

Le traitement des documents par l'IA transforme la gestion du contenu dans Drupal. Grâce à l'intégration avec les automatisateurs de l'IA, Unstructured.io et les modèles GPT, les équipes éditoriales peuvent automatiser des tâches fastidieuses comme l'extraction des métadonnées, l'appariement de la taxonomie et la génération de résumés. Cette étude de cas révèle comment BetterRegulation a mis en œuvre le traitement des documents par l'IA dans leur plateforme Drupal 11, atteignant une précision de 95%+ et une économie de temps éditorial de 50%.
Dans cet article:
- Introduction: pourquoi utiliser le traitement des documents par l'IA dans Drupal?
- Contexte du projet: quel problème le traitement des documents par l'IA résout-il?
- Comment fonctionne le traitement des documents par l'IA dans Drupal?
- Comment mettre en œuvre le traitement des documents par l'IA dans Drupal
- Quels sont les principaux défis techniques dans le traitement des documents par l'IA?
- Comment garantir la fiabilité de la production pour le traitement des documents par l'IA?
- Optimisation des performances et des coûts pour le traitement des documents par l'IA
- Quelles leçons avons-nous tirées de la mise en œuvre du traitement des documents par l'IA?
- Quels outils et ressources avez-vous besoin pour le traitement des documents par l'IA?
- Prêt à mettre en œuvre le traitement des documents par l'IA dans Drupal?
Introduction: pourquoi utiliser le traitement des documents par l'IA dans Drupal?
Drupal est depuis longtemps une référence en matière de gestion de contenu, en particulier pour les contenus complexes et structurés. Mais à mesure que les volumes de contenu augmentent et que les attentes des utilisateurs évoluent, le traitement manuel des documents devient un goulot d'étranglement.
Le traitement des documents par l'IA automatise l'extraction, la classification et l'organisation des informations à partir des documents à grande échelle. L'IA avec Drupal rend cela possible pour les flux de travail de gestion de contenu. Imaginez :
- Des documents auto-catégorisés dans 15 champs de métadonnées avec une précision de 95%.
- Des résumés générés automatiquement pour chaque élément de contenu.
- Des références d'entités créées intelligemment sur la base de la compréhension sémantique.
- Des équipes éditoriales libérées de la saisie de données fastidieuse pour se concentrer sur la stratégie.
Ce n'est pas une ambition, c'est une réalité de production. BetterRegulation, une plateforme de conformité juridique basée sur Drupal 11, a ajouté des capacités d'IA à leur système existant et traite désormais plus de 200 documents juridiques complexes par mois, atteignant :
- Une économie de temps de 50% dans le traitement des documents
- Une libération de 1 ETP pour des travaux de plus grande valeur
- Une précision de >95% dans l'auto-catégorisation
- Un ROI de moins de 12 mois
Cet article partage l'architecture technique, les décisions clés et les leçons apprises d'une mise en œuvre réelle qui traite plus de 200 documents juridiques par mois.
Les principales idées que vous obtiendrez :
- Des décisions d'architecture pour le traitement automatisé des documents : pourquoi AI Automators, Unstructured.io et GPT-4o-mini.
- Comment atteindre une précision de 95%+ dans l'appariement automatisé de la taxonomie.
- Des stratégies réelles d'optimisation des coûts (économies de plus de 2 000 £/an).
- Les défis et les solutions de production (mécanisme de retard de 15 minutes, limites des tokens).
- Quand utiliser les automatisateurs de l'IA vs le code personnalisé pour l'automatisation des documents.
A qui s'adresse cet article : Les chefs de projet techniques et les développeurs évaluant l'intégration du traitement des documents par l'IA pour les plateformes Drupal existantes.
Contexte du projet : quel problème le traitement des documents par l'IA résout-il?
BetterRegulation disposait déjà d'une plateforme Drupal 11 mature gérant des milliers de documents juridiques. Le défi consistait à intégrer les capacités de traitement des documents par l'IA dans leur flux de travail existant sans perturber les éditeurs ou nécessiter une refonte complète.
L'objectif était simple mais ambitieux : automatiser le traitement des documents par l'IA pour lire les PDF, extraire les métadonnées, appairer les taxonomies et générer des résumés, tandis que les éditeurs se concentrent sur le contrôle de la qualité et la curation stratégique du contenu.
Deux principales caractéristiques ont été développées :
1. Remplissage automatique des champs du document (type de contenu Know How) - téléchargez un PDF, cliquez sur "Générer avec l'IA", et observez comment plus de 15 champs se remplissent automatiquement avec le type de document, l'organisation, l'année, les références législatives, et plus encore. Le traitement se fait en temps réel (1-2 minutes) afin que les éditeurs puissent immédiatement examiner et ajuster les champs remplis.
2. Résumés générés par l'IA (types de contenu General Consultation, Station, Know How) - créez automatiquement trois types de résumés:
- Résumé détaillé (~200 mots) - aperçu complet.
- Résumé court (~50 mots) - synopsis d'un paragraphe.
- Résumé des obligations - obligations légales extraites et exigences réglementaires.
La génération de résumé s'exécute en arrière-plan avec un retard de 15 minutes pour éviter le retraitement lors des modifications rapides.
L'implémentation devait être :
- Non disruptive : travailler au sein des types de contenu existants et des flux de travail.
- Configurable : permettre les mises à jour des invites et de la taxonomie sans déploiement de code.
- Fiable : gérer les cas limites comme les documents de 350 pages et la terminologie juridique complexe.
- Économique : traiter plus de 200 documents par mois sans dépasser le budget.
Ce guide montre comment nous avons atteint tous ces objectifs en utilisant l'écosystème de modules IA de Drupal.
Comment le traitement de documents par l'IA fonctionne-t-il dans Drupal?
Comprendre la pile technique est crucial pour évaluer cette approche pour vos propres projets. L'implémentation du traitement des documents par l'IA de BetterRegulation combine cinq composantes principales qui travaillent ensemble pour traiter les documents de l'upload PDF aux champs de contenu remplis.
Quelle est la technologie qui alimente le traitement de documents par l'IA?
L'implémentation de l'IA de BetterRegulation utilise cinq composantes clés:
1. Remplissage automatique des champs de documents (Bouton Générer avec l'IA)
┌─────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Forme de création de contenu │ │
│ │ [ Upload PDF ] [ Bouton Générer avec l'IA ] │ │
│ └───────────┬───────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Automatiseurs IA │ │
│ │ (moteur de flux de travail) │ │
│ │ + API Batch │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Unstructured.io │ │
│ │ (PDF→texte propre) │ │
│ │ Pod auto-hébergé │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (Traitement IA) │ │
│ │ API OpenAI │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Réponse JSON (champs préremplis) │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Automatiseurs IA │ │
│ │ (analyser & remplir) │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Champs préremplis │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Forme de création de contenu │ │
│ │ [ Champs auto-remplis, prêts pour révision ] │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (journalisation) │ │
│ └───────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
2. Résumés générés par l'IA (traitement en arrière-plan)
┌─────────────────────────────────────────────────────────────┐
│ Drupal 11 │
│ │
│ Enregistrer le document │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ File d'attente RabbitMQ │ │
│ │ (Retard de 15 minutes) │ │
│ └───────┬──────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Automatiseurs IA │ │
│ │ (moteur de flux de travail) │ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ GPT-4o-mini │ │
│ │ (gen résumé) │ │
│ │ API OpenAI │ │
│ └───────┬───────────────┘ │
│ │ │
│ │ Résumés générés │
│ │ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Automatiseurs IA │ │
│ │ (sauvegarder dans les champs)│ │
│ └───────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────┐ │
│ │ Mise à jour du document │ │
│ │ [ Résumés sauvegardés dans les champs de contenu ]│ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ ┌───────────────────────────────────┐ │
│ │ Watchdog (journalisation) │ │
│ └───────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
Que fait chaque composant dans le pipeline de traitement de documents par l'IA?
Drupal 11 sert de fondation à tout le système, fournissant la plateforme de gestion de contenu, la structure des entités et l'interface utilisateur. Il orchestre le flux de travail et stocke toutes les données du document, agissant comme le hub central où les éditeurs interagissent avec le contenu et où les résultats traités par l'IA vivent finalement.
Les Automatiseurs IA de Drupal est le module contrib qui fait le pont entre Drupal et les services d'IA. Au lieu de construire du code d'intégration personnalisé, ce module fournit une approche basée sur la configuration pour définir les flux de travail de l'IA. Il gère les invitations, traite les réponses de plusieurs fournisseurs d'IA (OpenAI, Anthropic, etc.), et orchestre les processus en plusieurs étapes à travers une interface d'administration intuitive. Cela signifie que la création et la modification des flux de travail de l'IA deviennent une tâche de configuration plutôt qu'un projet de développement. Pour en savoir plus sur l'automatisation de l'IA dans Drupal, voir {www.droptica.com/blog/how-generate-image-alt-text-and-content-strategy-ai-modules-drupal how to generate image alt text and content strategy with AI modules}.
Unstructured.io fonctionne sur un pod auto-hébergé et gère la première étape critique : convertir les documents PDF désordonnés en texte structuré propre. Il analyse les mises en page des documents, préserve la structure, filtre les artefacts tels que les en-têtes et les numéros de page, et gère même l'OCR pour les documents scannés. Le résultat est un texte propre prêt à être traité par l'IA, qui est essentiel pour une catégorisation et une extraction de métadonnées précises.
GPT-4o-mini alimente l'analyse de l'IA grâce à l'API d'OpenAI. Une fois qu'il reçoit le texte propre provenant d'Unstructured.io, il effectue l'analyse du document, fait correspondre le contenu avec la taxonomie de BetterRegulation, extrait les métadonnées, et génère les résumés. Le modèle renvoie des réponses JSON structurées que les Automatiseurs Drupal peuvent analyser et remplir automatiquement dans les champs de contenu appropriés.
RabbitMQ gère le traitement des tâches en arrière-plan, en particulier pour la génération de résumés, qui prend beaucoup de temps. Lorsqu'un utilisateur enregistre ou modifie un document, la création du résumé est automatiquement mise en file d'attente avec un délai de 15 minutes. Cette décision de conception est née d'un besoin pratique : les éditeurs effectuent souvent plusieurs modifications rapides sur les documents, et le traitement des résumés après chaque enregistrement entraînerait un gaspillage des coûts API et du temps de traitement. Le délai de 15 minutes permet aux éditeurs de finaliser leurs modifications avant que le traitement par l'IA ne commence. Cela évite les traitements redondants et permet au système d'évoluer horizontalement en traitant plusieurs résumés sur différents postes de travail.
Watchdog, le système de journalisation central de Drupal, capture chaque étape du processus. Du téléchargement du PDF à la réponse de l'IA, chaque action, erreur et mesure de performance est consignée. Cette journalisation complète s'est avérée essentielle pendant le développement pour le débogage des flux de travail et continue d'être précieuse pour surveiller la santé du système en production.
Pourquoi choisir cette pile technologique pour le traitement des documents par IA ?
BetterRegulation disposait déjà de Drupal 11 comme plateforme de gestion de contenu lorsqu'elle a décidé d'ajouter des capacités d'IA. Le défi consistait à intégrer l'IA dans son flux de travail existant sans perturber les éditeurs ni nécessiter de changements architecturaux majeurs.
Le choix d'AI Automators plutôt que d'un code personnalisé a permis de gagner plusieurs semaines de développement. Au lieu d'écrire un code d'intégration standard pour l'API d'OpenAI, de gérer des modèles de invites et de créer des interfaces d'administration, nous avons configuré les flux de travail via une interface graphique. Cette approche de configuration plutôt que de codage signifie que les modifications futures, telles que l'ajout de nouvelles étapes d'IA ou le changement de fournisseur, peuvent être effectuées sans déployer de nouveau code. Le module est maintenu par la communauté, de sorte que les améliorations et les mises à jour de sécurité proviennent de l'écosystème Drupal au sens large.
Pour le traitement des PDF, Unstructured.io s'est révélé supérieur à l'extraction directe dans tous les indicateurs significatifs. Les tests initiaux avec des bibliothèques PDF standard ont montré une qualité d'extraction de 75 % et ont produit un texte rempli de numéros de page, d'en-têtes et d'artefacts de formatage. Unstructured.io a atteint une qualité de 94 % et a produit un texte propre qui a permis d'économiser 30 % sur les jetons IA. L'auto-hébergement du service sur leur infrastructure existante a éliminé les frais de traitement par document, le rendant économiquement viable même pour des milliers de documents.
Le choix de GPT-4o-mini plutôt que GPT-4 s'est basé sur des critères économiques et de suffisance. Bien que GPT-4 soit plus performant, GPT-4o-mini s'est avéré tout à fait suffisant pour la correspondance taxonomique et l'extraction de métadonnées. Avec un coût 10 fois inférieur et une fenêtre contextuelle de 128 Ko (suffisante pour des documents de 350 pages), il offrait un équilibre parfait entre performances et prix. La vitesse de traitement plus rapide était un bonus qui améliorait l'expérience de l'éditeur.
Pour une comparaison détaillée des différentes approches d'intégration de l'IA, lisez LangChain vs LangGraph vs Raw OpenAI : comment choisir votre pile RAG.
Comment implémenter le traitement de documents par IA dans Drupal
Une fois l'architecture établie, examinons comment ces composants ont été réellement construits et configurés. L'implémentation s'est concentrée sur l'exploitation des modules Drupal existants plutôt que sur la création d'un code personnalisé à partir de zéro.
L'approche de construction
Plutôt que de créer un code d'intégration IA personnalisé à partir de zéro, nous avons exploité le module AI Automators de Drupal, une approche basée sur la configuration qui a permis de gagner plusieurs semaines de développement et a fourni une fiabilité de niveau entreprise dès le départ.
Composants principaux créés
1. Service d'extraction de texte PDF
Nous avons créé un service Drupal personnalisé qui envoie des PDF à l'instance Unstructured.io auto-hébergée et reçoit du texte propre et structuré. Le service filtre les en-têtes, les pieds de page et les numéros de page, et préserve la structure du document, ce qui est essentiel pour une analyse IA précise.
Décision clé de mise en œuvre : filtrer uniquement les éléments Title, NarrativeTextet ListItem de la réponse d'Unstructured.io. Cela permet d'éliminer le bruit tout en préservant la structure logique du document.
2. Configuration du flux de travail Automator
À l'aide de l'interface d'administration d'AI Automators (/admin/config/ai/automator_chain_types/manage/summary/automator_chain), nous avons configuré un flux de travail en deux étapes :
- Étape 1 : Extraire le texte du PDF → le stocker dans le champ temporaire
- Étape 2 : Envoyer le texte + les taxonomies à GPT-4o-mini → recevoir la réponse JSON
Aucun code personnalisé n'est nécessaire pour l'intégration de l'API IA : AI Automators gère la gestion des fournisseurs, la logique de réessai et le traitement des erreurs.
3. Ingénierie des invites pour la correspondance taxonomique
Le secret d'une précision supérieure à 95 % : injecter des listes taxonomiques complètes directement dans l'invite.
La structure de l'invite se présente comme suit :
You are analyzing a legal document. Extract and categorize using these taxonomies:
### DOCUMENT TYPE TAXONOMY:
- Statute (ID: 12)
- Regulation (ID: 13)
- Guidance Note (ID: 14)
[... complete list with IDs ...]
### ORGANIZATION TAXONOMY:
- Financial Conduct Authority (ID: 23)
- Bank of England (ID: 24)
[... complete list with IDs ...]
[Document text here]
Return JSON:
{
"document_type": ["Statute", "Regulation"],
"organization": ["Financial Conduct Authority"],
"document_area": ["Data Protection", "Financial Services", "GDPR"],
...
}
Décisions critiques :
- Chargement dynamique de la taxonomie : le code PHP interroge les taxonomies Drupal et construit le contexte de l'invite à la volée. Les modifications apportées aux taxonomies ne nécessitent pas de mise à jour immédiate.
- L'IA renvoie les noms des taxonomies : l'IA renvoie les noms des termes taxonomiques (par exemple,
[« Protection des données », « Services financiers », « RGPD »]), et non les identifiants. Le système effectue ensuite une recherche pour faire correspondre ces noms aux identifiants des termes dans le système taxonomique de Drupal. Cette approche tire parti de la compréhension sémantique de l'IA tout en conservant des références d'entités précises. - Mappage nom-ID : après que l'IA a renvoyé les noms des termes, le système recherche dans le vocabulaire taxonomique les termes correspondants et récupère leurs ID. Par exemple :
« Protection des données »→ trouve l'ID de terme42,« Services financiers »→ trouve l'ID de terme87,« RGPD »→ trouve l'ID de terme156. Le document se voit alors attribuer le tableau d'ID :[42, 87, 156]. - Correspondance sémantique : l'IA comprend que « consumer lending » = « Consumer Credit Lenders » même sans correspondance exacte des mots-clés. L'approche basée sur les noms permet à l'IA d'utiliser sa compréhension sémantique pour faire correspondre les concepts, tandis que le système garantit la précision grâce à la correspondance exacte des noms de termes dans la recherche taxonomique.
Coût des jetons : l'ajout de taxonomies augmente la taille des invites d'environ 5 000 jetons par requête, ce qui coûte 0,03 £ supplémentaire par document. L'amélioration de la précision (75 % → 95 %) permet d'économiser plus de 12 minutes de correction manuelle par document, ce qui représente un retour sur investissement 70 fois supérieur.
4. Bouton « Générer avec l'IA »
Nous avons ajouté un bouton compatible AJAX au formulaire d'édition de contenu qui déclenche le flux de travail de traitement et remplit les champs en temps réel. L'éditeur voit les champs du formulaire se remplir automatiquement et peut les vérifier/ajuster avant de les enregistrer.
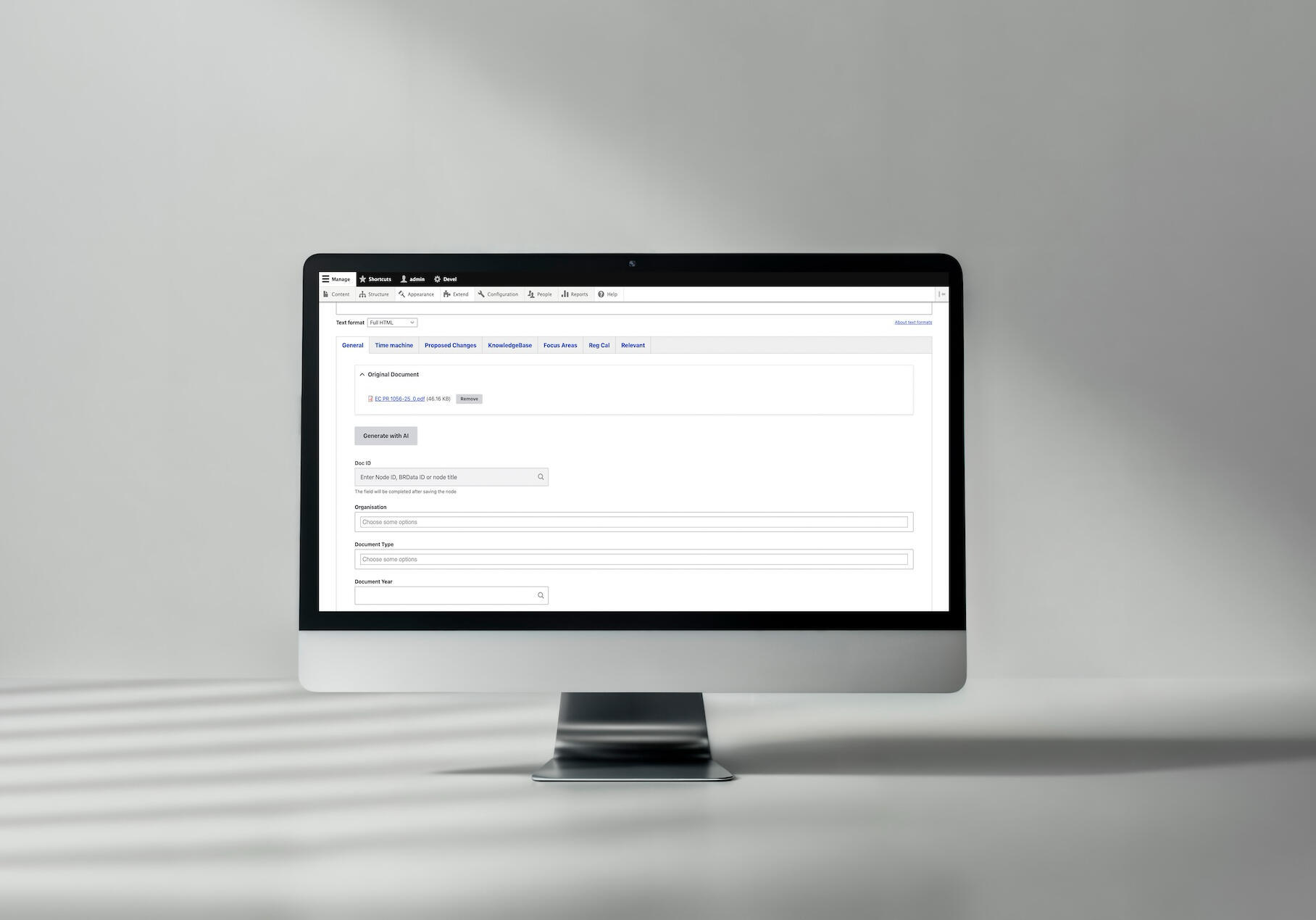
Un exemple de traitement de documents par IA que nous avons mis en œuvre pour Better Regulation
Lisez l'étude de cas complète sur la catégorisation de documents alimentée par l'IA ici →
-Quels sont les principaux défis techniques liés au traitement des documents par l'IA ?
Chaque intégration d'IA pose des défis uniques. Voici les trois obstacles techniques les plus importants rencontrés par BetterRegulation et la manière dont ils ont été surmontés.
Défi 1 : extraction automatisée de PDF pour le traitement des documents
Les documents juridiques sont réputés pour leur complexité :
- Mise en page sur plusieurs colonnes
- En-têtes/pieds de page sur chaque page
- Numéros de page intégrés au milieu d'une phrase
- Tableaux et notes de bas de page
Notre solution : la stratégie hi_res d'Unstructured.io avec filtrage des éléments pour un traitement propre des documents.
Résultats :
- qualité d'extraction de 94 % (contre 75 % avec les bibliothèques PDF standard)
- 30 % d'économies de tokens grâce au filtrage des artefacts
- Texte propre et structuré que l'IA peut analyser avec précision
Mise en œuvre clé : n'inclure que les éléments Title, NarrativeTextet ListItem. Ignorer les en-têtes, les pieds de page et les numéros de page.
Défi 2 : limite de jetons avec les documents volumineux
Certains documents comptent plus de 350 pages, dépassant la fenêtre contextuelle de 128 Ko de GPT-4o-mini.
Notre solution : stratégie de dégradation progressive.
- Calculer le nombre estimé de jetons avant l'envoi (1 jeton ≈ 4 caractères)
- Si >120 000 jetons : extraire uniquement les titres et les en-têtes de section
- Ajouter un champ d'administration pour les PDF condensés manuellement pour les cas limites
Compromis : précision légèrement inférieure pour les méga-documents (90 % contre 95 %), mais évite l'échec complet.
Défi 3 : correspondance sémantique de la taxonomie
Le problème : le document mentionne « pratiques de crédit à la consommation ». Le terme de taxonomie est « Prêteurs et emprunteurs de crédit à la consommation ». La correspondance traditionnelle par mot-clé échoue.
Notre solution : tirer parti de la compréhension sémantique du LLM.
- L'IA comprend que « crédit à la consommation » = « crédit à la consommation ».
- Reconnaît les acronymes (FCA = Financial Conduct Authority).
- Utilise le contexte pour lever l'ambiguïté (ICO = régulateur des données, et non cryptomonnaie).
Pourquoi la correspondance basée sur les noms fonctionne : l'IA renvoie des noms de termes tels que [« Crédit à la consommation », « Protection des données »], que le système associe ensuite à des identifiants de termes (par exemple, [35, 42]) grâce à la recherche dans la taxonomie. Cette approche combine la compréhension sémantique de l'IA avec des références d'entités précises : l'IA peut faire correspondre des concepts de manière sémantique, tandis que le système garantit l'exactitude en trouvant des correspondances exactes dans le vocabulaire de la taxonomie.
Lire aussi : Comment nous avons amélioré la précision du chatbot RAG de 40 % grâce à la notation des documents →
Comment garantir la fiabilité de la production pour le traitement des documents par l'IA ?
Le passage de la phase de validation du concept à la production nécessite une gestion et une surveillance robustes des erreurs. BetterRegulation a mis en place des mesures de protection complètes pour garantir la stabilité du système dans des conditions réelles.
Comment gérez-vous les erreurs dans le traitement des documents par l'IA ?
Journalisation complète : chaque étape est enregistrée dans le système Watchdog de Drupal, du téléchargement du PDF à la réponse de l'IA. Indispensable pour le débogage et la surveillance.
Logique de réessai : les échecs transitoires de l'API (limites de débit, délais d'attente) déclenchent un réessai automatique avec un délai exponentiel (2 s, 4 s, 8 s).
Échec gracieux : si le traitement échoue, le document reste modifiable avec des messages d'erreur clairs. Les éditeurs peuvent réessayer ou remplir les champs manuellement.
Tableau de bord de surveillance
Vue d'administration personnalisée à l'adresse /admin/content/ai-processing suit :
- Taux de réussite/d'échec
- Temps de traitement
- Coûts API
- Fréquence de correction des éditeurs (mesure de précision)
Examen hebdomadaire : l'équipe de BetterRegulation vérifie le tableau de bord chaque semaine afin de détecter rapidement les problèmes et d'affiner les invites en fonction des modèles d'erreurs.
Optimisation des performances et des coûts pour le traitement des documents par l'IA
Sans une optimisation adéquate, les coûts liés à l'API IA peuvent rapidement devenir incontrôlables. BetterRegulation a mis en œuvre plusieurs stratégies afin de minimiser les dépenses liées au traitement des documents tout en conservant les performances et l'expérience utilisateur.
Traitement en arrière-plan avec un délai de 15 minutes
Le problème : les éditeurs enregistrent souvent les documents plusieurs fois de suite pendant qu'ils les modifient. Le fait de déclencher la génération coûteuse de résumés par l'IA à chaque enregistrement entraîne un gaspillage d'argent.
Notre solution : génération de résumés mise en file d'attente dans RabbitMQ avec un délai de 15 minutes.
- L'éditeur enregistre le document → mise en file d'attente pour traitement dans 15 minutes
- Si l'éditeur enregistre à nouveau dans les 15 minutes → le délai est réinitialisé
- Après 15 minutes sans modification → les résumés sont générés une seule fois
Impact : élimine 60 à 70 % des appels API redondants lors des sessions d'édition rapide. Pour plus de stratégies visant à réduire les coûts liés à l'API IA, consultez comment le routage intelligent a permis de réduire les coûts liés à l'API IA de 95 %.
Comment la mise en cache réduit-elle les coûts de traitement des documents par l'IA ?
Texte PDF extrait mis en cache pendant 7 jours. Si l'invite doit être affinée, le retraitement utilise le texte mis en cache au lieu de le réextraire du PDF.
Économies : environ 0,05 £ par retraitement (appel Unstructured.io éliminé).
Lire aussi : Comment accélérer les réponses des chatbots IA grâce à la mise en cache intelligente →
Quels sont les coûts du traitement des documents par l'IA ?
Traitement mensuel (200 documents) :
- API GPT-4o-mini : environ 42 £/mois (environ 0,21 £ par document)
- Unstructured.io : 0 £ (auto-hébergé)
- Total : 42 £/mois
Économies réalisées grâce à l'optimisation par rapport à GPT-4 :
- GPT-4 coûterait : environ 420 £/mois
- Économies : 378 £/mois (réduction de 90 %)
Coût par temps gagné :
- 50 % de gain de temps = 50 heures/mois gagnées
- 42 £/mois ÷ 50 heures = 0,84 £ par heure gagnée
- Coût typique d'un éditeur : 15-25 £/heure
- ROI : retour sur investissement de 18 à 30 fois
Quelles considérations de sécurité devez-vous prendre en compte dans le traitement de documents par IA ?
Confidentialité des données : PDF envoyés à l'API OpenAI. Pour les documents sensibles, envisagez :
- LLM auto-hébergés (Llama, Mistral via Ollama)
- Accords de traitement des données avec OpenAI
- Anonymisation des textes (suppression des informations personnelles identifiables avant l'envoi)
Sécurité des clés API : stockées dans le système de configuration Drupal, et non dans le code. Accès réservé aux administrateurs.
Quels enseignements avons-nous tirés de la mise en œuvre du traitement de documents par IA ?
Après plusieurs mois de développement et d'utilisation en production, l'équipe de BetterRegulation a identifié sept enseignements essentiels qui pourraient être utiles à toute personne souhaitant mettre en place des intégrations IA similaires. Ces informations vont au-delà de la documentation technique et reflètent des connaissances pratiques acquises à grand-peine.
1. Testez avec des documents réels
À ne pas faire : tester avec des PDF synthétiques ou des exemples.
À faire : utiliser des documents réels issus de votre domaine.
Pourquoi : les documents de test synthétiques sont propres, bien formatés et prévisibles. Les documents réels sont désordonnés, incohérents et regorgent de cas limites qui perturberont vos invites soigneusement élaborées.
Ce que BetterRegulation a découvert lors des tests en conditions réelles :
- PDF numérisés avec une OCR de mauvaise qualité : les PDF contenaient du texte illisible, tel que « Cong umer Cred it Act », qui perturbait la correspondance taxonomique. Solution : ajout d'une normalisation du texte pour traiter les artefacts OCR.
- Documents multilingues : réglementations européennes mélangeant des termes juridiques anglais et latins. L'IA n'a initialement pas réussi à les classer correctement jusqu'à ce que les invites soient ajustées pour traiter le contenu multilingue.
- Noms incohérents : la même organisation est référencée sous les noms « FCA », « Financial Conduct Authority », « the Authority » et « the FCA » dans un même document. La correspondance sémantique a permis de résoudre ce problème, mais une validation était nécessaire.
- Monstres de plus de 350 pages : le problème de limite de jetons n'a été découvert que lors des tests avec des recueils réglementaires réels. Cela a conduit à la stratégie de secours d'extraction des titres.
BetterRegulation a été testé avec de véritables PDF juridiques couvrant plus de 5 ans de publications avant son lancement. Les 20 premiers documents testés ont révélé plus de problèmes que 6 mois de développement avec des échantillons synthétiques.
2. L'intervention humaine est essentielle
À ne pas faire : automatiser entièrement sans révision.
À faire : l'IA remplit les champs, les humains vérifient et approuvent.
Pourquoi : aucun système d'IA n'est parfait, et les erreurs dans une plateforme de conformité juridique ont des conséquences réelles. Plus important encore, les erreurs de l'IA ne sont pas aléatoires : elles ont tendance à se concentrer autour des documents les plus complexes, ambigus ou inhabituels qui nécessitent la plus grande attention.
L'approche humaine offre de multiples avantages :
- Assurance qualité : les rédacteurs juridiques détectent les erreurs de l'IA avant qu'elles n'affectent les utilisateurs finaux. Dans une plateforme de conformité, une catégorisation incorrecte peut empêcher de trouver des directives réglementaires essentielles au moment où elles sont nécessaires.
- Renforcement de la confiance : les rédacteurs font confiance au système car ils voient comment il fonctionne et peuvent le corriger. Positionner l'IA comme un « assistant » plutôt que comme un remplacement réduit la résistance organisationnelle et augmente l'adoption.
- Amélioration continue : les corrections des rédacteurs révèlent des schémas dans le comportement de l'IA. En suivant les champs les plus fréquemment corrigés, vous pouvez identifier les invites qui doivent être affinées ou les taxonomies qui doivent être clarifiées.
- Capture de l'expertise du domaine : lorsque les éditeurs apportent des corrections, ils appliquent souvent des connaissances nuancées du domaine qui n'étaient pas capturées dans les invites d'origine. Ces corrections peuvent être analysées afin d'améliorer le système au fil du temps.
- Équilibre en matière d'efficacité : l'IA se charge du travail fastidieux et répétitif qui consiste à lire des documents et à extraire des métadonnées de base. Les humains se concentrent sur la révision, l'ajustement des cas limites et l'application de leur jugement dans les situations ambiguës. Cette division du travail est plus efficace que l'une ou l'autre de ces approches prises séparément.
Résultat : un gain de temps considérable tout en maintenant les normes de qualité. Les éditeurs travaillent plus rapidement car l'IA effectue le travail initial fastidieux, et le résultat final est plus cohérent car l'IA ne se fatigue pas et ne commet pas d'erreurs de transcription.
3. Itérer sur les invites
À ne pas faire : rédiger une invite une seule fois et passer à autre chose.
À faire : examiner les erreurs et affiner les invites.
Pourquoi : votre première invite sera bonne, mais pas excellente. Le comportement de l'IA est émergent et souvent surprenant : vous ne pourrez pas prédire tous les modes de défaillance tant que vous n'aurez pas traité des centaines de documents réels.
La leçon : l'amélioration est venue de l'analyse des erreurs réelles, et non de la théorisation des améliorations. Suivez les corrections, trouvez des modèles, affinez les invites.
4. Les cas limites sont inévitables
À ne pas faire : supposer que l'IA s'occupera de tout.
À faire : prévoir les cas limites à l'avance et mettre en place des solutions de secours élégantes.
Pourquoi : quelle que soit la qualité de votre IA, certains documents perturberont le système. La question n'est pas « si », mais « quand » et « à quelle fréquence ».
Catalogue des cas limites de BetterRegulation :
- Dépassement de la limite de jetons : très grands recueils réglementaires qui dépassent la fenêtre contextuelle de 128 Ko de GPT-4o-mini. Solution de secours : extraire et traiter uniquement les titres et les en-têtes de section — précision moindre, mais mieux qu'un échec complet.
- Catastrophes liées aux PDF numérisés : anciennes législations numérisées avec un OCR de mauvaise qualité produisant un texte illisible. Solution de secours : champ d'administration pour télécharger une version condensée saisie manuellement ou signaler pour traitement humain.
- Documents véritablement ambigus : certains documents couvrent légitimement plusieurs catégories et même les experts juridiques ne s'accordent pas sur leur catégorisation appropriée. Solution de secours : l'IA renvoie plusieurs options ; l'éditeur prend la décision finale.
- Métadonnées manquantes : certains PDF ne contiennent tout simplement pas les informations attendues telles que l'année, l'URL source ou d'autres champs. Solution de secours : renvoyer des valeurs vides plutôt que des valeurs fantaisistes ; l'éditeur les remplit manuellement.
L'approche pragmatique : accepter que certains documents nécessitent un traitement spécial. Mettre en place un système de surveillance pour identifier rapidement ces cas et fournir aux éditeurs des workflows clairs pour les traiter. Tenter d'atteindre une automatisation à 100 % coûterait beaucoup plus de temps de développement pour des gains marginaux.
5. La surveillance est essentielle
À ne pas faire : déployer et oublier.
À faire : mettre en place une surveillance complète dès le premier jour.
Pourquoi : les systèmes d'IA peuvent se dégrader silencieusement. Les mises à jour des modèles, les changements de taxonomie ou l'évolution des formats de documents peuvent perturber des processus qui fonctionnaient auparavant. Sans surveillance, vous ne vous en rendrez compte que lorsque les utilisateurs se plaindront.
L'approche de surveillance de BetterRegulation suit :
- Taux de réussite/d'échec : mesures globales de la réussite du traitement. Des baisses soudaines indiquent des problèmes système.
- Répartition du temps de traitement : suivi des performances au fil du temps. Des augmentations significatives indiquent des ralentissements de l'API ou des problèmes de limite de jetons.
- Précision par champ : surveillez les champs que les éditeurs corrigent le plus fréquemment. Cela révèle les domaines dans lesquels les invites doivent être améliorées.
- Tendances des coûts des API : suivez les modèles de dépenses. Les pics indiquent des problèmes tels que le traitement en double, une logique de délai défaillante ou des augmentations de volume inattendues.
- Modèles d'erreurs : classez les échecs par type. Chaque modèle fait l'objet de stratégies de correction spécifiques.
Valeur de la détection précoce : la surveillance fournit une alerte précoce lorsque des services externes modifient leur comportement ou lorsque les modèles de traitement des documents changent, ce qui permet une adaptation rapide avant que les utilisateurs ne soient affectés.
6. L'optimisation des coûts est importante
À ne pas faire : opter par défaut pour le modèle d'IA le plus cher.
À faire : tester d'abord les modèles moins chers ; optimiser en fonction des coûts réels.
Pourquoi : « utiliser la meilleure IA » semble judicieux, mais cela revient à gaspiller de l'argent. Pour de nombreuses tâches, les modèles moins chers sont tout aussi performants. Le processus d'optimisation des coûts de BetterRegulation a permis de réaliser des économies substantielles par rapport à l'approche naïve consistant à utiliser des modèles haut de gamme pour tout.
Décision 1 : GPT-4o-mini vs GPT-4
- Hypothèse initiale : « GPT-4 est meilleur, donc utilisez GPT-4. »
- Constat : les deux modèles ont été testés sur 50 documents. GPT-4 : précision de 96 %. GPT-4o-mini : précision de 95 %.
- Analyse des coûts : GPT-4 : 1,05 £ par document. GPT-4o-mini : 0,21 £ par document.
- Décision : un gain de précision de 1 % ne justifie pas une augmentation de coût multipliée par 5. Choix du GPT-4o-mini.
- Économies annuelles : 2 016 £ (200 documents/mois × 12 mois × 0,84 £ d'économies par document)
Décision 2 : Unstructured.io auto-hébergé
- Option SaaS : 0,10 à 0,20 £ par traitement de document
- Option auto-hébergée : fonctionne sur le cluster Kubernetes existant, pratiquement gratuit (coût informatique marginal ~5 £/mois)
- Décision : auto-hébergement sur l'infrastructure existante
- Économies annuelles : 240 à 480 £ (200 documents/mois × 12 mois × 0,10 à 0,20 £)
7. Commencez simplement, ajoutez de la complexité
À ne pas faire : essayer de construire une vision complète dès le premier jour.
À faire : lancer avec une IA minimale viable, itérer en fonction de l'utilisation réelle.
Pourquoi : vous ne savez pas ce qui fonctionnera tant que les utilisateurs réels n'auront pas interagi avec les données réelles. Commencer par quelque chose de complexe signifie un développement plus long, plus de bugs et des efforts gaspillés sur des fonctionnalités dont les utilisateurs n'ont peut-être pas besoin.
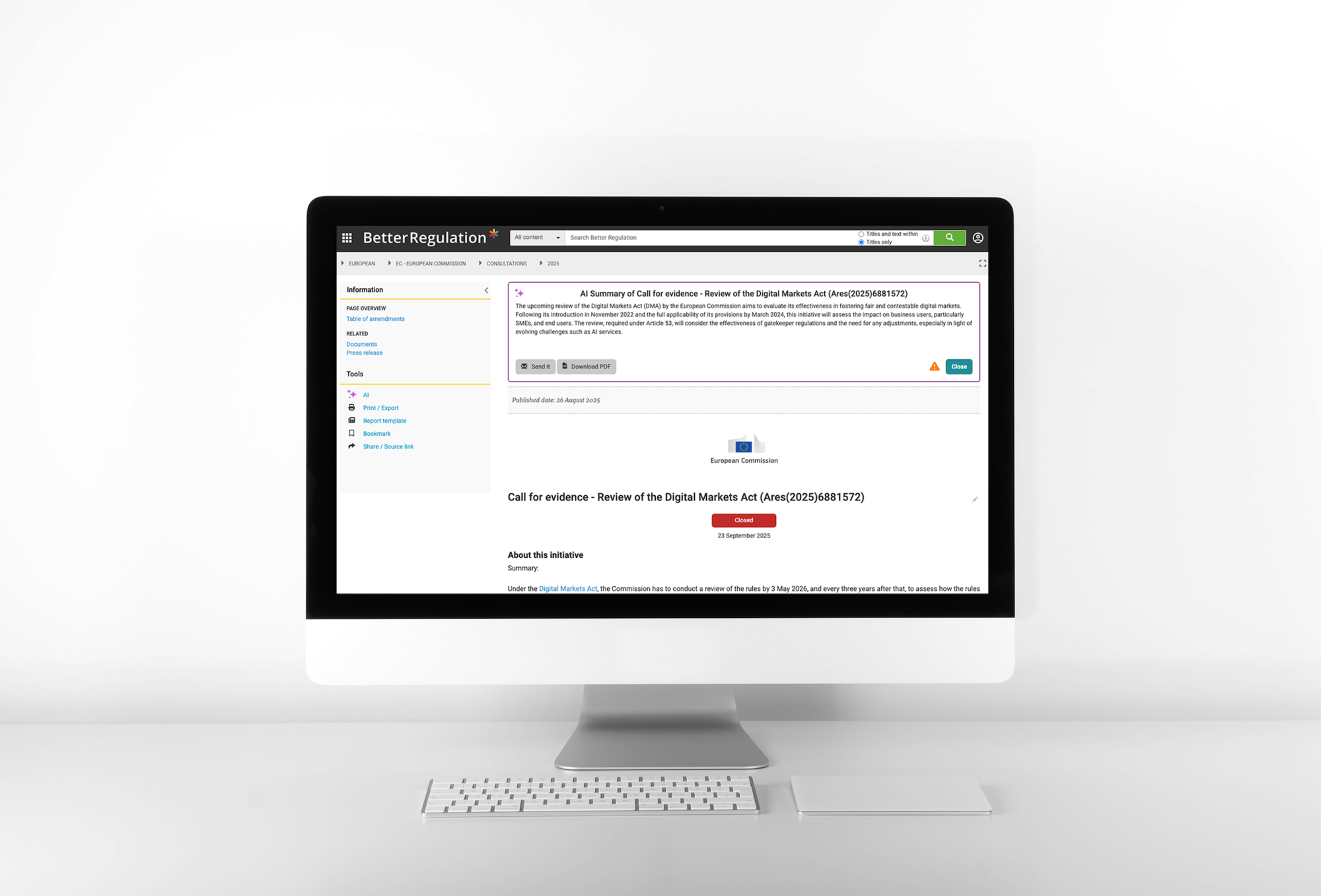
Exemple d'un projet dans lequel nous avons utilisé l'IA et Drupal pour mettre en œuvre des résumés automatisés de documents juridiques complexes
Lire l'étude de cas complète sur les résumés de documents générés par l'IA ici →
De quels outils et ressources avez-vous besoin pour le traitement de documents par IA ?
Prêt à mettre en œuvre le traitement de documents par IA dans votre projet Drupal ? Voici les modules, services et ressources essentiels dont vous aurez besoin pour démarrer.
Modules Drupal
Obligatoires :
- Module IA - cadre d'intégration IA de base pour Drupal
- AI Automators - sous-module fournissant un moteur de workflow pour les processus IA en plusieurs étapes
Utiles :
- Queue UI - gestion des files d'attente en arrière-plan
- Module Unstructured - intégration Drupal pour Unstructured.io
Services externes
API IA :
- API OpenAI - modèles GPT (recommandé : GPT-4o-mini)
- Anthropic Claude - autre fournisseur LLM
Traitement des PDF :
- Unstructured.io - meilleure extraction de PDF (auto-hébergé ou SaaS)
- Unstructured GitHub - open source
Infrastructure
Docker/Kubernetes :
- Docker Compose - développement local
- Kubernetes - déploiement en production
Files d'attente de messages :
- RabbitMQ - file d'attente de messages fiable
- Drupal Queue API - files d'attente intégrées
Prêt à mettre en œuvre le traitement de documents par IA dans Drupal ?
Cette étude de cas est basée sur notre implémentation réelle pour BetterRegulation, où nous avons intégré AI Automators, Unstructured.io et GPT-4o-mini afin d'automatiser le traitement de plus de 200 documents juridiques par mois avec une précision supérieure à 95 % et un gain de temps de 50 %. Le système fonctionne en production depuis des mois, offrant des résultats constants et un retour sur investissement.
Vous souhaitez mettre en place un traitement de documents par IA pour votre site Drupal ? Notre équipe est spécialisée dans la création de solutions de traitement de documents par IA de qualité production qui allient précision, performance et rentabilité. Nous nous occupons de tout, de la conception de l'architecture et de l'ingénierie rapide au déploiement et à l'optimisation. Consultez nos services de développement d'IA générative pour découvrir comment nous pouvons vous aider à automatiser le traitement des documents et libérer votre équipe éditoriale afin qu'elle puisse se concentrer sur des tâches stratégiques.










