
Termes d'IA Que Vous Devez Connaître. Première Partie – 13 Phrases Fondamentales en Intelligence Artificielle

Après la « révolution de l’IA de 2022 », une conclusion est simple : l’IA n’est pas une mode passagère, mais elle restera avec nous pendant un certain temps. Cela a engendré de nouveaux postes dans l’industrie et de nombreuses nouvelles expressions. Il existe de nombreux termes lorsque l’on parle d’IA. Certains sont explicites, et d’autres peuvent être confus et peu clairs. Espérons qu’après avoir lu nos articles sur ce sujet, vous ne serez pas surpris lorsque quelqu’un vous lancera cette nouvelle terminologie.
Termes de base de l’intelligence artificielle
Nous divisons l’explication des termes de l’IA en deux parties. Dans cet article, nous couvrirons certains termes de base de l’intelligence artificielle qui vous aideront à rester à la pointe de la conversation et à ancrer votre compréhension des connaissances liées à l’IA. Dans l’article suivant, nous nous concentrerons sur une terminologie plus spécialisée et expliquerons les mécanismes internes des solutions d’IA existantes.
Intelligence Artificielle (IA)
L’Intelligence Artificielle (IA) est un vaste domaine de l’informatique visant à créer des machines capables d’accomplir des tâches nécessitant normalement l’intelligence humaine. Cela inclut la résolution de problèmes, la reconnaissance de motifs et la compréhension du langage naturel. Ce terme ne couvre pas seulement les Réseaux de Neurones Artificiels, mais également des solutions comme les Algorithmes Génétiques, la Logique Floue, etc.
Modèle d’IA/Check-point/Déploiement du modèle
C’est l’une des parties les plus confuses du discours général.
- Modèle d’IA – cela désigne l’architecture d’un système d’intelligence artificielle. Il comprend la structure des réseaux de neurones (comme les couches, les neurones, etc.), les algorithmes qu’il utilise et les paramètres qui définissent son comportement. Un modèle est une construction théorique qui définit comment l’IA traite les données d’entrée pour produire des résultats.
- Check-point – un check-point est un état enregistré d’un modèle entraîné à un moment précis. Il inclut tous les paramètres, poids, et biais que le modèle a appris jusqu’à ce point. Les check-points sont utilisés pour mettre en pause et reprendre l’entraînement, pour la récupération en cas d’interruptions et pour déployer un modèle entraîné dans différents environnements. Ils représentent une instance spécifique d’un modèle avec ses connaissances apprises à une certaine étape de l’entraînement.
- Déploiement du modèle – lorsque vous avez un modèle, vous devez ensuite le « déployer ». Cela englobe la création ou l’utilisation d’applications ou de scripts disponibles (plus de détails dans le second article) pour fournir une interface d’interaction avec le modèle. Cela comprend également des infrastructures comme un serveur avec GPU, une interface web, ou une API pour que les utilisateurs interagissent avec le modèle.
Pour réitérer, lorsque vous dites, « J’utilise ChatGPT », vous vous référez à tout le système qui permet l’interaction avec le modèle « ChatGPT ».
Big Data
Ce terme d’IA se réfère à des ensembles de données extrêmement volumineux qui sont si complexes et volumineux que les outils de traitement de données traditionnels ne suffisent pas à les gérer et à les analyser.
L’importance du Big Data réside non seulement dans sa taille mais aussi dans sa complexité et la vitesse à laquelle il est généré et traité. Il est traditionnellement caractérisé par ce qui est connu comme les trois V – Volume, Vélocité, et Variété:
- Volume – fait référence à l’immensité des données collectées à partir de diverses sources comme les transactions, les réseaux sociaux, les capteurs, etc. La croissance du volume de données a été facilitée par la disponibilité d’options de stockage moins coûteuses comme les data lakes, Hadoop, et le stockage en cloud.
- Vélocité – cet aspect du Big Data concerne la vitesse à laquelle les données sont générées et doivent être traitées.
- Variété – le Big Data se présente sous divers formats – des données structurées, numériques dans les bases de données traditionnelles aux textes non structurés, vidéos, audio, et plus encore.

Chatbot
C’est une application logicielle conçue pour mener des conversations en ligne soit par texte ou par synthèse vocale, simulant une interaction humaine. Le premier exemple notable était « Eliza », créé en 1966 par Joseph Weizenbaum. Eliza fonctionnait en analysant les motifs de phrases des entrées des utilisateurs et en employant la substitution de mots-clés et le réarrangement de l’ordre des mots pour formuler des réponses, créant une illusion de compréhension. Son script « DOCTOR », imitant un psychothérapeute Rogerien, était particulièrement réputé pour engager les utilisateurs dans des conversations apparemment significatives.
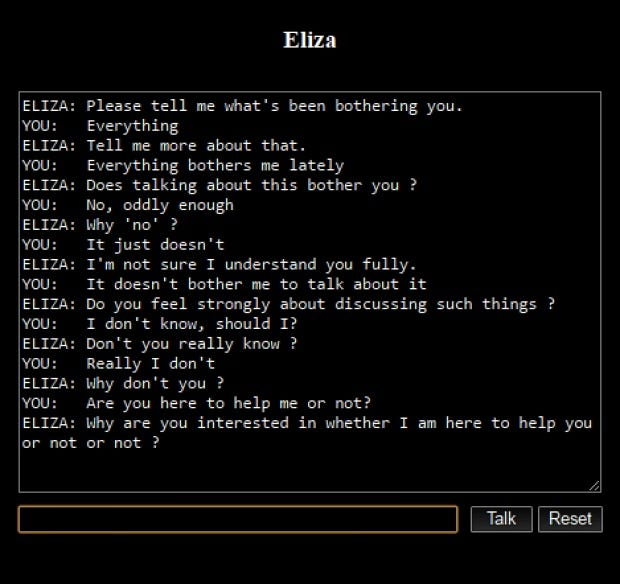
Source: medium.com
Le domaine des chatbots a considérablement évolué depuis ces premiers exemples. Les chatbots modernes comme ChatGPT et Google Bard exploitent des technologies avancées d’IA et d’apprentissage automatique. Ces versions contemporaines excellent dans la compréhension du contexte, la gestion de dialogues complexes, et la fourniture de réponses informatives et cohérentes, dépassant de loin les capacités de leurs prédécesseurs.
Modèle de diffusion
Le modèle de diffusion est une classe de modèles génératifs. Ils consistent généralement en trois composants principaux : échantillonnage, processus direct et processus inverse. Dans le contexte moderne, ce terme se réfère généralement au processus de génération d’images.
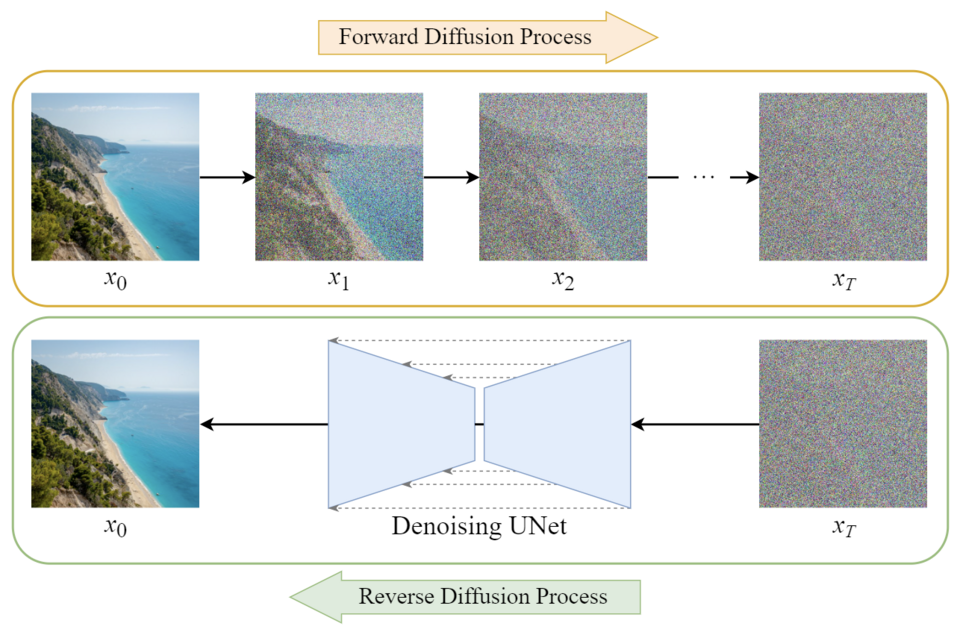
Source: towardsai.net
Dans le domaine de la génération d’images, les modèles de diffusion sont entraînés sur des ensembles d’images avec du bruit artificiel ajouté. La tâche du modèle est de retirer progressivement ce bruit, apprenant ainsi à recréer l’image originale.
Ce processus permet au modèle de générer de nouvelles images basées sur une combinaison d’entrées utilisateur et d’un échantillon de bruit latent. L’opération des modèles de diffusion peut être résumée de manière familière par la phrase « Je vois un visage dans cet arc-en-ciel », illustrant métaphoriquement comment ces modèles discernent des images structurées à partir de motifs de bruit apparemment aléatoires.
Exemple d’un modèle de diffusion en action, généré dans Midjourney
Affinage
Ce terme d’IA se réfère au processus de modification d’un modèle d’IA déjà entraîné pour l’adapter à un nouvel ensemble de données ou une nouvelle tâche spécifique. Cela implique « d’insérer de nouvelles connaissances » dans le modèle. Par exemple, si vous souhaitez adapter un modèle OpenAI pour répondre à des questions basées sur les données de votre site web, vous affineriez le modèle existant avec un ensemble de données provenant de votre page web.
L’affinage peut prendre du temps pour les modèles plus grands et nécessite souvent des mécanismes supplémentaires pour s’adapter aux changements de données. Par exemple, l’ajout d’un nouvel article de blog à votre site peut nécessiter de réentraîner le modèle pour incorporer cette nouvelle information. L’affinage permet de personnaliser les modèles d’IA à des domaines ou des exigences spécifiques sans avoir besoin de les entraîner à partir de zéro.
IA Générative
Le terme d’IA générative se réfère à un sous-ensemble de modèles d’IA. Ils sont conçus pour générer de nouveaux contenus, en s’appuyant sur les motifs et les connaissances appris de leurs données d’entraînement et des entrées utilisateur. De tels modèles sont capables de tâches créatives, telles que rédiger de nouvelles pièces avec le ton de voix d’auteurs spécifiques ou créer des œuvres d’art et de la musique imitant certains styles.
Par exemple, un modèle entraîné sur les œuvres de Shakespeare serait capable de générer de nouveaux poèmes ou passages texte qui imitent son style unique et ses nuances linguistiques. L’aspect clé de l’IA Générative est sa capacité à produire des sorties originales qui sont cohérentes et contextuellement pertinentes, semblant souvent avoir été créées par un humain.
Une conversation avec ChatGPT
Modèle de Langage Étendu (MLE)
Ce terme décrit une classe de modèles d’IA qui sont entraînés sur de vastes quantités de données en langage naturel. Leur fonction principale est de comprendre, traiter et générer du texte semblable à celui d’humain. Les MLE réalisent cela en apprenant à partir d’un large éventail d’entrées linguistiques et en utilisant des probabilités statistiques pour recréer et produire de nouveaux contenus.
Ces modèles sont non seulement aptes à générer un texte qui est cohérent et contextuellement pertinent. Ils sont également capables d’accomplir diverses tâches liées au langage telles que la traduction, le résumé et la réponse à des questions. La taille et la diversité des données d’entraînement permettent à ces modèles d’avoir une « compréhension » étendue du langage, du contexte et des nuances.
Traitement du Langage Naturel (PLN)
Le PLN est un domaine à l’intersection de l’informatique, de l’intelligence artificielle et de la linguistique. Il se concentre sur l’habilitation des ordinateurs à comprendre, interpréter et générer le langage humain de manière précieuse et significative. Les tâches critiques en PLN incluent la traduction linguistique, l’analyse des sentiments, la reconnaissance vocale et le résumé de texte.
L’objectif est de créer des systèmes pouvant interagir avec les humains par le biais de la langue, en extrayant des informations des données texte ou vocale et générant des réponses similaires à celles d’un humain. Le PLN combine des techniques computationnelles avec des connaissances spécifiques au langage pour traiter efficacement et analyser de grandes quantités de données en langage naturel.
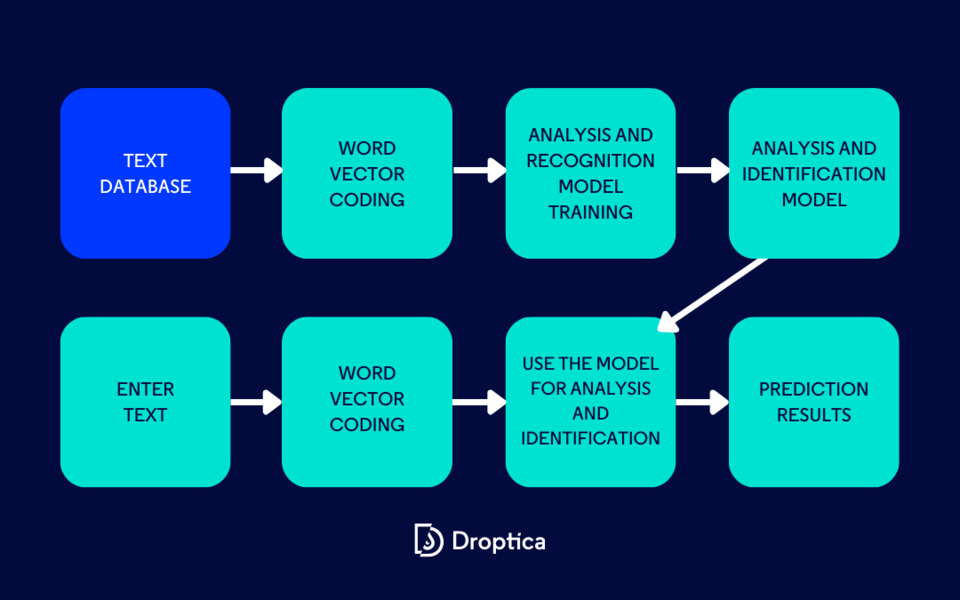
Reconnaissance Optique de Caractères (OCR)
L’OCR est le processus de conversion d’images de texte manuscrit ou imprimé en texte encodé par machine. Largement utilisé comme une forme de saisie de données, c’est une méthode courante utilisée pour numériser le texte imprimé afin qu’il puisse être stocké, édité, recherché, ou transmis dans un Modèle de Langage Étendu.
Prompt
Dans le contexte de l’IA, un prompt est une entrée fournie par l’utilisateur qui dirige un modèle d’IA pour générer une sortie spécifique. Il sert de guide ou d’instruction pour l’IA, influençant ses réponses ou le contenu qu’il génère. Les prompts peuvent varier largement – des questions simples aux scénarios complexes – et sont essentiels pour déterminer comment le modèle d’IA interprète et répond aux requêtes des utilisateurs.
Ingénierie des Prompts
Ce champ émergent est centré autour de l’optimisation des interactions avec les modèles d’IA pour obtenir les résultats souhaités. L’ingénierie des prompts implique une compréhension approfondie de la façon dont les modèles d’IA traitent le langage naturel et la création de prompts pour diriger l’IA vers des solutions ou des réponses spécifiques.
Il est particulièrement pertinent dans le contexte des grands modèles de langage, où la façon dont un prompt est formulé peut avoir un impact significatif sur la sortie du modèle. Ce domaine gagne en importance à mesure que les systèmes d’IA deviennent plus répandus et sophistiqués, nécessitant des techniques compétentes pour exploiter efficacement leurs capacités.
Jeton
Dans le domaine des Modèles de Langage Étendu, un jeton est une unité fondamentale de texte que le modèle traite. Le concept de jeton découle du processus de « tokenization », où le texte d’entrée est divisé en plus petits morceaux ou jetons. Ces jetons sont ensuite utilisés par le modèle pour comprendre et générer du texte. Il est important de noter qu’un jeton ne correspond pas nécessairement à un seul caractère. En anglais, par exemple, un jeton pourrait représenter un mot ou une partie d’un mot, typiquement une moyenne d’environ quatre caractères en longueur.
La définition précise d’un jeton peut varier selon le modèle de langage et les spécificités de son algorithme de tokenization. Les jetons sont cruciaux pour que les modèles traitent les entrées en langage naturel et génèrent des réponses ou textes cohérents, car ils déterminent la granularité à laquelle le modèle interprète l’entrée.
Termes de base de l’IA – résumé
Dans cet article, nous avons exploré l’importance des termes et concepts de l’IA et espérons avoir clarifié certains jargons et confusions. Comprendre ces expressions de base est essentiel pour quiconque souhaite s’impliquer dans le domaine croissant de l’intelligence artificielle – que ce soit pour évoluer professionnellement ou par curiosité personnelle. Si vous avez besoin de transformer l’un de ces domaines en un projet spécifique, vous pouvez obtenir de l’aide de nos spécialistes expérimentés en services de développement IA.










