
Comment nous avons amélioré la précision du Chatbot RAG de 40% grâce à l'évaluation de documents

Votre chatbot IA peut répondre rapidement, mais ses réponses sont-elles correctes ? De nombreuses organisations qui mettent en œuvre des chatbots RAG (Génération Augmentée par Récupération) découvrent une vérité frustrante : la similarité sémantique ne signifie pas pertinence. Par exemple, un utilisateur peut poser une question sur la "mise en œuvre de l'architecture de sécurité à confiance zéro dans les environnements cloud hybrides", et le système renvoie en toute confiance des articles sur la "sécurité du cloud", mais ils discutent des règles de pare-feu de base au lieu des principes de confiance zéro.
Nous avons été confrontés à ce défi exact en construisant un chatbot RAG pour une plateforme de gestion des connaissances professionnelles. Leur vaste bibliothèque d'articles, d'études de cas et de documentation technique nécessitait une précision - les utilisateurs avaient besoin de réponses précises avec des informations contextuelles, et non pas simplement de contenu sémantiquement similaire. En mettant en œuvre une approche de notation documentaire en deux étapes, nous avons considérablement amélioré la précision des réponses tout en maintenant des performances et des coûts raisonnables.
Dans cet article, je vais vous guider à travers le problème de la récupération RAG naïve, expliquer notre solution de notation en deux étapes, partager des détails d'implémentation réels, et vous aider à décider quand cette approche a du sens pour votre chatbot.
Dans cet article :
- Le problème avec la récupération RAG naïve
- Solution de notation de document en deux étapes
- Comment mettre en œuvre la notation documentaire ? Exemples de code
- Comment la notation documentaire affecte-t-elle les performances du chatbot ?
- Quels sont les résultats et l'impact commercial de la notation de documents ?
- Quand la notation documentaire a du sens
- Commencer avec la notation de documents
- Une précision RAG supérieure grâce à la notation documentaire
- Vous voulez construire des chatbots RAG de qualité production ?
Le problème avec la récupération RAG naïve
La plupart des systèmes RAG suivent un schéma simple : convertir les questions des utilisateurs en incorporations, rechercher dans une base de données de vecteurs des fragments de documents similaires, et nourrir les résultats les plus pertinents à un MLM (ang. Modèle de Langue Large) pour générer des réponses. Cette méthode fonctionne remarquablement bien pour de nombreux cas d'utilisation, mais elle présente une limitation fondamentale : la similarité vectorielle mesure la proximité des mots et des concepts dans l'espace sémantique, et non pas si un document répond réellement à une question spécifique.
Comment fonctionne la recherche vectorielle standard
Lorsque vous effectuez une recherche vectorielle, le système calcule la similarité cosinus (ou une autre mesure de distance) entre votre incorporation de requête et les incorporations de documents stockées dans les bases de données vectorielles. Les documents dont les scores de similarité sont les plus élevés sont mis en évidence. Par exemple, une requête sur les "exigences de conformité au GDPR pour le traitement des données API dans les intégrations tierces" pourrait retourner :
- Des articles généraux sur la conformité au GDPR (fort chevauchement de mots clés)
- Des guides de documentation API (similitude sémantique)
- Des études de cas sur la protection des données (mentionne la "conformité")
- Des entrées de glossaire définissant les termes du GDPR (correspondances de mots clés)
Tous ces documents contiennent des mots clés et des concepts pertinents. Les incorporations reconnaissent les relations sémantiques.
Le coût de la faible précision
Lorsque les chatbots basés sur RAG renvoient des réponses plausibles mais erronées, les conséquences s'accumulent :
- La confiance s'effrite : les utilisateurs apprennent rapidement que le système "ne comprend pas vraiment" leurs questions.
- Augmentation de la charge de support : au lieu de réduire les questions répétitives, vous ajoutez "Comment obtenir de meilleures réponses ?" à la file d'attente du support.
- Investissement dans la mise en place gaspillé : un système que les utilisateurs évitent ne produit pas de retour sur investissement.
- Atteinte à la réputation : sur les plateformes de connaissances professionnelles, la précision a un impact direct sur la crédibilité de la marque et la rétention des utilisateurs.
Nous avions besoin d'une solution qui pourrait distinguer entre "ces documents contiennent des mots similaires" et "ces documents répondent réellement à cette question"
Solution de notation de documents en deux étapes
Notre solution met en œuvre un processus de récupération en deux étapes qui sépare la découverte large de la sélection précise. Au lieu d'accepter aveuglément les résultats de recherche vectorielle, nous introduisons une étape de notation alimentée par le MLM qui évalue chaque candidat pour sa pertinence réelle.
Étape 1 : Récupération large
La première étape jette un large filet, en récupérant environ 20 fragments de documents candidats de notre base de données vectorielle Elasticsearch. Pourquoi 20 ? Ce nombre équilibre deux besoins concurrents :
- Rappel : nous avons besoin de suffisamment de candidats pour garantir que les documents pertinents sont pris en compte. Si nous ne récupérons que 5 morceaux et que la réponse parfaite est le #6, nous ne la trouverons jamais.
- Effcicacité du traitement : la notation des documents consomme des jetons LLM et ajoute de la latence. Évaluer 100 candidats serait inutilement coûteux.
À cette étape, nous utilisons toujours la recherche de similarité vectorielle standard. La requête est incorporée en utilisant le modèle text-embedding-3-small de OpenAI, et nous effectuons une recherche de similarité cosinus avec une Pertinence Marginale Maximale (MMR) pour réduire la redondance dans les résultats initiaux.
Chaque fragment récupéré comprend des méta-données riches que nous avons capturées lors de l'indexation :
{
"node_id": "12345",
"title": "Guide de mise en œuvre de l'architecture à confiance zéro",
"url": "/articles/securite-a-confiance-zero",
"tags": ["Sécurité", "Cloud", "Architecture"],
"authors": ["Jane Doe"],
"channels": ["Sécurité entreprise"],
"published_at": "2024-03-15",
"type": "article",
"subtype": "guide_technique",
"section_title": "Stratégies de segmentation du réseau",
"chunk_index": 3,
"tokens": 450,
"language": "fr"
}
Ces méta-données deviennent cruciales à l'étape suivante.
Étape 2 : Notation alimentée par le LLM
C'est là que la magie opère. Nous prenons ces 20 fragments de documents candidats et posons à GPT-4 une question d'une simplicité trompeuse pour chacun d'eux : "Est-ce que ce texte répond réellement à la question de l'utilisateur ?"
Le critère de notation comprend :
- L'entrée utilisateur originale (une question avec contexte complet)
- Le texte du fragment candidat
- Les métadonnées du fragment (aident le LLM à comprendre le contexte)
- Des critères de notation clairs :
- Est-ce qu'il aborde directement le sujet de la question ?
- Fournit-il des informations substantielles (pas seulement des définitions) ?
- Le contexte est-il approprié pour la requête ?
- Est-ce suffisamment complet pour être utile ?
The Modèle de Langue Large retourne une note de pertinence (nous utilisons une échelle, mais un oui/non binaire fonctionne aussi). De manière cruciale, le LLM peut reconnaître qu'un article sur la "sécurité du cloud en général" peut obtenir un score élevé en termes de similarité de signification sémantique mais un score faible en termes de pertinence pour une requête sur "l'architecture à confiance zéro".
Après avoir noté tous les 20 candidats, nous trions par score de pertinence et sélectionnons les 12 premiers pour la génération de la réponse finale. Pourquoi 12 ? À travers les tests, nous avons trouvé que ce nombre fournissait assez de contexte pour des réponses complètes sans submerger la fenêtre de contexte de génération ou diluer la qualité avec du contenu marginalement pertinent.
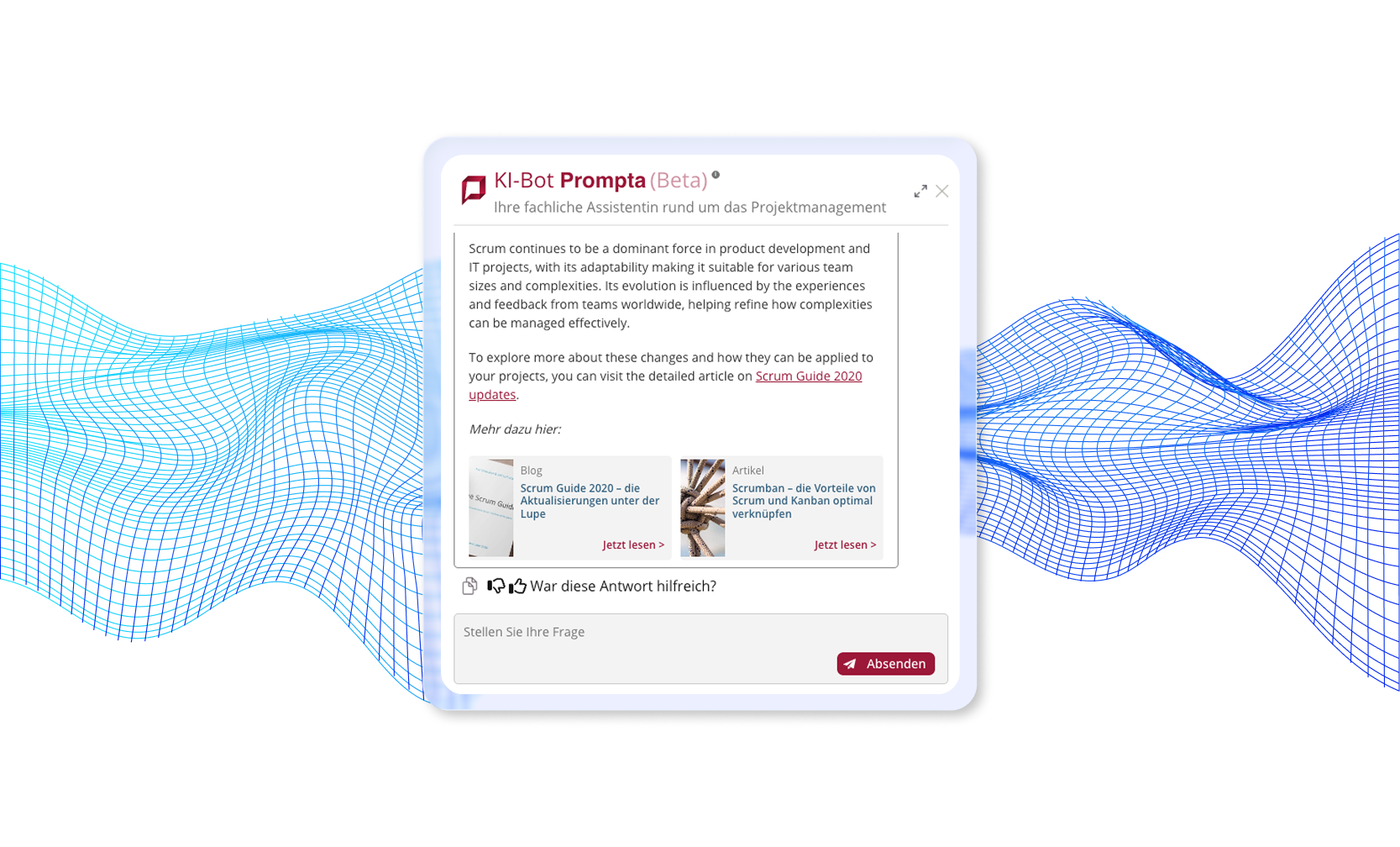
Exemple d'un chatbot que nous avons mis en œuvre qui utilise la notation de document en deux étapes
Lisez notre étude de cas complète : Chatbot de Document AI →
Pourquoi une notation de document en deux étapes fonctionne-t-elle ?
L'approche en deux étapes exploite les forces complémentaires des incorporations et des LLM :
- Les incorporations sont excellentes pour une recherche sémantique large à travers des milliers de documents en millisecondes.
- Les LLM sont excellents pour la compréhension nuancée du contexte, de l'intention et de la pertinence.
En les combinant, nous obtenons la vitesse et l'évolutivité de la recherche vectorielle avec la précision de la compréhension du langage. Le LLM peut faire des distinctions subtiles que les incorporations manquent :
- "Cela discute de l'architecture de sécurité, mais pour les déploiements sur place, pas pour les environnements cloud".
- "Cela définit le concept mais ne fournit pas de détails d'implémentation".
- "C'est à propos de la même technologie mais pour un cas d'utilisation différent".
- "Cela mentionne le mot clé mais c'est une référence tangentielle, pas le sujet principal".
Comment mettre en œuvre l'évaluation des documents ? Exemples de code
Examinons comment mettre en pratique l'évaluation des documents. Alors que notre système de production utilise LangChain et LangGraph pour l'orchestration, les concepts de base s'appliquent à n'importe quel cadre RAG.
Mise en œuvre conceptuelle
Voici une version simplifiée de la logique d'évaluation :
from langchain.vectorstores import ElasticsearchStore
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# Configuration
BROAD_RETRIEVAL_K = 20 # Candidats à récupérer
FINAL_SELECTION_K = 12 # Morceaux à utiliser pour la génération
# Initialisation des composants
vector_store = ElasticsearchStore(
index_name="embeddings_index_v2",
embedding=OpenAIEmbeddings(model="text-embedding-3-small")
)
grading_llm = ChatOpenAI(model="gpt-4o", temperature=0)
def retrieve_and_grade(query: str) -> list[Document]:
"""
Récupération en deux étapes avec évaluation des documents
"""
# Étape 1: Récupération large
candidates = vector_store.similarity_search(
query=query,
k=BROAD_RETRIEVAL_K,
search_type="mmr" # Réduire la redondance
)
print(f"Récupéré {len(candidates)} candidats")
# Étape 2: Évaluer chaque candidat
graded_docs = []
for doc in candidates:
grade = grade_document(query, doc)
graded_docs.append({
"document": doc,
"score_de_pertinence": grade["score"],
"raisonnement": grade["reasoning"]
})
# Trier par score de pertinence
graded_docs.sort(key=lambda x: x["score_de_pertinence"], reverse=True)
# Sélectionner le top K pour la génération
final_docs = [item["document"] for item in graded_docs[:FINAL_SELECTION_K]]
print(f"Sélectionné {len(final_docs)} documents hautement pertinents")
return final_docs
def grade_document(query: str, document: Document) -> dict:
"""
Évaluation de la pertinence du document à l'aide de LLM
"""
grading_prompt = ChatPromptTemplate.from_messages([
("system", """Vous êtes un expert en évaluation de la pertinence des documents.
Étant donné une question d'utilisateur et un morceau de document, déterminez si le document
répond réellement à la question. Considérez:
1. Correspondance des sujets: cela aborde-t-il le sujet spécifique demandé ?
2. Pertinence du contexte: est-ce pertinent à la situation de l'utilisateur ?
3. Complétude: fournit-il des informations substantielles ?
4. Directité: cela répond-il directement, ou mentionne uniquement des mots-clés ?
Répondez avec :
- score : 0,0 à 1,0 (1,0 = très pertinent)
- raisonnement : brève explication de votre évaluation
"""),
("human", """Question: {query}
Contenu du document :
{content}
Métadonnées du document :
- Titre: {title}
- Type: {doc_type}
- Tags: {tags}
Évaluez la pertinence de ce document.""")
])
response = grading_llm(grading_prompt.format_messages(
query=query,
content=document.page_content,
title=document.metadata.get("title", "N/A"),
doc_type=document.metadata.get("type", "N/A"),
tags=", ".join(document.metadata.get("tags", []))
))
# Analyser la réponse LLM (implémenter une sortie structurée en production)
return {
"score": parse_score(response),
"raisonnement": parse_reasoning(response)
}
Intégration avec LangGraph
Dans notre système de production, l'évaluation s'intègre dans une machine à états LangGraph :
from langgraph.graph import Graph, StateGraph
# Définition du flux de travail
workflow = StateGraph()
# Nœuds dans le flux de travail
workflow.add_node("classify_question", classify_question)
workflow.add_node("generate_search_phrase", generate_search_phrase)
workflow.add_node("retrieve", retrieve_documents) # Récupère environ 20
workflow.add_node("grade_documents", grade_all_documents) # Évalue et sélectionne les 12 meilleurs
workflow.add_node("generate", generate_answer)
# Les arêtes définissent le flux
workflow.add_edge("classify_question", "generate_search_phrase")
workflow.add_edge("generate_search_phrase", "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
# Compiler et exécuter
app = workflow.compile()
result = app.invoke({"query": user_question})
Le nœud grade_documents reçoit la liste de candidats de retrieve et renvoie la sélection filtrée et classée pour generate.
Comment l'évaluation des documents affecte-t-elle les performances du chatbot ?
La mise en œuvre de l'évaluation des documents dans votre chatbot introduit des compromis de performance, mais avec des stratégies d'optimisation intelligentes, vous pouvez minimiser l'impact tout en maximisant les gains de précision.
Comprendre le compromis de latence
Ajouter l'évaluation des documents à votre pipeline RAG introduit un temps de traitement supplémentaire. Dans notre déploiement en production, l'évaluation de 20 candidats de documents ajoute environ 2 à 5 secondes au temps de réponse total de la requête. Cela se produit parce que chaque document nécessite un appel LLM individuel pour évaluer sa pertinence.
Cependant, cette latence peut être considérablement réduite par le traitement parallèle. Au lieu d'évaluer les documents séquentiellement, vous pouvez évaluer plusieurs candidats simultanément en utilisant des opérations asynchrones ou des threads. En pratique, nous avons constaté que les utilisateurs des systèmes de base de connaissances acceptent volontiers ce temps d'attente quand il en résulte une amélioration significative de la qualité des réponses. Les quelques secondes supplémentaires semblent valoir la peine lorsque l'alternative est de recevoir des informations non pertinentes qui nécessitent une reformulation de la requête et un nouvel essai.
Lisez aussi : Comment accélérer les réponses du Chatbot IA avec la mise en cache intelligente →
Décrypter l'économie de l'évaluation des documents
Comprendre l'économie de l'évaluation des documents vous aide à prendre des décisions éclairées sur la mise en œuvre. Chaque opération d'évaluation consomme environ 150 à 300 tokens, en fonction de la longueur du document et des métadonnées incluses dans l'invite d'évaluation. Avec 20 candidats à évaluer par requête utilisateur, c'est environ 5 000 tokens par requête (en utilisant une moyenne de 250 tokens par note).
Stratégies d'optimisation pour la production
Plusieurs stratégies d'optimisation peuvent vous aider à équilibrer le coût, la vitesse et la qualité.
Cachez les évaluations fréquentes
La mise en cache des notes pour les paires de questions-documents courantes élimine les évaluations redondantes. Si vous récupérez des données pour la même combinaison question-document fréquemment, stockez la note et réutilisez-la. Cela peut réduire considérablement les coûts pour les bases de connaissances à fort trafic avec des requêtes récurrentes.
Utilisez un modèle plus petit ou plus rapide
Vous pouvez également envisager d'utiliser un modèle plus petit ou plus rapide pour les opérations d'évaluation. Bien que nous ayons utilisé GPT-4o pour une précision maximale, GPT-3.5-turbo ou un modèle spécialisé et affiné pourrait gérer l'évaluation à une fraction du coût, surtout si votre domaine est bien défini.
Réduisez le nombre de candidats
Une autre approche consiste à réduire le nombre de candidats que vous évaluez. Si le budget est serré, évaluez seulement les 10 premiers documents au lieu de 20, en acceptant une réduction légère du rappel pour des coûts plus bas.
Mettez en place une terminaison anticipée
Enfin, mettez en place une logique de terminaison anticipée: si les cinq premiers documents obtiennent tous un score très élevé pour la pertinence, vous pourriez sauter l'évaluation des quinze candidats restants. Cette interruption intelligente permet d'économiser des tokens tout en maintenant la qualité pour les requêtes ayant des correspondances évidentes de haute qualité.
Quels sont les résultats et l'impact commercial de l'évaluation des documents ?
La mise en œuvre de l'évaluation des documents a transformé la qualité des réponses dans notre système RAG de production. Bien que nous utilisions "40%" dans le titre de l'article comme chiffre illustratif, les améliorations qualitatives étaient spectaculaires et mesurables grâce aux commentaires des utilisateurs et aux mesures du système.
Améliorations de la précision
L'évaluation des documents a transformé la qualité des réponses de notre chatbot de façon que les gens ont immédiatement remarquée et appréciée.
Avant l'évaluation :
- Les utilisateurs signalaient fréquemment des réponses qui étaient "proches mais pas tout à fait correctes".
- Plainte courante: "Cela parle du sujet mais ne répond pas à ma question spécifique".
- Les tickets de support comprenaient "Comment obtenir de meilleures réponses de la part du chatbot?"
Après l'évaluation :
- Les commentaires des utilisateurs se sont orientés vers "C'est exactement ce que je cherchais."
- Le nombre de tickets de support pour les questions d'utilisation du chatbot RAG a diminué.
- Les scores de satisfaction du système se sont nettement améliorés.
- Les utilisateurs ont commencé à faire confiance au chatbot et à compter sur lui pour leur travail quotidien.
Validation en conditions réelles
Les commentaires post-déploiement ont validé notre approche :
- Satisfaction des parties prenantes : la direction a signalé que le système dépassait les attentes en termes de fonctionnalité et de fiabilité.
- Réussite opérationnelle : les prochaines priorités se sont orientées vers des améliorations de l'interface utilisateur plutôt que des corrections de fonctionnalités de base, un signe clair que la qualité des réponses répondait aux besoins.
- Adoption par les utilisateurs : le nombre d'utilisateurs actifs a régulièrement augmenté à mesure que la confiance dans le système grandissait.
- Réductions d'escalades : l'assistance technique a pu se concentrer sur les véritables problèmes des utilisateurs plutôt que sur les problèmes de précision du système.
Quand l'évaluation des documents a du sens
L'évaluation des documents n'est pas nécessaire pour chaque chatbot RAG. Quand devriez-vous l'envisager ?
Cas d'utilisation idéaux
Voici quelques exemples de cas d'utilisation idéaux :
- Grandes bases de connaissances diverses (1 000+ documents) : quand votre corpus est vaste et couvre de nombreux sujets, la récupération naïve peine à distinguer les nuances. L'évaluation devient de plus en plus précieuse à mesure que la base de connaissances se développe.
- Domaines techniques ou spécialisés : informations médicales, documents juridiques, documentation technique, modèles d'architecture d'entreprise, fichiers texte – domaines où la précision compte et où une information erronée a des conséquences réelles.
- Utilisateurs professionnels ou d'entreprise : les spécialistes qui prennent des décisions commerciales ont besoin de confiance dans les réponses. Que ce soient des architectes qui choisissent des piles technologiques, des responsables de la conformité qui interprètent des réglementations, ou des développeurs qui mettent en œuvre des modèles de sécurité - se tromper pourrait avoir un impact sur les opérations commerciales critiques.
- Priorisation de la qualité sur la vitesse : si les utilisateurs préfèrent attendre 5 secondes pour obtenir une excellente réponse des messages de chat plutôt que d'obtenir une réponse médiocre en 2 secondes, l'évaluation a du sens.
- Questions à hauts enjeux : support client, conseils de conformité, conseils médicaux, informations financières – scénarios où la précision n'est pas négociable.
Quand une récupération plus simple pourrait suffire
Voyez les cas où il vaut mieux opter pour une récupération plus simple :
- Petites collections de documents (<100 documents) : avec moins de documents, la récupération naïve fonctionne souvent suffisamment bien. Les gains de précision ne justifient pas la complexité.
- Requêtes de connaissances générales : pour des questions larges et non techniques, la similarité sémantique corrèle généralement bien avec la pertinence. Un simple chatbot RAG FAQ n'a peut-être pas besoin d'évaluation.
- Exigences strictes de latence : applications de chat ou de voix en temps réel où chaque milliseconde compte peuvent devoir sauter l'évaluation ou utiliser des approximations très rapides.
- Contraintes budgétaires : si le coût par requête doit rester en dessous de 0,01 $ au total, l'évaluation pourrait dépasser votre budget. Envisagez-le lors de la montée en charge ou lorsque le parrainage existe.
- Systèmes expérimentaux ou prototypes : faites d'abord fonctionner le RAG de base, ajoutez l'évaluation si la récupération naïve s'avère insuffisante. N'optimisez pas prématurément.
Commencer avec la notation de documents
Prêt à implémenter la notation de documents dans votre chatbot RAG? Voici une feuille de route pratique :
Étape 1 : Mesurer les performances actuelles
Avant d'ajouter la notation, établissons des bases :
- Revoyez manuellement 50-100 paires de questions-réponses.
- Notez où les réponses sont hors cible malgré une similarité sémantique.
- Calculez un score de pertinence approximatif (combien de réponses ont réellement répondu à la question).
- Prenez note des erreurs courantes dans les documents.
Cette base prouve si la notation aide et dans quelle mesure.
Étape 2 : Commencez par une notation simple
Ne compliquez pas les choses au départ :
# Prompt de notation binaire simple
prompt = """Ce document répond-il à la question : {query}?
Document: {content}
Répondez seulement : OUI ou NON"""
# Récupérer les candidats
candidates = vectorstore.similarity_search(query, k=20)
# Noter chacun
relevant = []
for doc in candidates:
response = llm(prompt.format(query=query, content=doc.content))
if "OUI" in response:
relevant.append(doc)
# Utiliser les documents pertinents pour générer
answer = generate(query, relevant[:12])
Étape 3 : Itération et amélioration
Améliorez la notation en fonction des résultats :
- Ajouter une sortie structurée : utilisez le mode JSON ou l'appel de fonction pour des réponses cohérentes.
- Inclure des métadonnées : aider le LLM à comprendre le contexte du document.
- Ajuster le seuil de sélection : peut-être que vous avez besoin du top 15, pas du top 12.
- Optimiser pour la vitesse : notation parallèle, modèles plus rapides pour certaines requêtes.
- Surveiller les coûts : suivez les dépenses de notation versus les gains de qualité.
Étape 4 : Effectuer des tests A/B
Effectuez la notation en parallèle avec la récupération naïve :
- Dirigez 50% des requêtes à travers chaque chemin.
- Comparez les commentaires des utilisateurs, l'engagement, la satisfaction.
- Mesurez les différences de coût.
- Décidez sur la base des données, pas des suppositions.
Lisez aussi : LangChain vs LangGraph vs Raw OpenAI: Comment choisir votre pile RAG →
Conseils pour la notation des documents en production
Apprenez quelques conseils utiles pour la mise en œuvre en production :
- Utiliser intelligemment le cache : si la même question est posée fréquemment, mettez le résultat noté en cache. Pas besoin de noter à nouveau les requêtes identiques.
- Échouer gracieusement : si la notation échoue (délai d'expiration de l'API, etc.), retombez sur le top-K naïf. Certaines réponses sont meilleures que pas de réponse.
- Surveiller la qualité : suivez quels documents sont constamment notés haut ou bas. Les documents populaires à faible notation pourraient avoir besoin de contenu amélioré.
- Optimisez pour votre domaine : nos critères fonctionnent pour la gestion des connaissances professionnelles. Ajustez les messages de notation pour votre cas d'utilisation spécifique et les types de contenu.
- Envisager les niveaux de coût : proposez un "mode rapide" (sans notation) et un "mode précis" (avec notation) pour laisser les utilisateurs choisir leur compromis.
Une plus grande précision de RAG avec la notation de documents - conclusion
La notation de documents comble le fossé entre la similarité sémantique et la pertinence réelle dans les systèmes RAG. En introduisant une seconde étape où un LLM évalue si les candidats répondent vraiment à la question, nous avons considérablement amélioré la qualité des réponses dans notre déploiement en production tout en gardant les coûts raisonnables.
L'approche est conceptuellement simple : récupérer largement, noter précisément, générer une réponse pertinente à partir du meilleur. Mais l'impact est important - transformer un système qui retourne des réponses plausibles mais fausses en un système que les utilisateurs font confiance pour prendre des décisions professionnelles.
Vaut-il la peine de dépenser 0,01$ de plus et 3 secondes par requête utilisateur ? Pour la gestion des connaissances, les services professionnels, la documentation technique, et d'autres applications à enjeux élevés, absolument. Le coût de l'information erronée dépasse de loin le coût de la notation.
Si vous construisez un seul chatbot RAG et constatez que les utilisateurs se plaignent de la qualité des réponses malgré une bonne récupération, la notation de documents pourrait être votre solution. Commencez simplement, mesurez les résultats, et itérez en fonction de votre domaine spécifique et des utilisateurs.
Voulez-vous construire des chatbots RAG de qualité professionnelle?
Ce blog est basé sur notre véritable mise en œuvre en production d'un chatbot RAG pour une plateforme de gestion des connaissances professionnelles. Vous pouvez lire l'étude de cas complète, y compris des détails sur l'acheminement intelligent des questions, la synchronisation du contenu en temps réel, et d'autres optimisations que nous avons mises en œuvre.
Intéressé par la mise en œuvre de RAG avec la notation de documents ou d'autres solutions pour votre organisation? Notre équipe se spécialise dans la création d'applications IA prêtes à l'emploi qui apportent une véritable valeur commerciale. Découvrez nos services de développement en IA et prenez contact pour discuter de votre projet.










