour les références d'entités ?
- Comment optimiser les invites pour une meilleure précision ?
- Comment extraire les obligations juridiques des documents ?
- Exemples de code et modèles d'invites
- L'ingénierie d'invites pour l'extraction de données - conclusion
- Besoin d'une ingénierie d'invites experte pour votre projet d'IA ?
Le défi : l'extraction de données structurées à partir de textes juridiques non structurés
Les documents juridiques sont des trésors d'informations structurées enfouis dans une prose dense et complexe:
"L'Autorité de conduite financière émet par la présente cette orientation en vertu de l'article 139A de la Loi sur les services financiers et les marchés de 2000, telle que modifiée par la Loi sur les services financiers de 2012, effective à partir du 1er janvier 2024, applicable à tous les prêteurs de crédit à la consommation et les bailleurs opérant en vertu de la Partie II de la Loi sur le crédit à la consommation de 1974..."
Cachés dans cette seule phrase:
- Type de document: Note d'orientation
- Organisation: Autorité de conduite financière
- Législation: Loi sur les services financiers et les marchés de 2000
- Année: 2024
- Parties concernées: les prêteurs de crédit à la consommation et les bailleurs
Un avocat humain extrait cela instantanément. Une IA a besoin d'instructions minutieuses - c'est là qu'intervient l'ingénierie des invites.
Cet article vous montre comment rédiger des invites qui extraient de manière fiable les données structurées à partir de documents juridiques, atteignant une précision supérieure à 95% en production.
Pourquoi les documents juridiques sont-ils si difficiles à traiter avec l'IA ?
Avant de plonger dans les solutions, il est essentiel de comprendre les défis spécifiques qui rendent l'extraction de documents juridiques difficile. Les textes juridiques présentent des obstacles uniques que les approches standard de traitement de texte échouent à gérer efficacement.
1. Langage complexe
La rédaction juridique utilise :
- Termes archaïques - "ci-inclus", "alors que", "susmentionné"
- Clauses imbriquées - des phrases couvrant des paragraphes
- Jargon technique - "force majeure", "res ipsa loquitur"
- Références ambiguës - "la loi susmentionnée" (laquelle ?)
2. Taxonomies multiples
Un seul document pourrait nécessiter une catégorisation à travers :
- Type de document (statut, réglementation, orientation, jurisprudence)
- Organisation (autorité émettrice)
- Domaine d'objet (bancaire, protection des données, emploi)
- Juridiction (Royaume-Uni, UE, pays spécifiques)
- Législation (quels actes/régulations s'appliquent)
- Année, date d'effet, historique des modifications
Chaque taxonomie compte de 10 à 400 termes. C'est des centaines de classifications possibles.
3. Formats variables
Aucun deux documents juridiques n'organisent l'information de la même manière:
Statut:
Loi bancaire 2023
Une loi pour réguler...
Promulguée par le Parlement : 15 mars 2023Note de guidance :
Document de consultation sur l'orientation de la FCA CP23/15
Publié : Décembre 2023
Pour : Les banques et les sociétés de crédit immobilierJurisprudence :
Regina c. Autorité de conduite financière [2023] UKSC 42
Cour suprême, 8 novembre 2023Même information (type, organisation, date) dans des formats complètement différents.
4. Information implicite vs explicite
Parfois, l'information est donnée directement :
> “Cette réglementation s'applique à tous les prêteurs de crédit à la consommation…”
D'autres fois, elle est implicite :
> “En vertu de la Partie II de la Loi sur le crédit à la consommation…” (implique : affecte les prêteurs de crédit)
L'IA doit inférer à partir du contexte.
Comment l'injection de taxonomie améliore-t-elle la précision de l'extraction ?
La base d'une extraction précise : Informez l'IA de vos taxonomies à l'avance.
Inclure des listes de taxonomie complètes dans le contexte
Au lieu de : "Catégorisez ce document par type, organisation et domaine."
Faites : "Faites correspondre ce document à ces taxonomies exactes :
### TAXONOMIE DU TYPE DE DOCUMENT :
- Statut
- Règlement
- Note d'orientation
- Code de pratique
- Jurisprudence
### TAXONOMIE DE L'ORGANISATION :
- Autorité de conduite financière
- Banque d'Angleterre
- Autorité de la concurrence et des marchés
- Bureau du commissaire à l'information
[... liste complète ...]
### TAXONOMIE DU DOMAINE DU DOCUMENT :
- Banque et finance
- Crédit à la consommation
- Réglementation bancaire
- Protection des données
[... liste complète ...]Pourquoi cela fonctionne :
- Limites claires – L'IA sait exactement quelles options existent
- Correspondance sémantique – L'IA comprend que "FCA" = "Autorité de conduite financière"
- Renvoi des noms de taxonomies – L'IA renvoie les noms des termes (par exemple,
["Protection des données", "Services financiers", "RGPD"]), que le système mappe ensuite sur les IDs de termes via la recherche de taxonomie de Drupal - Pas d'hallucinations – L'IA n'invente pas de catégories
Comment ça marche :
L'IA renvoie les noms des termes de la taxonomie :
["Protection des données", "Services financiers", "RGPD"]Le système Drupal effectue la recherche de taxonomie : - "Protection des données" → trouve l'ID de terme : 42 - "Services financiers" → trouve l'ID de terme : 87 - "RGPD" → trouve l'ID de terme : 156
Le document est attribué : [42, 87, 156]
Cette approche exploite la compréhension sémantique de l'IA tout en maintenant des références d'entités précises grâce au système de taxonomie de Drupal.
Le coût en jetons en vaut-il la peine ?
"Mais cela ne va-t-il pas utiliser trop de jetons ?"
Oui, cela utilise des jetons. Mais c'est valable.
Les chiffres de BetterRegulation :
- Texte du document : 35 000 jetons (PDF typique de 50 pages)
- Contexte de la taxonomie : 5000 jetons (toutes taxes)
- Instructions : 1000 jetons
- Total : 41 000 jetons
- Limite de contexte : 128 000 jetons (GPT-4o-mini)
- Marge : 87 000 jetons (beaucoup de place)
Coût :
- Avec les taxonomies : 0,21 £ par document
- Sans taxonomies (hypothétique) : 0,18 £ par document
- Coût supplémentaire : 0,03 £ par document
Valeur :
- Augmentation de la précision : 75% → 95%
- Temps de correction manuelle : 15 min → 3 min
- Valeur des économies de temps : plus de 2,00 £ par document
ROI : retour sur investissement de 70x sur l'investissement en jetons de taxonomie.
Comment imposer une sortie cohérente avec le schéma JSON ?
Une fois que vous avez fourni les taxonomies à l'IA, l'étape critique suivante consiste à s'assurer qu'elle renvoie les données dans un format cohérent et analysable. La fonctionnalité Structured Outputs d'OpenAI garantit que les réponses correspondent à votre schéma JSON exact à chaque fois.
Définir la structure de sortie exacte
Instruction vague : > "Extrayez le type de document, l'organisation et l'année."
L'IA pourrait renvoyer :
Le type de document est une note d'orientation
Organisation : FCA
Année : 2024Inanalysable. Le format varie à chaque fois.
Mieux : Utilisez les sorties structurées d'OpenAI :
OpenAI fournit des Sorties structurées qui garantissent que la réponse du modèle correspondra exactement à votre schéma JSON. C'est plus robuste que le mode JSON : au lieu d'obtenir simplement un JSON valide, vous obtenez un JSON qui correspond exactement à la structure de votre schéma.
Deux approches disponibles :
- Mode JSON (
type : "json_object") – garantit un JSON valide, mais n'applique pas votre schéma spécifique - Sorties structurées (schéma JSON +
strict : true) – garantit que la sortie correspond à votre schéma exact (c'est ce que BetterRegulation utilise)
Configuration de l'API avec les sorties structurées :
$response = $client->chat()->create([
'model' => 'gpt-4o-2024-08-06', // Les sorties structurées nécessitent des modèles gpt-4o
'messages' => [
['role' => 'user', 'content' => $prompt]
],
'response_format' => [
'type' => 'json_schema',
'json_schema' => [
'name' => 'metadata du document',
'strict' => true, // ← Applique la conformité stricte au schéma
'schema' => [
'type' => 'object',
'properties' => [
'type_de_document' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'organisation' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'domaine du document' => [
'type' => 'array',
'items' => ['type' => 'string']
],
'année' => ['type' => 'string'],
'titre' => ['type' => 'string'],
'source_url' => ['type' => 'string']
],
'required' => ['type_de_document', 'organisation', 'domaine du document', 'année', 'titre'],
'additionalProperties' => false
]
]
],
'temperature' => 0.1,
]);Texte d'invite (instructions) :
Analysez le document et extrayez :
- type_de_document : Le type de document principal (retournez le nom du terme de la taxonomie sous forme de chaîne dans un tableau)
- organisation : L'organisation émettrice (retournez le nom du terme de la taxonomie sous forme de chaîne dans un tableau)
- domaine du document : Tous les domaines pertinents (retournez les noms des termes de la taxonomie sous forme de chaînes dans un tableau)
- année : Année de publication en format AAAA
- titre : Titre du document
- source_url : URL complète si elle est trouvée dans le document
Utilisez UNIQUEMENT les noms des termes de la taxonomie fournie. Le système cartographiera automatiquement ces noms sur les ID des termes.Avec les sorties structurées, l'IA renvoie de manière cohérente :
{
"type_de_document": ["Note d'orientation"],
"organisation": ["Autorité de conduite financière"],
"domaine du document": ["Crédit à la consommation", "Réglementation bancaire"],
"année": "2024",
"titre": "Guide de la FCA sur les pratiques de crédit à la consommation",
"source_url": "https://www.fca.org.uk/publication/guidance/gc24-1.pdf"
}Note : Le système effectue ensuite une recherche de taxonomie pour convertir les noms des termes en ID : - "Note d'orientation" → ID de terme : 14 - "Autorité de conduite financière" → ID de terme : 23 - "Crédit à la consommation" → ID de terme : 35 - "Réglementation bancaire" → ID de terme : 36
Le document est attribué : type_de_document: [14], organisation: [23], domaine du document: [35, 36]
Résultat : une conformité au schéma de 100%, garantie. BetterRegulation a traité des milliers de documents en utilisant les sorties structurées avec zéro échec de validation de schéma. Le modèle ne peut pas renvoyer de données qui ne correspondent pas au schéma JSON - OpenAI l'impose au niveau de l'API, éliminant ainsi le besoin d'une validation de sortie étendue dans votre code.
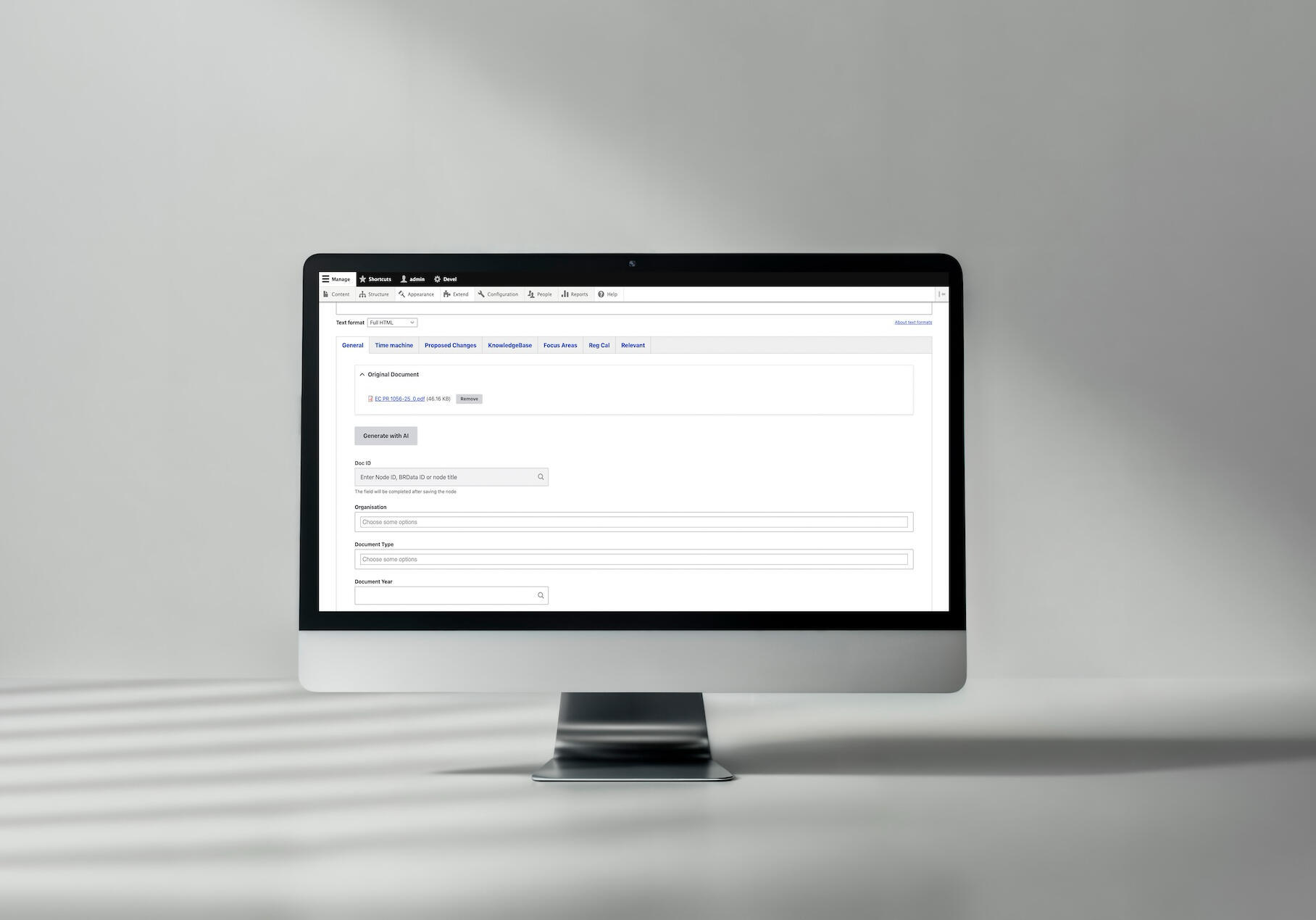
Un exemple de catégorisation de documents basée sur l'IA chez Better Regulation
Voir l'étude de cas complète sur la catégorisation des documents par l'IA →
Comment fonctionne l'appariement sémantique pour les références d'entités ?
Avec la sortie structurée en place, le prochain défi consiste à s'assurer que l'IA mappe correctement le contenu du document à vos termes de taxonomie spécifiques. C'est là que l'appariement sémantique - la capacité de l'IA à comprendre le sens au-delà des correspondances de texte exactes - devient crucial.
Comment l'IA connecte les termes aux taxonomies
Le miracle : L'IA comprend le sens, pas seulement le texte.
Exemple :
Terme de taxonomie : "Prêteurs et donneurs en crédit à la consommation"
Phrases du document que l'IA réussit à faire correspondre :
- "pratiques de prêt à la consommation"
- "fournisseurs de prêts personnels"
- "sociétés de crédit proposant la location-vente"
- "entreprises qui proposent des financements aux consommateurs"
- "prêteurs à particuliers"
Comment ? Les grands modèles linguistiques apprennent les relations sémantiques lors de leur formation. Ils savent :
- "prêt" ≈ "prêteurs"
- "prêt personnel" ≈ "crédit à la consommation"
- "location-vente" → "donneurs"
Une correspondance par mots clés traditionnelle échouerait sur la plupart de ces variations.
Mécanisme de mappage de nom à ID
Décision de conception critique : L'IA renvoie les noms des termes de la taxonomie, que le système mappe ensuite sur les ID de termes via la recherche de taxonomie de Drupal.
Pourquoi cette approche fonctionne :
// ✅ BIEN : L'IA renvoie les noms des termes
{
"organisation": ["Autorité de conduite financière"],
"domaine du document": ["Protection des données", "Services financiers"]
}
// Le système effectue la recherche de la taxonomie
$termes_d'organisation = \Drupal::entityQuery('taxonomy_term')
->condition('name', 'Autorité de conduite financière')
->condition('vid', 'organisation')
->execute();
$termes_de_domaine = \Drupal::entityQuery('taxonomy_term')
->condition('name', ['Protection des données', 'Services financiers'], 'IN')
->condition('vid', 'domaine du document')
->execute();
// Mappe les noms sur les ID
$id_organisation = reset($termes_d'organisation); // par exemple, 23
$ids_de_domaine = array_values($termes_de_domaine); // par exemple, [42, 87]
// Attribue les ID au document
$node->set('field_organisation', ['target_id' => $id_organisation]);
$node->set('field_domaine_du_document', array_map(function($id) {
return ['target_id' => $id];
}, $ids_de_domaine));Avantages de l'approche basée sur le nom :
- Correspondance sémantique – L'IA peut utiliser sa compréhension pour faire correspondre les concepts de manière sémantique, même lorsque les noms de termes exacts n'apparaissent pas dans le document
- Flexibilité – si les termes de taxonomie sont renommés, la recherche continue à fonctionner (tant que les noms correspondent)
- Clarté – les noms des termes sont lisibles par l'homme, ce qui facilite le débogage et la validation
- Précision – la recherche assure des correspondances exactes dans le vocabulaire de la taxonomie, évitant l'ambiguïté
Comment cela fonctionne :
- L'IA renvoie les noms des termes basés sur la compréhension sémantique du document
- Le système effectue une recherche de taxonomie pour trouver les ID de termes correspondants
- Les champs du document sont remplis avec les IDs de termes pour les références d'entités
Comment gérer les termes ambigus ?
Certains termes sont véritablement ambigus :
"ICO" pourrait signifier :
- Bureau du commissaire à l'information (protection des données)
- Initial Coin Offering (cryptomonnaie)
Stratégie 1 : Indices de contexte dans l'invite
Si le document traite de la protection des données, "ICO" signifie probablement "Bureau du commissaire à l'information".
Si le document parle de cryptomonnaie, "ICO" signifie probablement "Initial Coin Offering".
Utilisez le contexte du document pour dissiper l'ambiguïté.Stratégie 2 : Autoriser plusieurs options
Si c'est ambigu, retournez plusieurs noms de termes possibles :
{
"organisation": ["Bureau du commissaire à l'information", "Initial Coin Offering"]
}Le système cherchera les deux noms et renverra leurs ID. L'examinateur humain choisit ensuite la bonne option parmi celles proposées.
Stratégie 3 : Scores de confiance (avancé)
{
"organisation": [
{"term_name": "Bureau du commissaire à l'information", "confidence": 0.8},
{"term_name": "Initial Coin Offering", "confidence": 0.2}
]
}Sélectionnez la plus grande confiance, marque pour examen la basse confiance (<0.7). Le système mappe les noms des termes sur les ID après la sélection.
Lisez aussi : Traitement des documents par l'IA dans Drupal : Étude de cas technique avec une précision de 95%
Comment optimiser les invites pour une meilleure précision ?
Même avec la bonne structure et les bonnes taxonomies, obtenir une haute précision nécessite un affinement continu. Voici comment améliorer systématiquement vos invites en fonction des performances réelles.
Processus d'affinement itératif
Ne vous attendez pas à des invites parfaites dès la première tentative. Itérez.
Utilisez des documents réels, pas des exemples synthétiques.
Lorsque vous n'êtes pas sûr de la meilleure approche, testez les deux :
Invite A : Concise
Catégoriser en utilisant ces taxonomies :
[taxonomies]
Document :
[document]
Retour JSON :
[schema]Invite B : Verbeuse
Vous êtes un analyste expert en documents juridiques. Votre tâche consiste à lire attentivement
le document fourni et à le catégoriser selon les taxonomies ci-dessous.
Instructions :
- Lisez le document en détail
- Identifiez le type de document
- Déterminez l'organisation émettrice
- Extrayez tous les domaines d'intérêt pertinents
[... directives détaillées ...]
Taxonomies :
[taxonomies]
Document :
[document]
Veuillez retourner votre analyse en JSON :
[schema]Comment extraire les obligations légales des documents ?
Extraire des obligations est plus difficile que de catégoriser car :
- Obligations implicites – pas toujours explicitement énoncées
- Obligations conditionnelles – “si X, alors doit Y”
- Identification de la portée – qui doit se conformer ?
- Extraction de la date limite – quand la conformité doit-elle avoir lieu ?
Identification des obligations implicites
Obligation explicite : > “Toutes les banques doivent soumettre des rapports trimestriels à la FCA.”
Obligation implicite : > “L'Autorité attend des rapports trimestriels des entités réglementées.”
“Attends” implique une obligation dans un contexte réglementaire.
Guidance d'invite :
Extraire les obligations légales incluant :
- DOIT/DEVRAS/REQUIS (explicite)
- DEVRAIS/EST ATTENDU/RECOMMANDÉ (guidance forte, souvent traité comme des obligations)
- Exigences implicites dans un contexte réglementaire
Pour chaque obligation, extraire :
- Quelle action est requise
- Qui doit la réaliser (parties affectées)
- Quand cela doit être effectué (date limite/fréquence)
- Ce qui arrive si cela n'est pas fait (conséquences, si indiqué)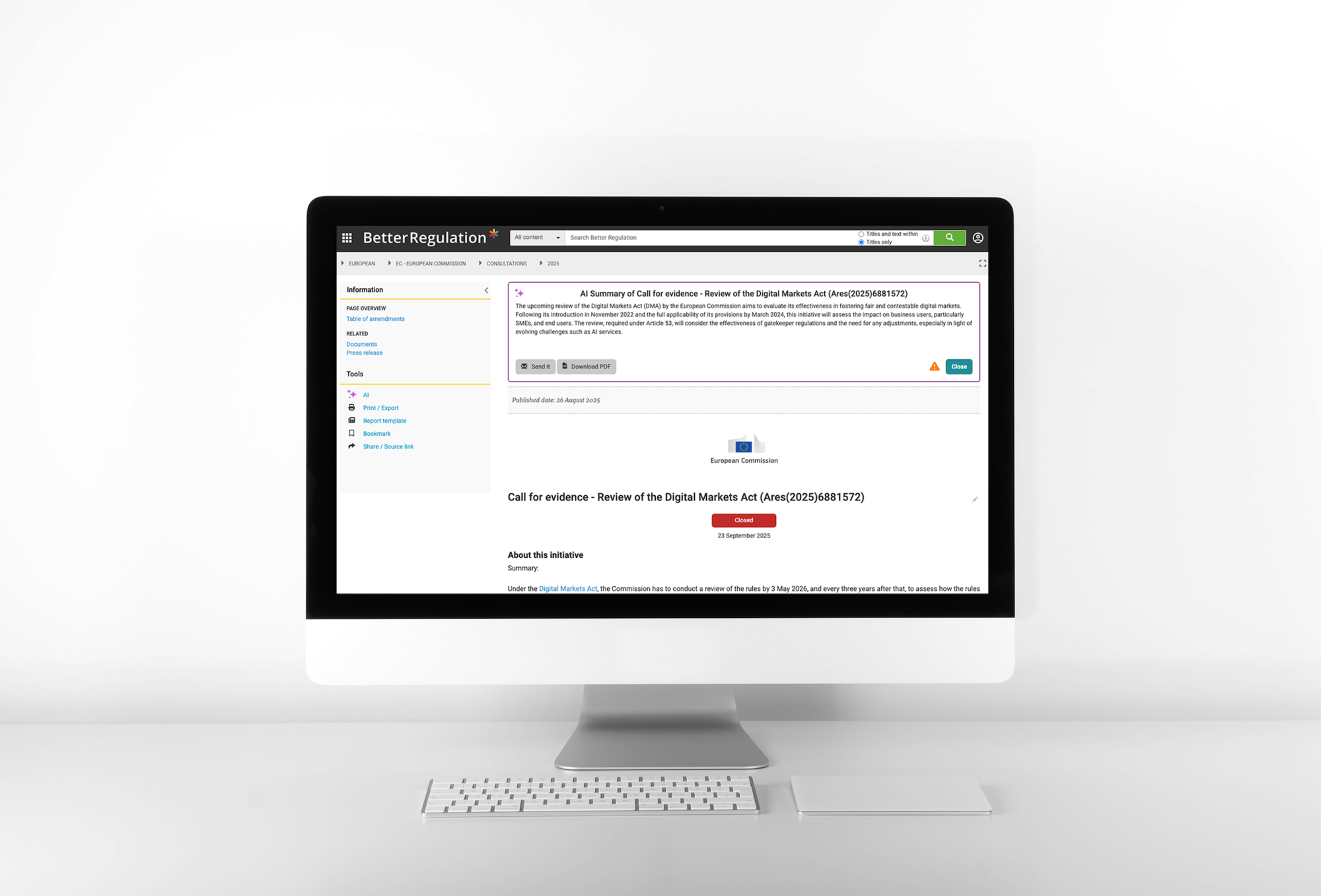
Une solution basée sur l'IA pour la synthèse automatisée de documents et l'extraction d'obligations chez Better Regulation
Voyez comment nous générons des résumés de documents IA et extrayons des obligations →
Information manquante
Que faire si le document ne contient pas les informations attendues?
Conseils pour l'invite :
Si l'information ne peut être déterminée à partir du document :
- Retournez un tableau vide [] pour ce champ
- N'INVENTEZ PAS ni ne devinez l'information
- Ne retournez PAS null ou undefined
Exemple :
{
"source_url": "" // Non trouvé dans le document
}
PAS :
{
"source_url": "https://www.example.com" // Ne pas inventer des URLs
}Plusieurs interprétations valides
Certains documents conviennent légitimement à plusieurs catégories.
Exemple : Le document discute à la fois de la réglementation bancaire et de la protection des données.
Stratégie d'invite :
document_area est un champ à multiples valeurs.
Si le document couvre plusieurs domaines, incluez TOUS les domaines pertinents :
{
"document_area": ["Régulation Bancaire", "Protection des Données"]
}
Préférez inclure tous les domaines pertinents plutôt que de forcer une seule sélection.
Le système mappera automatiquement ces noms de termes à leurs ID correspondants.A lire également : AI Automators in Drupal. Comment Orchestrer des Workflows AI en plusieurs étapes ?
Exemples de codes et modèles d'invites
Maintenant que nous avons couvert les techniques, voici des modèles d'invites prêts à l'emploi que vous pouvez adapter pour vos propres projets d'extraction de documents juridiques. Ces modèles intègrent toutes les stratégies discutées ci-dessus. Pour des applications plus larges, voyez comment utiliser les modules AI de Drupal pour la création de contenu.
Invite de catégorisation complète
Vous analysez un document juridique ou réglementaire du Royaume-Uni/ Irlande.
Extrayez et catégorisez en utilisant ces taxonomies exactes.
RÈGLES CRITIQUES :
- Utilisez UNIQUEMENT les noms de termes de taxonomie des listes ci-dessous (renvoyez les noms de termes en tant que chaînes)
- Renvoyez du JSON valide dans le format spécifié
- Faites correspondre par signification sémantique, pas seulement par mots clés
- Si plusieurs termes s'appliquent, incluez tous ceux pertinents
- En cas de doute, renvoyez un tableau vide []
- Le système mappera automatiquement les noms de termes aux ID de termes
### TAXONOMIE DU TYPE DE DOCUMENT :
- Statut
- Régulation
- Note d'orientation
- Code de pratique
- Jurisprudence
### TAXONOMIE DE L'ORGANISATION :
- Autorité de conduite financière
- Banque d'Angleterre
- Autorité de la concurrence et des marchés
- Bureau du commissaire à l'information
- Trésor de Sa Majesté
[... liste complète...]
### TAXONOMIE DE LA ZONE DU DOCUMENT :
- Banque et finance
- Crédit à la consommation
- Réglementation bancaire
- Services de paiement
- Protection des données
- Droit de la concurrence
[... liste complète...]
### DOCUMENT À ANALYSER :
{{ document_text }}
Renvoyez du JSON avec les noms de termes de taxonomie (chaînes), pas les ID.
Exemple :
{
"document_type": ["Note d'orientation"],
"organization": ["Autorité de conduite financière"],
"document_area": ["Crédit à la consommation", "Réglementation bancaire"]
}Invite d'extraction des obligations
Extrayez les obligations juridiques de ce document.
Une obligation est une exigence que certaines parties doivent remplir.
Pour chaque obligation, identifiez :
- Quelle action est requise
- Qui doit la réaliser (parties concernées/types de licences)
- Quand (date limite ou fréquence)
Incluez :
- Les obligations explicites (DOIT, DOIVENT, REQUIS)
- Les orientations fortes (DEVRAIT, ESPÉRÉ, RECOMMANDÉ)
- Les exigences implicites du contexte réglementaire
### TYPES DE LICENCE :
- Prêteurs de crédit à la consommation
- Locataires de crédit à la consommation
- Fournisseurs de services de paiement
[... liste complète...]
Renvoyez les noms de termes de taxonomie (chaînes) pour les types de licences. Le système mappera automatiquement ces noms aux ID.
### DOCUMENT :
{{ document_text }}
Ingénierie des invites pour l'extraction de données - conclusion
Pour réaliser efficacement une ingénierie des invites pour l'extraction de documents juridiques, il faut :
- Injection de taxonomie – inclure des listes de taxonomie complètes (seulement les noms de termes ; le système relie les noms aux ID)
- Application du schéma JSON – définir la structure exacte de sortie
- Adéquation sémantique – tirer parti de la compréhension de la signification par l'IA
- Amélioration itérative – tester, mesurer, améliorer
- Analyse des modèles d'erreur – corriger systématiquement les erreurs spécifiques
- Gestion des cas limites – prévoir les limites de taille, les données manquantes, l'ambiguïté
Résultats de BetterRegulation :
- Plus de 95% de précision sur le champ
- Moins de 5% de taux de correction par l'éditeur
- 2 mois d'améliorations itératives (75% → 95%)
- Affinement mensuel des invites en fonction de l'analyse des erreurs
La leçon clé : L'ingénierie des invites n'est pas un processus terminé. Il s'agit d'une amélioration continue basée sur les performances du monde réel.
Commencez simplement. Testez minutieusement. Peaufinez systématiquement. Vos invites s'amélioreront avec le temps.
Avez-vous besoin d'une ingénierie d'invite experte pour votre projet d'IA ?
Ce guide est basé sur notre travail d'ingénierie d'invite de production pour BetterRegulation, où nous avons développé et affiné des invites sur deux mois pour atteindre une précision de plus de 95% dans l'extraction de documents juridiques. La clé était l'itération systématique : commencer avec des invites basiques à 75% de précision, analyser les modèles d'erreur, affiner les instructions, et améliorer progressivement jusqu'à une performance de production. Cette approche itérative de l'ingénierie des invites a transformé un prototype en un système fiable traitant des milliers de documents par mois.
La construction d'invites efficaces nécessite à la fois une expertise technique et une compréhension du domaine. Notre équipe se spécialise dans l'ingénierie des invites pour des tâches complexes d'extraction de données. Nous nous occupons du cycle complet : conception initiale de l'invite, intégration de la taxonomie, définition du schéma JSON, tests itératifs, analyse des erreurs, et optimisation continue. Visitez nos services de développement d'IA génératrice pour découvrir comment nous pouvons vous aider à développer des invites prêtes pour la production qui fournissent des résultats cohérents et précis.










