
Quels outils de surveillance de la disponibilité des serveurs valent la peine d'être utilisés ?

La surveillance des serveurs est un processus complexe de contrôle de toute l'infrastructure du serveur et de ses dépendances afin d'analyser l'utilisation des ressources système et de les optimiser pour fournir des services aux utilisateurs finaux. C'est sans aucun doute l'un des éléments clés pour le bon fonctionnement des infrastructures. Par conséquent, choisir le bon outil de surveillance de la disponibilité des serveurs est important pour toute entreprise.
Pourquoi la surveillance de la disponibilité est-elle importante ?
La surveillance est une norme dans le monde de l'informatique car elle permet de maintenir les serveurs de l'entreprise en état optimal. Le processus de surveillance des performances des serveurs est assez simple - il repose sur la collecte régulière des données du serveur et leur analyse en temps réel ou historique. Grâce à cela, nous pouvons garantir que les serveurs fonctionnent de manière optimale, remplissant ainsi la fonction prévue.
Vous pouvez surveiller presque tout, y compris le contrôle des performances du processeur, la consommation de mémoire, le réseau, la bande passante de l'espace disque, ainsi que l'identification des problèmes liés à l'utilisation des serveurs. Cependant, savoir comment surveiller votre serveur ne suffit pas. Il est nécessaire de comprendre pourquoi c'est une partie si importante de la sécurité de l'organisation. Le but de la surveillance est d'informer sur les pannes et les problèmes de performances et de résoudre les problèmes à l'avance. En pratique, cela signifie que les pannes ou anomalies sont détectées si rapidement que le service, l'application ou l'opération entière de l'entreprise n'est pas interrompue. En conséquence, l'infrastructure des serveurs de l'entreprise fonctionne de manière correcte et stable, et l'organisation ne subit pas de pertes causées par de longues interruptions de fonctionnement du système.
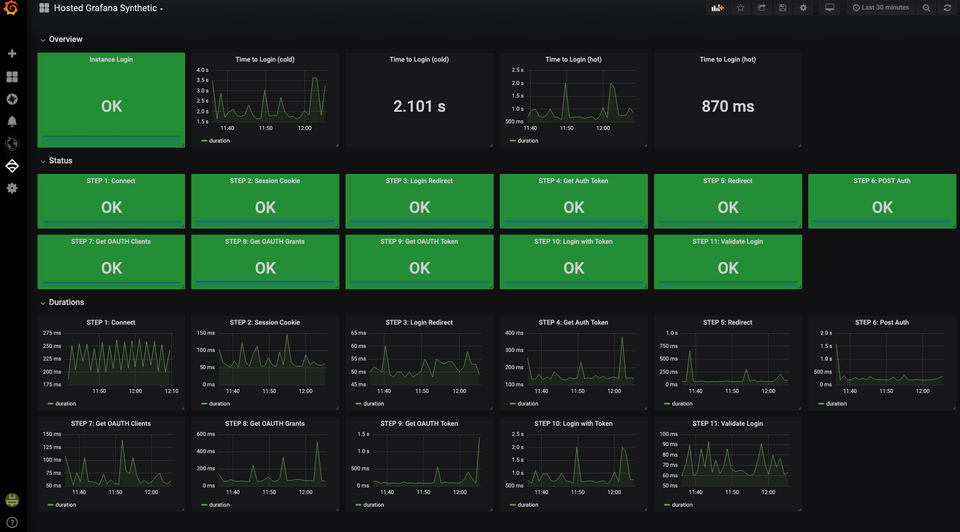
Source : Grafana
Comment savoir si un serveur est en panne ?
Une surveillance appropriée et ininterrompue des serveurs garantit que le serveur fonctionne et qu'il est correctement optimisé. De plus, elle permet de minimiser le risque d'interruptions dans le fonctionnement du système, et lorsqu'une panne survient - d'effectuer une analyse précise des processus, ce qui conduira à une réparation rapide. Cependant, personne ne peut jamais prédire l'avenir, et tout peut arriver - l'application cessera de fonctionner, le serveur manquera de ressources, il y aura un problème avec la disponibilité des services du FAI, etc. Dans un tel cas, l'information sur la page web ou les autres services indisponibles devrait être fournie par le système de surveillance, et non par le PDG de l'entreprise ou l'utilisateur final. Pour éviter de telles situations, vous devriez mettre en place un outil de surveillance approprié qui aidera à prévenir d'éventuels problèmes et pannes en informant les administrateurs ou les départements responsables de ceux-ci.
1. Zabbix
C'est le leader non officiel dans le domaine de la surveillance. Les origines de cet outil remontent à 1998, et son créateur et fondateur est Alexei Vladishev, qui continue à développer activement son produit. Zabbix est une solution open source basée sur la GPL (General Public License), ce qui la rend gratuite pour une utilisation commerciale et non commerciale. Jusqu'à présent, le programme a une douzaine de versions, et actuellement, sa version la plus populaire est la 5.0 LTS, avec cinq ans de support à long terme, ce qui est idéal pour l'environnement de production. La version suivante porte le numéro 5.4, et la 6.0 LTS a été récemment publiée, tandis que la feuille de route informe des plans pour plus de versions - jusqu'à la 7.0 LTS. Chaque nouvelle version inclut un certain nombre de nouveaux changements, prenant en compte les besoins et les exigences du marché informatique dynamique. La version 6.0 introduit de nouvelles fonctionnalités. Les plus intéressantes parmi elles sont la surveillance des clusters Kubernetes, la détection des anomalies basée sur l'apprentissage automatique, et l'élargissement de la surveillance en termes de business.
Le système Zabbix permet de surveiller les appareils supportant les technologies SNMP, IPMI, et les protocoles ICMP, TCP, UDP, HTTP, ainsi que de créer vos propres éléments de surveillance. La surveillance du matériel comprend les ordinateurs de bureau, les serveurs physiques, les serveurs virtuels, les disques réseau, les commutateurs, les routeurs, les environnements Windows et Linux, et bien plus encore. Les fonctionnalités de Zabbix sont énormes et permettent de surveiller, par exemple :
- la charge des processeurs, cartes réseau, et mémoire, la quantité d'espace sur les disques durs,
- les sites web et applications web,
- les protocoles réseau standard : SMTP, ICMP, SSH, TELNET, IPMI, JPX, HTTP/HTTPS,
- les localisations distribuées (agences ou filiales),
- la validité des certificats SSL sur les pages web,
- la température des composants individuels,
- l'exécution correcte d'une requête SQL.
Pour surveiller les ressources énumérées ci-dessus, vous pouvez utiliser des modèles gratuits prêts à l'emploi ou créer les vôtres.
L'architecture de Zabbix se compose de plusieurs éléments. Le plus important d'entre eux est le serveur Zabbix, qui est responsable de la réception, de l'agrégation et du traitement des données, ainsi que de la génération d'événements sur leur base et de la détection d'anomalies. Pour les incidents sélectionnés, vous pouvez envoyer des alertes sous forme de SMS, email, ou en utilisant Webhook pour l'intégration avec les systèmes de helpdesk les plus populaires, les chats et messageries (par ex. Microsoft Teams, Messenger). Un autre élément est Zabbix Agent, qui collecte les métriques du système d'exploitation localement. Ce démon, disponible dans les systèmes UNIX et Windows, consomme peu de ressources et peut fonctionner en mode passif ou actif. En mode passif, l'agent traite la demande du serveur avec la liste des paramètres qu'il doit contrôler et lui renvoie les données collectées. En mode actif, l'agent établit d'abord la communication avec le serveur et lui envoie régulièrement des données. Ce mode est utile lorsque le serveur ne peut pas communiquer directement avec l'agent pour une raison quelconque. Grâce à ses nombreux modèles intégrés, l'agent peut vérifier de nombreux paramètres sans configuration supplémentaire. Un élément optionnel que vous pouvez utiliser est le serveur Proxy Zabbix, qui fait la médiation de la communication entre Zabbix Agent et Zabbix Server. Une telle solution vaut la peine d'être appliquée dans une infrastructure répartie sur plusieurs sites, par exemple, les départements de l'entreprise, les localisations avec une connectivité médiocre, ou les endroits sans administrateurs locaux.
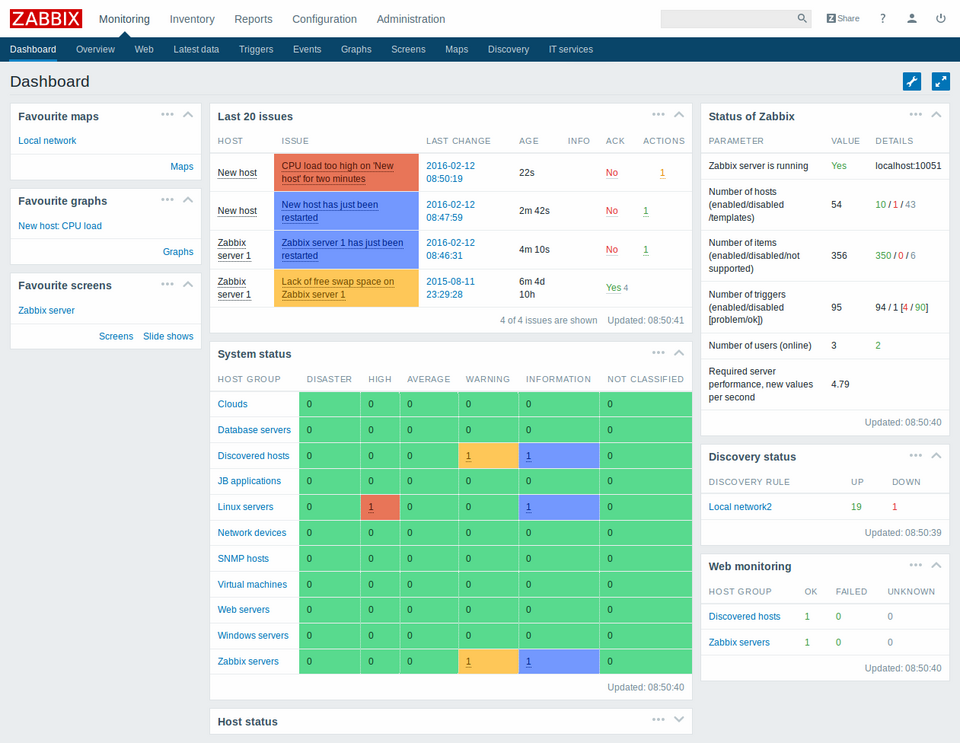
Source : Zabbix
Zabbix offre également un large éventail d'intégrations avec divers systèmes et plateformes. Parmi le grand nombre de ces intégrations, qui s'élève à plus de 500 outils, il faut noter les intégrations avec :
- les plus grands fournisseurs de services cloud (par ex. AWS, Azure, Google),
- les conteneurs (par ex. Docker, LXC),
- les systèmes de tickets (par ex. Jira, OTRS),
- les systèmes de gestion de configuration (par ex. Ansible, Puppet),
- les systèmes de messagerie (par ex. PagerDuty, Slack).
Le grand avantage de Zabbix est sa communauté et la possibilité d'acquérir des connaissances par de nombreux canaux de support (y compris le système de support, Telegram, Discord, Forum Zabbix). Pour les clients les plus exigeants, le fabricant a préparé cinq niveaux de support différents - selon les besoins attendus.
2. Nagios XI
Nagios XI est un système de surveillance de l'infrastructure d'entreprise provenant du monde open source. Ce logiciel a été créé sur la base du moteur Nagios Core, qui au fil du temps a été enrichi de fonctions adaptées aux clients professionnels. Nagios Core est resté un outil gratuit, développé sous la licence GNU GPL v2, tandis que Nagios XI est devenu une solution entièrement commerciale.
L'architecture de Nagios XI est basée sur la famille des systèmes Linux/Unix avec des systèmes dédiés pour l'installation : CentOS, Redhat Enterprise Linux, Ubuntu et Debian. Cependant, l'outil peut également être déployé sur Windows, en utilisant le VMware Workstation Player ou l'environnement virtuel Hyper-V. Cet outil a des possibilités illimitées et est utilisé pour une surveillance complète de l'infrastructure. En plus de la surveillance des éléments d'infrastructure critiques, c'est-à-dire les appareils et les protocoles réseau, les applications, les systèmes d'exploitation, les bases de données, Nagios XI offre la surveillance des ressources informatiques, le contrôle des paramètres environnementaux, et l'IoT. Les clients peuvent choisir entre deux versions du produit : Standard Edition et Enterprise Edition.
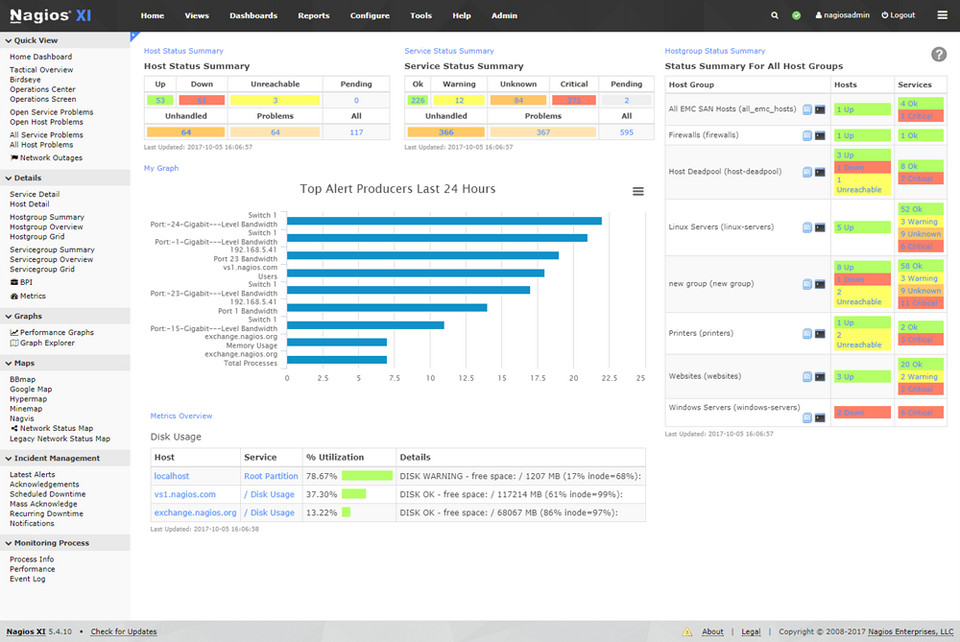
Source : Nagios
Bien que Nagios XI soit un outil commercial, le fabricant offre une licence gratuite couvrant jusqu'à sept nœuds, ce qui peut être extrêmement avantageux pour un usage domestique – parmi les exemples sont :
- la surveillance de l'état du serveur de fichiers domestique (stockage, température),
- la surveillance de l'état de l'imprimante (niveau d'encre et de papier dans l'imprimante), du routeur ou commutateur,
- l'utilisation dans une maison intelligente avec Raspberry Pi, la collecte de données de capteurs et la fourniture de données sur, par exemple, le niveau de l'eau souterraine, l'ensoleillement, ou même l'acidité (pH) du sol, et les alertes de statut des portes du garage en fonction de l'heure de la journée.
L'outil est opéré depuis le niveau du navigateur, et l'interface elle-même est simple et claire. Cependant, il y a place à l'amélioration ici, car l'interface utilisateur diffère clairement des tendances actuelles.
D'autre part, les assistants de configuration de Nagios XI sont intuitifs, faciles à utiliser, et ne nécessitent pas de connaissances sur des processus complexes de surveillance de l'infrastructure informatique. Les données collectées sont utilisées pour des graphiques, journaux d'événements, statistiques, analyse de tendances, ainsi que pour la planification des ressources et des performances. Les alertes concernant, par exemple, l'indisponibilité des services ou le dépassement des valeurs critiques, sont envoyées par e-mail et SMS.
Les capacités du système peuvent être étendues grâce à un large éventail de modules complémentaires tiers disponibles sous licence GPL. Nagios XI dispose également d'une architecture extensible avec la possibilité d'utiliser n'importe quel langage de programmation préféré. Le système fournit de nombreuses API, assurant une intégration facile avec les applications internes et externes.
3. Prometheus
Prometheus, considéré comme un outil de surveillance et d'alerte système open source, a été créé en 2012 par d'anciens employés de Google. Au départ, il était destiné à être utilisé uniquement pour la surveillance d'environnements conteneurisés, mais il a étendu ses capacités aux applications, serveurs, bases de données et machines virtuelles au fil du temps. Actuellement, le système est intensivement développé dans les environnements cloud.
Prometheus est un outil open source indépendant, activement soutenu par une communauté de développeurs, et tous ses composants sont disponibles sous la licence Apache 2 sur GitHub. Cependant, cela n'empêche pas les grandes entreprises d'utiliser ce système comme un élément clé de l'infrastructure. Parmi les clients figurent, par exemple, DigitalOcean, Docker, Showmax, ou SoundCloud. De plus, la force de l'outil est démontrée par le fait que Prometheus a rejoint la Cloud Native Computing Foundation comme deuxième projet après Kubernetes. Seuls les fournisseurs des projets open source les plus rapides en développement reçoivent une telle distinction.
L'élément clé du fonctionnement de cet outil sont les métriques qui caractérisent une application ou une instance donnée et fournissent des informations à leur sujet. Les bibliothèques clients pour Prometheus offrent quatre principaux types de métriques intégrées capables de fournir diverses données, par exemple, le nombre de requêtes HTTP et d'erreurs (la métrique Counter), le temps de réponse (Histogram), l'utilisation de la mémoire (Gauge), et le nombre d'utilisateurs actifs (Summary). Chaque métrique est attribuée à un nom qui peut être référencé, ainsi que des paires clé-valeur optionnelles appelées labels. Prometheus collecte les métriques basées sur les méthodes push et pull. Dans la première méthode, l'application surveillée est responsable de l'envoi de ses propres métriques au système de surveillance par Pushgateway. Cependant, dans la méthode pull, l'application est passive et ne prépare que ses métriques sous la forme d'un endpoint, tandis que Prometheus décide du moment où les télécharger sur la base des règles. Cet outil de surveillance de la disponibilité des serveurs possède une base de données de séries chronologiques intégrée efficace, de sorte que les informations sur les métriques sont stockées avec l'horodatage indiquant le moment où elles ont été enregistrées.
L'un des piliers de l'outil est Prometheus Query Language (PromQL), utilisé pour interroger et agréger les données de surveillance en temps réel, en utilisant une variété d'opérateurs et de fonctions. L'application indépendante Alertmanager est utilisée pour automatiser la surveillance, qui génère et envoie des alertes lorsque certaines conditions sont observées. Prometheus fournit un large éventail d'exportateurs afin de tout surveiller pratiquement, mais il n'a pas la capacité de visualiser les données collectées lui-même. C'est là que Grafana entre en jeu, où les tableaux de bord se connectent aux sources de données pour visualiser les métriques presque en temps réel. Les spécialistes des deux solutions collaborent intensivement les uns avec les autres, développant déjà l'intégration avancée avec Prometheus dans Grafana et fournissant aux clients de Grafana l'accès aux fonctions de Prometheus dont ils ont besoin.
La collaboration avec le plus grand fournisseur de services cloud, Amazon Web Services, apporte également de grands résultats. L'année dernière, Amazon Managed Service for Prometheus a été lancé. Il est entièrement compatible avec Prometheus, possède une haute disponibilité, s'adapte automatiquement à mesure que les besoins augmentent, et inclut la conformité et la suite de sécurité d'AWS. Le service permet de collecter des métriques depuis les environnements Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), et Amazon Elastic Kubernetes Service (Amazon EKS).
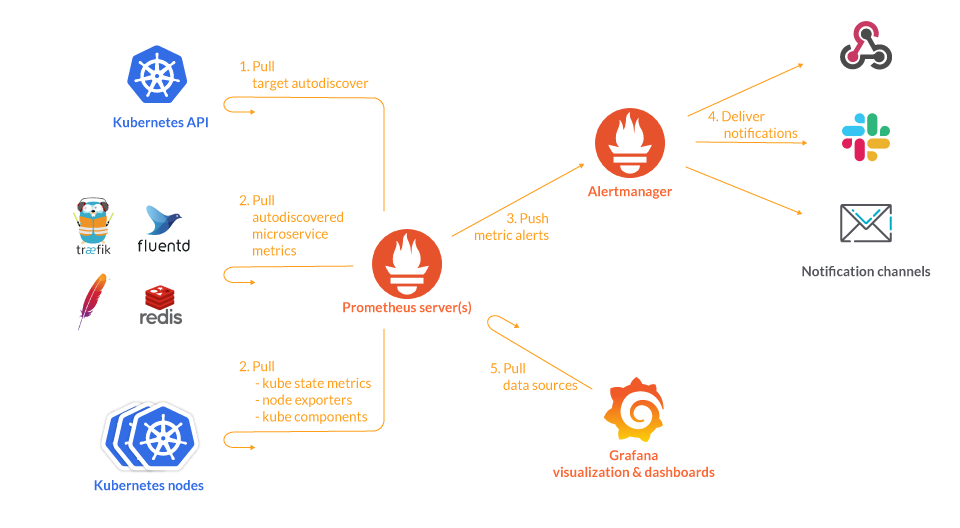
Source : Sysdig
4. Datadog
C'est une solution complète pour la surveillance et l'analyse de l'infrastructure et des applications. L'outil permet de visualiser les données collectées et d'envoyer des notifications sur les problèmes techniques, aidant les administrateurs à détecter les erreurs critiques et à contrôler complètement les systèmes informatiques. Datadog fonctionne dans le modèle SaaS et est utilisé dans l'infrastructure basée sur le cloud, hybride ou local. Son champ d'application inclut la surveillance traditionnelle de l'infrastructure, la surveillance des performances des applications en temps réel, l'activité du réseau et l'analyse du trafic, la surveillance des performances des bases de données, DNS et bande passante.
Datadog agrège les métriques et événements en un seul endroit, permet de les analyser facilement et distingue les valeurs actuelles des KPI, SLO et SLA critiques. Des tableaux de bord transparents et dynamiques sont utilisés pour cela, sans besoin d'utiliser un langage de requête ou de coder, avec un large éventail de bibliothèques avec des formules, fonctions, et widgets par glisser-déposer.
La résolution des problèmes, les alertes et la création de graphiques sont possibles grâce à plus de 500 intégrations, parmi lesquelles vous pouvez trouver une coopération avec Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, OpenStack, ou Red Hat OpenShift. De plus, Datadog est compatible avec les métriques des outils DevOps de plus en plus populaires – Kubernetes et Prometheus. L'avantage du système est également la gestion des journaux. La collecte des journaux de tous les services, applications et plateformes, la recherche et le filtrage de ceux-ci, le marquage automatique, la visualisation, et l'alerte des données de journaux – tout cela signifie une surveillance plus efficace. Des solutions basées sur l'intelligence artificielle sont utilisées pour détecter les anomalies. Les alertes concernant les problèmes dans l'environnement sont envoyées par e-mail, PagerDuty, Slack, Hangouts Chat, et Microsoft Teams. La force du système Datadog est démontrée par la taille de ses clients. Il est utilisé par des marques telles que Samsung, Siemens, Lego System, Sony, et Lufthansa Systems.
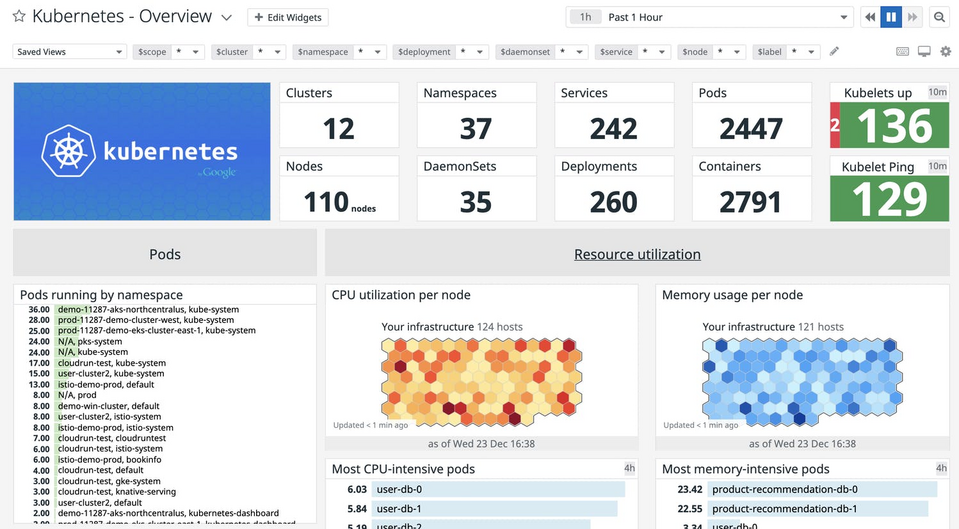
Source : Datadog
5. Sematext
Sematext est une solution pour la surveillance des performances de l'infrastructure et des applications, ainsi que pour la gestion des journaux. L'outil peut être utilisé dans la version Cloud ou Enterprise. Alors que Sematext Cloud est un service SaaS entièrement géré, Sematext Enterprise est un package prêt à être téléchargé et exécuté dans votre infrastructure. Les deux versions contiennent le même package de services et permettent une visibilité complète de l'infrastructure, la surveillance des conteneurs et des bases de données, le contrôle des performances des applications, la gestion des journaux, et les alertes. La version cloud de plus en plus populaire se caractérise par une haute disponibilité, une évolutivité, et des performances, ainsi que la surveillance des services dans les clouds privés, publics et hybrides. Pour commencer à travailler sur les hôtes, un agent qui reconnaît automatiquement les éléments à surveiller est requis. Les hôtes peuvent être n'importe quelles machines physiques, systèmes dans des environnements virtuels, conteneurs (Docker, ECS), ou clusters (EKS, Kubernetes).
Sematext offre des services Elasticsearch et Kibana entièrement gérés sans besoin de spécialistes et d'infrastructure coûteux, vous faisant gagner du temps sur la maintenance du système. L'interface et le fonctionnement du tableau de bord sont conviviaux et permettent :
- le filtrage et l'analyse des métriques et événements,
- la recherche de données,
- la création de tableaux de bord et de rapports personnalisés,
- la génération d'alertes personnalisées basées sur les performances des services,
- la résolution des problèmes de performance,
- et la détection des tendances et des modèles.
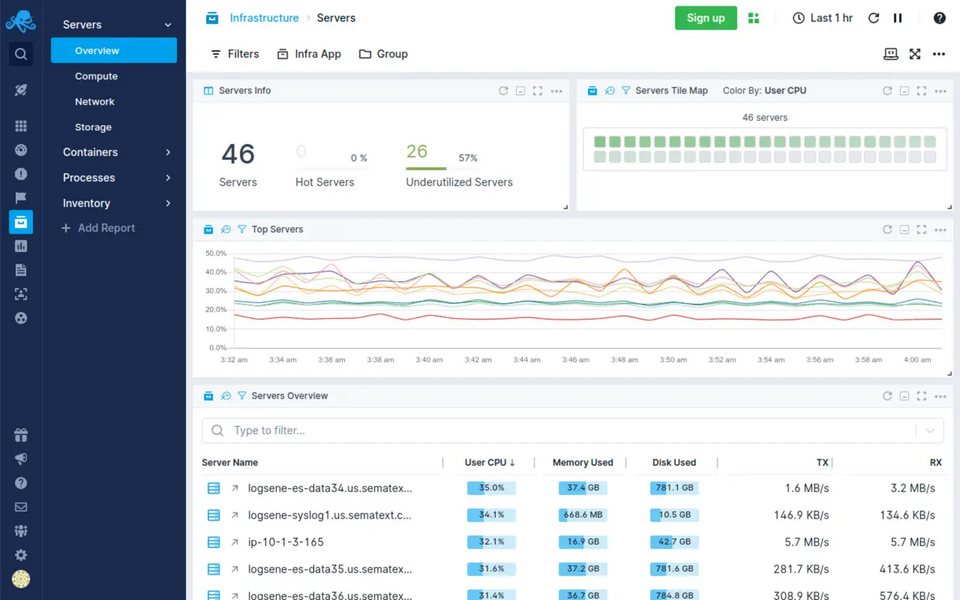
Source : Sematext
La gestion des journaux est effectuée par le service Sematext Logs, qui collecte les messages de journaux et les analyse en temps réel à l'aide d'une version hébergée de la stack ELK dans le cloud ou sur site. L'outil permet de stocker, d'indexer, et de rechercher des journaux de différents types (journaux d'application, de serveur, de conteneur, d'événement personnalisé, journaux d'application mobile) et d'agréger les journaux de plusieurs sources. Le processus d'envoi des journaux se déroule via l'API Elasticsearch ou Syslog.
Les alertes dans Sematext sont utilisées pour notifier de l'accomplissement d'au moins une des conditions prédéfinies dans les métriques, les journaux, ou les données basées sur les données historiques. Les types d'alertes les plus importants incluent :
- les alertes classiques – basées sur des seuils et déclenchées lorsqu'un seuil donné est dépassé,
- les anomalies – elles sont basées sur des statistiques et sont déclenchées lorsque les valeurs changent soudainement et dévient de la ligne de base constamment calculée,
- les alertes de pulsation – exécutées lorsque Sematext cesse de recevoir des données du serveur, conteneur, application, etc., pendant une période spécifiée.
Les alertes intègrent, par exemple, avec Slack, PagerDuty, Teams, Google Chat, ainsi que l'e-mail.
Sematext se développe principalement vers le cloud, donc il fonctionne très bien avec les plus grands fournisseurs de cloud, c'est-à-dire AWS, Microsoft Azure, Google Cloud Platform, DigitalOcean et IBM Cloud.
Sematext est un grand acteur sur le marché de la surveillance informatique, comme en témoigne le fait que parmi ses clients figurent des entreprises telles qu'eBay, Dell, Instagram, et Microsoft. Pour ses clients, le fabricant a préparé trois plans : Basic, Standard et Pro, pour chacun des quatre modules : Logs, Monitoring, Experience, Synthetics. Chaque module peut être testé pendant une période d'essai de 14 jours. Sematext fournit les API InfluxDB et Elasticsearch pour les métriques, les journaux, et les événements, facilitant l'intégration avec les systèmes externes.
Outils de surveillance de la disponibilité des serveurs – résumé
Un système de surveillance des serveurs permet un contrôle ininterrompu de l'environnement informatique. Le bon choix et la mise en œuvre d'un outil de surveillance garantissent le bon entretien des services, ainsi que la sécurité, la stabilité et le confort lors de la gestion d'une entreprise. Une configuration appropriée avec la fonction d'alerte permet une réponse rapide même avant qu'un problème dans l'infrastructure ne survienne. Dans le cadre de nos services DevOps, nous pouvons vous aider à choisir et à mettre en œuvre une solution qui conviendra le mieux aux besoins de votre entreprise.









