
LangChain vs LangGraph vs Raw OpenAI: Comment choisir votre pile RAG

Vous commencez un nouveau projet RAG et vous êtes confronté à une décision qui façonnera vos 6 à 12 prochains mois : utiliser un cadre comme LangChain, ou construire directement avec l'API OpenAI ? Internet offre des conseils contradictoires. Les fils de discussion de X qualifient LangChain de "too much" et de "trop abstrait". Des articles de blogs font l'éloge de ses modèles matures et de son écosystème. Votre équipe est divisée entre "avancer rapidement avec le cadre" et "nous devrions contrôler notre propre code".
Nous avons été confrontés à cette décision exacte lors de la construction d'un chatbot pour une plateforme de gestion des connaissances professionnelles. Après avoir évalué les deux approches et vécu avec notre choix pendant plus de 6 mois en production, nous avons une perspective claire : nous avons choisi LangChain + LangGraph, et nous ferions le même choix à nouveau.
Dans cet article, je vais vous guider à travers le dilemme du choix du cadre et vous expliquer ce que LangChain et LangGraph apportent réellement. Je montrerai aussi quand l'utilisation de l'API OpenAI brute a plus de sens. Ensuite, je partagerai notre expérience de production honnête avec les trois technologies et fournirai un cadre de décision pour vous aider à choisir en toute confiance.
Dans cet article :
- Qu'est-ce qui rend le choix entre LangChain, LangGraph et l'API brute d'OpenAI si difficile ?
- LangChain : ce qu'il fournit réellement (et coûte)
- LangGraph : comment améliore-t-il l'orchestration du flux de travail ?
- LangSmith : comment transforme-t-il l'observabilité dans votre pile RAG ?
- API brute OpenAI : quand cela a-t-il du sens ?
- Qu'avons-nous appris après six mois d'utilisation de LangChain et LangGraph en production ?
- LangChain, LangGraph, ou l'API brute OpenAI pour votre pile RAG - conclusion
- Vous voulez faire des choix technologiques plus intelligents pour votre pile RAG ?
Qu'est-ce qui rend le choix entre LangChain, LangGraph et l'API brute OpenAI si difficile ?
Le choix entre le cadre et l'API brute représente des philosophies fondamentalement différentes du développement logiciel, et la communauté RAG est profondément divisée.
L'argument "utilisez simplement l'API OpenAI"
Ce camp privilégie la simplicité et le contrôle avant tout.
Contrôle maximal
Quand vous écrivez des appels API bruts, vous voyez exactement ce qui se passe. Pas de magie des cadres, pas d'abstractions cachées, pas de comportements surprises. Chaque génération d'incrustations, chaque recherche de vecteurs, chaque appel LLM est un code que vous avez écrit et que vous pouvez déboguer.
Dépendances minimales
Votre requirements.txt comprend 3 à 5 paquets au lieu de 50. Le déploiement est léger. Vous n'êtes pas vulnérable aux bugs du cadre ou aux changements cassants. Lorsque OpenAI met à jour leur API, vous mettez à jour votre code selon votre propre calendrier.
Performance
Pas de surcharge du cadre ou de couches d'abstraction. Votre code exécute exactement ce que vous lui dites de faire, rien de plus. Certaines équipes font état d'une exécution plus rapide sans traitement du cadre.
Validation communautaire
Certains acteurs importants du développement de l'IA critiquent la complexité de LangChain. Une critique courante : le cadre ajoute des couches d'abstraction qui obscurcissent plutôt qu'elles n'éclairent - du style sur la substance.
L'argument "utilisez un cadre"
Ce camp valorise la productivité et les modèles éprouvés.
Modèles RAG matures en boîte
Ne réinventez pas le chargement de documents, le fractionnement de texte, l'intégration de la recherche de vecteurs, les stratégies de récupération, la gestion des invites et les réponses en streaming. Utilisez des implémentations éprouvées que des milliers de développeurs ont affinées.
Temps de production plus rapide
Commencez avec un RAG fonctionnel en quelques heures, pas en semaines. Changez les bases de données vectorielles avec des modifications de configuration, pas des réécritures. Testez différentes stratégies de récupération sans reconstruire votre pipeline.
Écosystème et communauté
Accédez à des centaines d'intégrations : magasins de vecteurs, fournisseurs de LLM, chargeurs de documents, récupérateurs spécialisés. Apprenez à partir des schémas communautaires qui résolvent les mêmes problèmes que vous rencontrerez.
Observabilité intégrée
Des outils comme LangSmith fournissent une visibilité sur les interactions LLM qui prendraient des semaines à construire par vous-même. Voyez chaque invite, chaque réponse, chaque utilisation de jeton, et chaque latence en production.
Pourquoi le choix de la bonne pile RAG est-il important ?
Le choix de la pile RAG pose les bases de tout ce qui suit dans votre projet - des décisions de conception à la facilité avec laquelle vous pouvez évoluer plus tard.
- La dette technique s'accumule : si vous commencez avec l'API brute mais que vous avez besoin plus tard des capacités du cadre (routage, gestion des états, observabilité), la migration est douloureuse. Réciproquement, si vous adoptez un cadre mais que vous n'avez pas besoin de sa complexité, vous avez alourdi votre équipe avec des abstractions inutiles.
- Impact sur la productivité de l'équipe : les frameworks ont des courbes d'apprentissage mais accélèrent ensuite le développement. Les API brutes donnent une clarté immédiate mais accumulent la charge de maintenance. Le mauvais choix affecte la vélocité pendant des mois.
- Fiabilité de la production : les cadres fournissent une gestion des erreurs, une logique de répétition et des schémas de recours. Les implémentations brutes doivent construire ces éléments. Votre choix influence la robustesse du système et la fréquence des incidents.
LangChain : ce qu'il fournit réellement (et coûte)
Examinons ce que vous obtenez (et abandonnez) avec LangChain, basé sur notre expérience de production.
Quels sont les composants RAG prêts à l'emploi dans LangChain ?
La valeur principale de LangChain réside dans les blocs de construction RAG complets :
| Chargeurs de documents |
|
| Diviseurs de texte |
|
| Incarnations (Embeddings) |
|
| Intégrations des magasins de vecteurs |
|
| Recuperateurs |
|
| Schémas d'invite et chaînes |
|
Pourquoi avons-nous choisi LangChain
Notre décision s'est fondée sur quatre facteurs pragmatiques :
1. Capacités RAG matures : nous ne voulions pas réinventer les schémas de récupération. Les implémentations de LangChain sont testées en production et gèrent des cas particuliers que nous ne découvririons pas avant les incidents de production.
2. Développement actif : LangChain publie des mises à jour hebdomadaires. Les bugs sont corrigés rapidement. Les nouveaux modèles et fournisseurs apparaissent rapidement. Le projet a un élan qui suggère une longévité.
3. Soutien financier : LangChain bénéficie d'un solide soutien de l'entreprise. Ce n'est pas un projet parallèle qui pourrait être abandonné. Pour les systèmes de production, la stabilité du cadre est importante.
4. Intégration LangSmith : Le niveau gratuit pour les développeurs de LangSmith offre une capacité d'observation qui coûterait des mois-personnes à construire. Cela à lui seul justifie presque le choix du cadre.
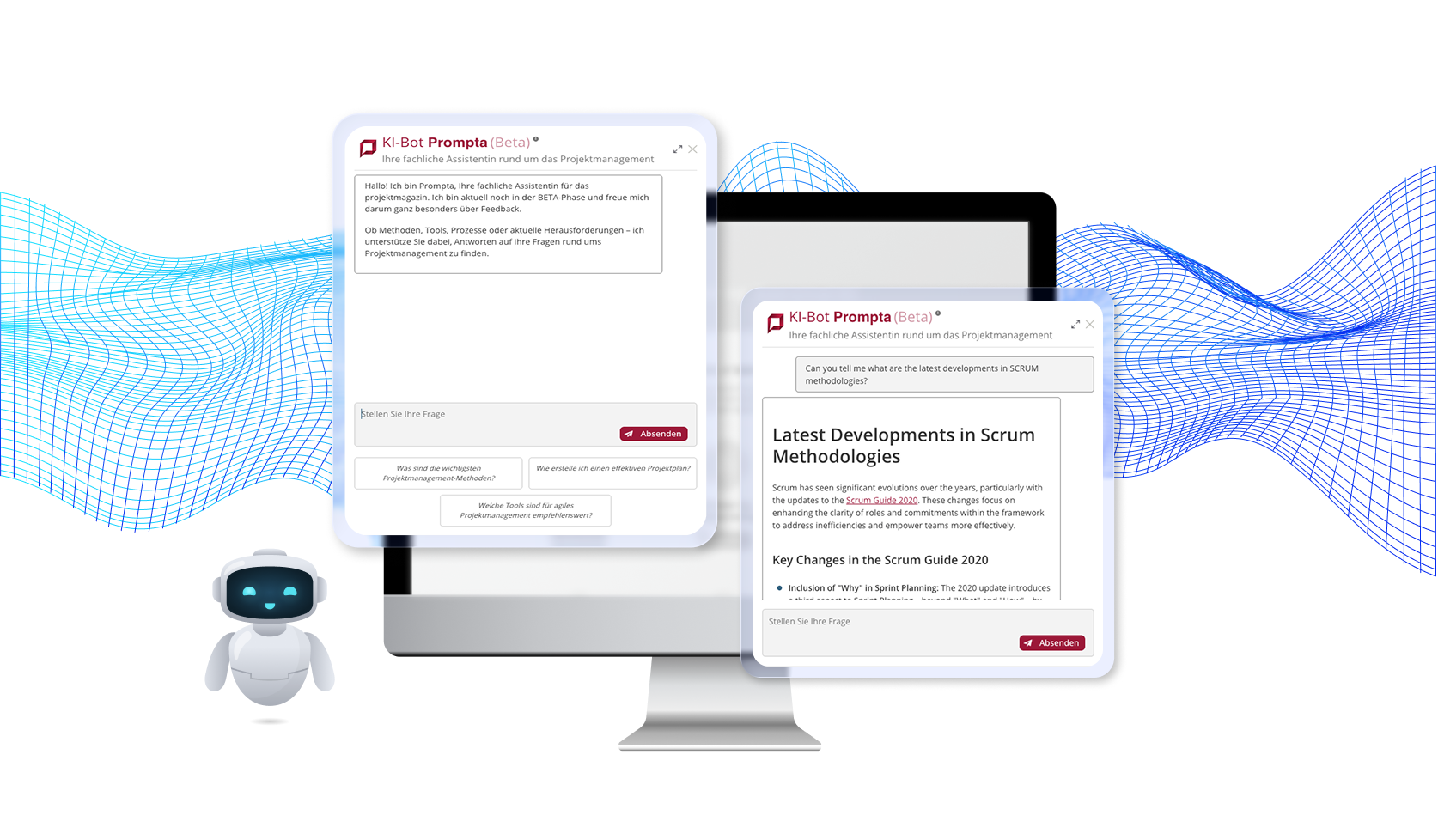
Un exemple de projet dans lequel nous avons utilisé LangChain et LangSmith
Lire notre étude de cas complète : Chatbot documentaire AI →
Quel est le surcoût que nous avons accepté en utilisant LangChain ?
LangChain n'est pas gratuit, vous acceptez une certaine complexité :
- Courbe d'apprentissage : la compréhension des abstractions de LangChain (Documents, Recuperateurs, Chaines, Executables) prend des semaines. Les nouveaux membres de l'équipe ont besoin de temps pour se former. La documentation est parfois en retard par rapport à l'implémentation.
- Les abstractions cachent les détails : parfois, vous devez creuser dans le code source de LangChain pour comprendre le comportement. La "magie" qui accélère le développement peut obscurcir des détails importants lors du débogage.
- Dépendance à l'évolution du cadre : les changements cassants nécessitent parfois des mises à jour du code. Les changements de l'API OpenAI passent par LangChain avec un certain retard. Vous êtes lié au cycle de sortie du cadre.
- Critique communautaire : le sentiment que "LangChain est trop complexe" est réel. Certains développeurs trouvent les abstractions confuses. Le cadre a de fortes opinions qui ne correspondent pas à tous les cas d'utilisation.
- Un certain surcoût de performance : le traitement du cadre ajoute des microsecondes à des millisecondes par opération. Pour la plupart des applications RAG, cela est négligeable, mais les scénarios à haute performance pourraient le remarquer.
LangGraph : comment améliore-t-il l'orchestration du flux de travail ?
LangGraph résout un problème spécifique qui apparaît dans les systèmes RAG de production : les flux de travail conditionnels complexes sont difficiles à construire et à déboguer avec de simples chaînes.
Que propose LangGraph
LangGraph étend LangChain en ajoutant de la structure et de la clarté aux flux de travail RAG complexes.
Gestion de l'état
Définissez un état typé qui circule à travers votre flux de travail :
from typing import TypedDict, List
from langchain.schema import Document
class ChatbotState(TypedDict):
question: str
question_type: str
confidence: float
retrieved_docs: List[Document]
graded_docs: List[Document]
answer: str
Chaque nœud reçoit un état, le modifie, renvoie un état mis à jour. Explicite et débogable.
Définition visuelle du flux de travail
Exprimez des flux complexes sous forme de graphes avec des nœuds et des arêtes :
from langgraph.graph import StateGraph, END
workflow = StateGraph(ChatbotState)
# Définir les nœuds
workflow.add_node("classify_question", classify_question)
workflow.add_node("route_question", route_question)
workflow.add_node("retrieve", retrieve_documents)
workflow.add_node("grade_documents", grade_all_documents)
workflow.add_node("generate", generate_answer)
# Routage conditionnel
workflow.add_conditional_edges(
"classify_question",
route_question,
{
"generic": "handle_generic",
"conversational": "handle_conversational",
"document_search": "retrieve"
}
)
# Flux linéaire pour le chemin de recherche de documents
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "generate")
workflow.add_edge("generate", END)
app = workflow.compile()
La structure du flux de travail est explicite et visuelle. L'ajout de nouveaux nœuds ou routes est simple.
Débogage intégré
LangSmith visualise l'exécution de LangGraph :
- Voir quel chemin a pris la requête.
- Inspecter l'état à chaque nœud.
- Identifier où les échecs se produisent.
- Mesurer la latence par nœud.
À quoi ressemble notre véritable flux de travail de production LangGraph ?
Voici notre véritable flux de production (un peu simplifié par la suppression de la mise en cache) :
Début
↓
classify_question
↓
route_question
├→ [generic] → handle_generic → FIN
├→ [conversational] → handle_conversational → FIN
└→ [document_search]
↓
generate_search_phrase
↓
retrieve (~20 docs)
↓
grade_documents (sélectionner les 12 meilleurs)
↓
generate_answer
↓
FIN
Pourquoi choisir LangGraph plutôt qu'une orchestration de workflow personnalisée ?
LangGraph offre des avantages clairs par rapport à la construction de la logique d'orchestration à partir de zéro, surtout lorsque vous avez besoin de transparence, de maintenabilité et d'itération rapide.
Débogage visuel
Lorsqu'un utilisateur rapporte une "mauvaise réponse", nous ouvrons LangSmith et voyons le chemin d'exécution exact :
- classify_question → "document_search" ✓
- retrieve → 20 documents trouvés ✓
- grade_documents → 0 documents ont passé le seuil ✗ (le bug a été trouvé !)
Sans LangGraph, cela nécessite une journalisation extensive et une corrélation manuelle des traces.
Gestion d'état propre
L'état circule explicitement à travers les nœuds. Pas de variables globales, pas de dépendances implicites. Chaque nœud est une fonction pure : état d'entrée → état de sortie.
Modifications faciles
L'ajout de nouveaux routages (par exemple, les questions "urgentes" contournent l'évaluation) est un changement de configuration :
workflow.add_conditional_edges(
"classify_question",
route_with_urgency,
{
"generic": "handle_generic",
"urgent": "generate_immediately", # Nouveau chemin
"document_search": "retrieve"
}
)Composants testables
Testez les nœuds individuels en isolation :
def test_classify_question():
state = {"question": "Qu'est-ce que le RGPD?"}
result = classify_question(state)
assert result["question_type"] == "document_search"
assert result["confidence"] > 0.7
Quels sont les avantages et les inconvénients de l'utilisation de LangGraph dans votre pile RAG ?
Comme tout cadre, LangGraph introduit un équilibre entre des avantages clairs et des compromis pratiques.
| Pour | Contre |
| ✅ Le débogage visuel dans LangSmith est inestimable | ❌ Une autre abstraction à apprendre |
| ✅ Séparation claire des préoccupations | ❌ Modèles spécifiques au cadre |
| ✅ Facilité d'ajout de nouvelles routes/nœuds | ❌ Un certain surcoût par rapport aux fonctions simples |
| ✅ Gestion explicite de l'état | ❌ Nécessite la compréhension des concepts de graphes |
| ✅ Nœuds individuels testables | ❌ Documentation limitée pour des cas d'utilisation avancés |
LangSmith : comment transforme-t-il l'observabilité de votre pile RAG ?
LangSmith est la raison pour laquelle nous choisirions à nouveau LangChain même si rien d'autre n'avait d'importance. Le niveau gratuit pour les développeurs offre une observabilité de niveau production qui prendrait des mois-personne à construire.
Que propose LangSmith (niveau gratuit)
LangSmith apporte une observabilité de niveau production à tout flux de travail RAG, donnant aux développeurs une visibilité totale sur le comportement de leurs systèmes alimentés par LLM.
Traces complètes des interactions LLM
Chaque appel à n'importe quel LLM est automatiquement consigné :
- Prompt exact envoyé.
- Réponse complète reçue.
- Modèle et paramètres utilisés.
- Utilisation des tokens (répartition entrée/sortie).
- Mesure de la latence.
- Statut de succès/erreur.
Suivi des coûts
En fonction de la tarification du modèle et de l'utilisation réelle des tokens, LangSmith estime les coûts par requête. Voir immédiatement les opérations coûteuses.
Visualisation de LangGraph
Représentation visuelle de l'exécution du flux de travail :
- Quels nœuds ont été exécutés.
- Temps passé dans chaque nœud.
- Transitions d'état.
- Décisions de routage conditionnel.
Investigation des erreurs
Les requêtes échouées incluent le contexte complet :
- Quelles entrées ont causé l'échec.
- Quel nœud a échoué.
- Message d'erreur et trace de la pile.
- Etat au moment de l'échec.
Exemple de débogage en production avec LangSmith
Plainte de l'utilisateur :
"Le chatbot m'a donné des informations complètement hors de propos sur l'authentification lorsque j'ai demandé des informations sur le cryptage des données."
Sans LangSmith :
- Examiner les journaux d'application (requête/réponse générique).
- Essayer de reproduire le problème.
- Ajouter plus de journaux.
- Déployer une nouvelle version.
- Attendre que cela se reproduise.
- Émettre une hypothèse sur la cause première.
Avec LangSmith :
1. Rechercher les traces du texte de la requête de l'utilisateur.
2. Ouvrir la trace, voir l'exécution complète de LangGraph :
- classify_question → classifié comme "document_search" ✓
- generate_search_phrase → généré : "authentication security" ✗ (faux!).
- retrieve → a renvoyé des documents d'authentification (techniquement correct pour un mauvais terme de recherche).
- grade_documents → a passé les documents d'authentification comme pertinents.
- generate → a répondu à propos de l'authentification (a suivi le prompt correctement).
3. Cause première trouvée en 2 minutes : l'étape de génération de la phrase de recherche a mal interprété "data encryption" comme "authentication."
4. Correction : améliorer le prompt de génération de la phrase de recherche avec de meilleurs exemples pour les requêtes de cryptage.
Optimisation de l'utilisation des tokens
LangSmith montre la consommation de tokens par nœud :
Exemple de répartition des requêtes
- classify_question: 150 tokens ($0.000375)
- grade_documents: 20 appels × 250 tokens = 5,000 tokens ($0.0125)
- generate: 15,000 tokens ($0.0375)
- Total: 20,150 tokens ($0.050375)
Nous avons découvert que l'évaluation des documents consommait 25% des coûts. Cette prise de conscience a conduit à l'optimisation des prompts d'évaluation (plus courts, plus ciblés) et à la mise en place d'un cache pour les questions courantes.
Pourquoi LangSmith justifie-t-il le choix de LangChain ?
Construire une observabilité équivalente nous-même nécessiterait :
- Système de journalisation des interactions LLM
- Suivi de l'utilisation des tokens
- Calcul des coûts par modèle
- Visualiseur de traces visuelles
- UI de recherche et de filtrage
- Outils d'inspection de l'état
LangSmith fournit tout cela gratuitement (niveau développeur) ou pour un faible coût mensuel (niveau équipe). Même si LangChain n'avait pas d'autres avantages, LangSmith justifie l'utilisation du cadre.
API brute OpenAI : quand cela a-t-il du sens ?
Malgré notre choix, l'API brute est absolument le bon choix pour certains projets. Soyons honnêtes sur le moment où les frais généraux du framework ne sont pas justifiés.
Cas d'utilisation où l'API brute brille
Alors que les cadres simplifient les pipelines RAG complexes, il existe de nombreux scénarios où travailler directement avec l'API brute OpenAI est plus rapide, plus propre et plus pratique.
Questions-réponses simples
Si vous construisez des Q&R simples sans récupération de documents :
import openai
def simple_qa(question: str) -> str:
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "Tu es un assistant utile."},
{"role": "user", "content": question}
]
)
return response.choices[0].message.contentPas besoin de framework. Clair, simple, maintenable.
Exigences de contrôle maximal
Les projets de recherche explorant de nouvelles architectures RAG bénéficient d'un contrôle complet. Des stratégies d'incorporation personnalisées, des algorithmes de récupération spécialisés, des approches expérimentales - tout est plus facile sans les abstractions du cadre.
Contraintes minimales de dépendance
Les systèmes embarqués, les fonctions AWS Lambda avec des limites de taille, ou les organisations avec des politiques de dépendance strictes peuvent interdire les cadres. L'API brute vous donne exactement ce dont vous avez besoin, rien de plus.
Apprentissage et éducation
Comprendre RAG à partir des premiers principes signifie construire sans cadres. Les implémentations éducatives bénéficient de voir chaque étape explicitement.
Lisez aussi : Comment accélérer les réponses des chatbots IA avec la mise en cache intelligente
Quels sont les principaux avantages d'une implémentation brute de l'OpenAI ?
Utiliser l'API brute OpenAI présente plusieurs avantages clairs qui en font un choix fort pour certaines équipes et projets.
- Transparence totale : chaque ligne de code est la vôtre. Pas de magie de cadre. Pas de comportement caché. Le débogage signifie lire le code que vous avez écrit.
- Zéro frais généraux de cadre : aucune couche d'abstraction, aucun traitement de cadre. Votre code exécute exactement ce que vous avez spécifié.
- Pas de courbe d'apprentissage : les membres de l'équipe comprennent Python et l'API OpenAI. Pas de modèles spécifiques au cadre à apprendre.
Quels sont les inconvénients de l'utilisation de l'API brute OpenAI sans cadre ?
Bien que l'utilisation de l'API brute OpenAI offre un contrôle total, elle comporte également un certain nombre de défis et de limitations que les équipes doivent prévoir.
- Inventer des modèles :
- Stratégies de fragmentation des documents (respecter les limites sémantiques).
- Optimisation de la récupération (MMR, recherche hybride).
- Réponses en flux continu (gestion asynchrone).
- Gestion des erreurs et tentatives de reprise.
- Gestion des modèles d'incitation.
- Mémoire de conversation.
- Pas d'observabilité intégrée : vous devrez construire de zéro la journalisation, le suivi, la surveillance. Estimez entre 2 et 4 semaines pour obtenir une observabilité de niveau production.
- Travail d'intégration : chaque base de données vectorielle nécessite un code d'intégration personnalisé. Changer de fournisseurs signifie réécrire la couche de base de données.
- Charge de maintenance : tout le code est à votre charge. Les changements de l'API OpenAI nécessitent des mises à jour immédiates. Pas de communauté qui contribue des corrections.
Qu'avons-nous appris après six mois d'utilisation de LangChain et LangGraph en production?
Nous avons utilisé LangChain + LangGraph en production pendant plus de 6 mois, pour de vrais utilisateurs. Il est temps de faire preuve d'une honnêteté brutale.
Choisirions-nous à nouveau LangChain?
OUI, malgré la critique communautaire et sa complexité.
Pourquoi choisirions-nous à nouveau LangChain pour notre pile RAG?
Après plusieurs mois en production, certains aspects de LangChain se sont avérés suffisamment précieux pour que nous choisissions à nouveau cette technologie pour notre pile RAG.
1. Observabilité de LangSmith: nous a permis d'économiser des dizaines d'heures de débogage. Aperçu de l'optimisation des coûts. Une visibilité de la production que nous n'aurions jamais développée nous-mêmes. Justifie à elle seule l'utilisation du framework.
2. Temps de mise en production plus rapide: la pile RAG fonctionnelle en quelques jours, pas en semaines. Intégration d'Elasticsearch instantanée. Récupération de MMR intégrée. Gestion du streaming automatique. Ces accélérations s'additionnent.
3. Productivité de l'équipe: les nouveaux développeurs s'intègrent plus rapidement grâce à des modèles établis. Des solutions communautaires existent pour les problèmes courants. Les mises à jour du framework apportent des améliorations que nous n'implémenterions jamais.
4. Réalité de la maintenance: nous craignions de devoir lutter contre les limites du framework. En 6 mois, cela s'est produit deux fois, et a été résolu rapidement. Le framework a été un facilitateur et non une contrainte.
5. Optimisation des coûts: LangSmith a révélé des opérations coûteuses. La flexibilité du framework a permis des optimisations (mise en cache, routage) qui ont réduit de manière significative les coûts.
Critiques communautaires de LangChain: ce avec quoi nous sommes d'accord
"LangChain est complexe": VRAI
La courbe d'apprentissage est réelle. La documentation est parfois confuse. Les abstractions prennent du temps à comprendre. Le framework est objectivement complexe.
"C'est trop pour des cas simples": ABSOLUMENT
Pour des Q&R basiques ou des prompts simples, LangChain constitue une surcharge inutile. L'API brute est objectivement meilleure pour des cas d'utilisation simples.
Critiques communautaires de LangChain: ce en quoi nous ne sommes pas d'accord
"Il suffit d'utiliser l'API OpenAI": pas pour une pile RAG complexe
Ce conseil s'applique à la formulation de prompts simples. Pour l'évaluation de documents, le routage conditionnel, la gestion de l'état et l'observabilité, le framework apporte une réelle valeur.
"Le framework vous freinera": ce n'a pas été le cas dans notre expérience
Six mois plus tard: chaque fonctionnalité dont nous avions besoin était réalisable. Le framework a été flexible.
"La surcharge de performance est importante": négligeable en pratique
Nos mesures montrent que le framework ajoute quelques millisecondes. Pour une pile RAG où les appels LLM dominent la latence. La surcharge du framework est insignifiante.
"Pas prêt pour la production": nous sommes en production avec succès
Le client est satisfait. Le système est fiable et gère réellement le trafic utilisateur. Le framework a été conforme à nos besoins en matière de production.
LangChain, LangGraph, ou l'API brute OpenAI pour votre pile RAG - conclusion
Après 6 mois en production avec LangChain, LangGraph, et LangSmith, notre verdict est clair: pour des systèmes RAG complexes, la surcharge du framework est justifiée par les gains de productivité et les avantages en matière d'observabilité. Les critiques de la communauté sont valides - LangChain est complexe, les abstractions sont parfois obscures, et la courbe d'apprentissage est réelle. Mais en produirein, les réalités favorisent les modèles éprouvés et les outils intégrés plutôt que la simplicité maximale.
Notre principale prise de conscience: LangSmith justifie à lui seul l'utilisation de LangChain. L'observabilité de niveau professionnel, qui prendrait des mois-personnes à développer est incluse gratuitement. Lorsque le débogage "pourquoi cette requête a-t-elle échoué ?" prend 2 minutes au lieu de 2 heures, la surcharge du framework devient insignifiante. Ajoutez à cela l'intégration d'Elasticsearch, la récupération de MMR, les stratégies de fragmentation de documents, et le support du streaming, et les gains de productivité se cumulent.
La décision n'est pas idéologique, elle est pragmatique. Évaluez votre complexité, les préférences de votre équipe, la pression du temps, et vos besoins en matière d'observabilité. Choisissez l'approche qui accélère spécifiquement votre projet. Les deux voies mènent à des systèmes qui fonctionnent.
Voulez-vous faire des choix technologiques plus intelligents pour votre pile RAG?
Cet article de blog est basé sur notre mise en œuvre en production en utilisant LangChain, LangGraph, et LangSmith pendant plus de six mois pour servir de vrais utilisateurs. Vous pouvez lire l'étude de cas du chatbot de documents AI, qui comprend des détails sur la pile technologique, l'évaluation des documents, la mise en cache des réponses, la synchronisation en temps réel, et l'observabilité complète.
Vous êtes intéressé à construire ou optimiser des systèmes RAG de qualité professionnelle avec les bons outils pour votre cas d'utilisation? Notre équipe se spécialise dans la création de solutions IA qui combinent flexibilité, performance, et efficacité coût. Consultez nos services de développement IA pour savoir comment nous pouvons vous aider à choisir et à mettre en œuvre la meilleure pile pour votre projet.










