
Termes d'IA que vous devez connaître. Deuxième partie – 31 expressions avancées et solutions d'IA

Notre article précédent sur les termes de l'IA vous a présenté le dictionnaire de base. Dans cette partie, nous allons plonger dans des phrases plus spécialisées qui vous aideront à comprendre le discours technique et vous permettront de discuter des systèmes d'IA avec des personnes plus orientées vers la technologie. Vous trouverez également des explications sur le fonctionnement interne des solutions d'IA existantes telles que ChatGPT, Stable Diffusion, HuggingFace, etc.
Termes avancés de l'IA
Notre précédent article incluait des termes de base en IA, tels que big data, chatbot, ajustement fin et modèle de langage large (LLM). Ce billet de blog présentera des informations plus avancées, mais il est bénéfique de comprendre cette terminologie fondamentale.
Réseau neuronal artificiel
C'est un système informatique inspiré des réseaux neuronaux biologiques des cerveaux d'animaux. Ces réseaux se composent d'unités interconnectées (neurones) qui traitent les données et peuvent apprendre à effectuer des tâches. Un seul neurone est appelé "perceptron." Il se compose d'entrées multipliées par des poids associés, d'un nœud de sommation et d'une fonction d'activation déterminant la sortie d'un neurone.
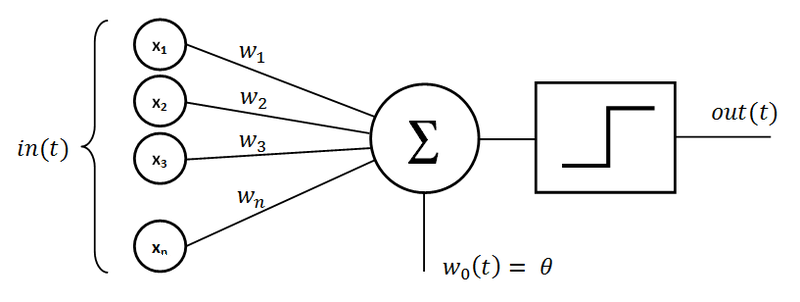
Source : wikipedia.org
Classificateur
Un classificateur est un type de modèle d'IA utilisé dans l'apprentissage machine pour des tâches de catégorisation. Il attribue des étiquettes ou des catégories aux données d'entrée en fonction de modèles appris. Les classificateurs sont largement utilisés dans des applications comme la détection de spam, la reconnaissance d'image et l'analyse de sentiments.
Fenêtre de contexte
Ce terme fait référence à une caractéristique essentielle des modèles de langage large (LLM) qui détermine l'étendue des données d'entrée qu'ils peuvent prendre en compte à tout moment. La fenêtre de contexte représente le nombre de tokens qu'un LLM peut traiter ou "se souvenir" lors d'une interaction. En termes pratiques, cette fonctionnalité est cruciale pour maintenir la cohérence et la continuité des conversations ou des tâches de génération de texte.
En tant que LLM, comme ceux de la série GPT (Generative Pre-trained Transformer), gèrent des entrées, ils intègrent l'historique conversationnel avec de nouvelles invites. Sans une fenêtre de contexte suffisamment large, ces modèles pourraient traiter chaque entrée indépendamment, conduisant à des réponses qui semblent déconnectées de la conversation en cours. La taille de la fenêtre de contexte est généralement spécifiée comme un nombre de tokens.
Par exemple, le modèle GPT-3.5-turbo d'OpenAI a une fenêtre de contexte de 16 385 tokens. Cela signifie qu'après avoir traité ce nombre de tokens (y compris les entrées utilisateur et les réponses du modèle), le modèle commence à “oublier” les premières parties de l'interaction. Dans de tels cas, il pourrait être nécessaire de réitérer ou de résumer les points clés de la conversation pour que le modèle reste aligné avec le contexte de la discussion.
En revanche, le GPT-4-turbo-1106 plus avancé bénéficie d'une fenêtre de contexte nettement plus grande de 128 000 tokens. Cette fenêtre expansive permet des interactions beaucoup plus longues, permettant au modèle de traiter et de répondre à des textes étendus, comme un livre entier tel que "Harry Potter et le Prisonnier d'Azkaban", au sein d'une seule conversation. Cette avancée améliore grandement la capacité du modèle à s'engager dans des dialogues détaillés et étendus, fournissant des réponses plus pertinentes et conscientes du contexte.
Aborder les limitations de la fenêtre de contexte a conduit à diverses solutions. Une approche courante est la "fenêtre de contexte roulante", où seuls les tokens les plus récents dans la limite sont fournis au modèle, maintenant efficacement les parties les plus récentes et pertinentes de la conversation. Des méthodes plus sophistiquées incluent l'utilisation d'une autre requête LLM pour résumer la conversation jusqu'ici et optimiser l'utilisation des tokens pour la rétention du contexte.
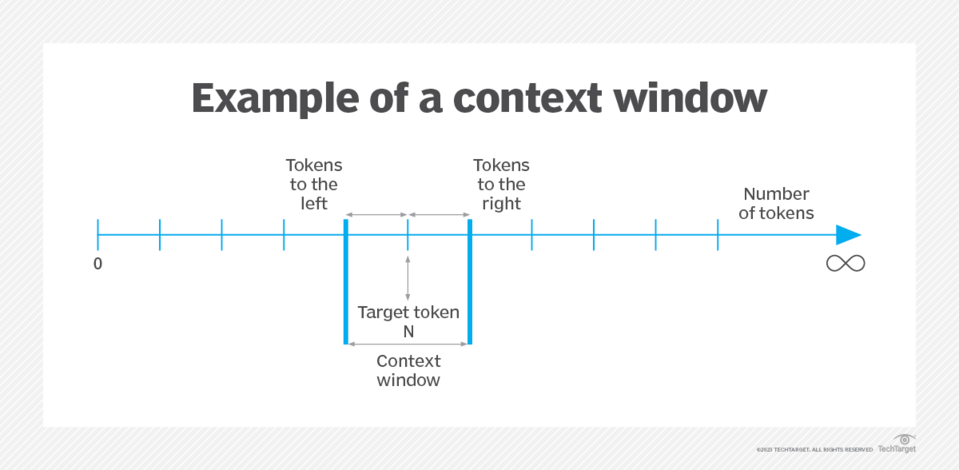
Source : techtarget.com
Apprentissage profond
Un sous-ensemble de l'apprentissage machine, l'apprentissage profond utilise des réseaux neuronaux avec plusieurs couches (d'où "profond") pour analyser divers facteurs de données. Il excelle dans des tâches comme la reconnaissance d'images et de voix, où il peut apprendre des modèles complexes et prendre des décisions avec une grande précision.
Encodage>
Dans le contexte de l'IA et du traitement du langage naturel, l'encodage se réfère au processus de conversion de données, telles que du texte, en un ensemble de vecteurs dans un espace de haute dimension. Cette transformation permet de représenter des données complexes telles que des mots, des phrases ou même des documents entiers dans un format que les modèles d'IA, en particulier les réseaux neuronaux, peuvent traiter. Ces représentations vectorielles capturent des relations sémantiques et syntaxiques dans les données, permettant au modèle de comprendre et de travailler plus efficacement avec le langage naturel.
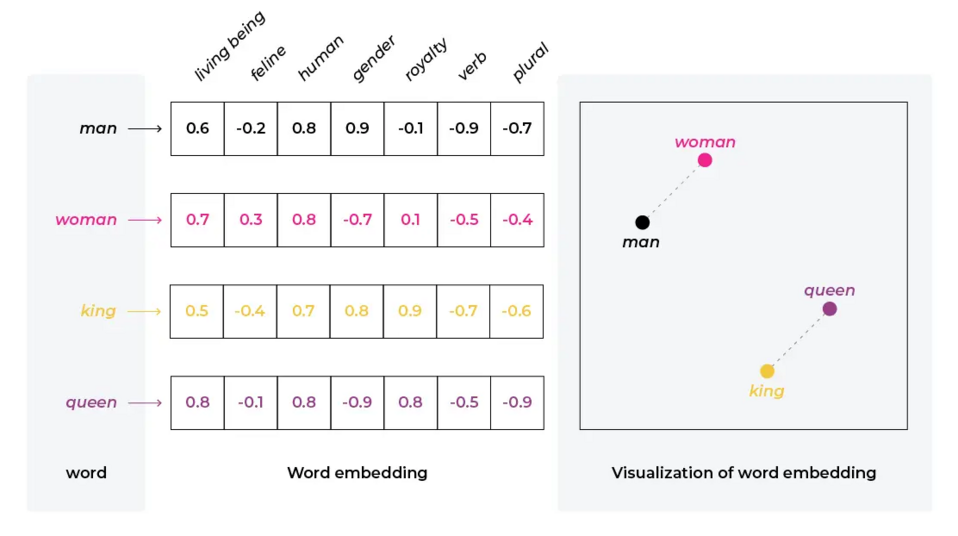
Exemple de représentation vectorielle des mots, source : arize.com
Transformateur préentraîné génératif
Un Transformateur Préentraîné Génératif est une série de modèles de langage à grande échelle développés par OpenAI. Les modèles GPT sont entraînés sur des ensembles de données textuelles diversifiées et peuvent générer un texte ressemblant à celui des humains. Grâce à leur capacité à comprendre et à générer un texte contextuellement pertinent, ils sont polyvalents dans diverses tâches linguistiques, y compris la traduction, les réponses aux questions, et la création de contenu.
Hallucination
Dans le domaine des modèles de langage large (LLM), l'hallucination se réfère à au phénomène où le modèle génère des informations incorrectes ou trompeuses, souvent en réponse à des questions en dehors de sa portée de données d'entraînement. Ce comportement se traduit par le fait que le modèle "fabrique" des détails ou présente de fausses informations. Par exemple, un LLM pourrait suggérer des classes ou fonctions inexistantes dans des contextes de codage.
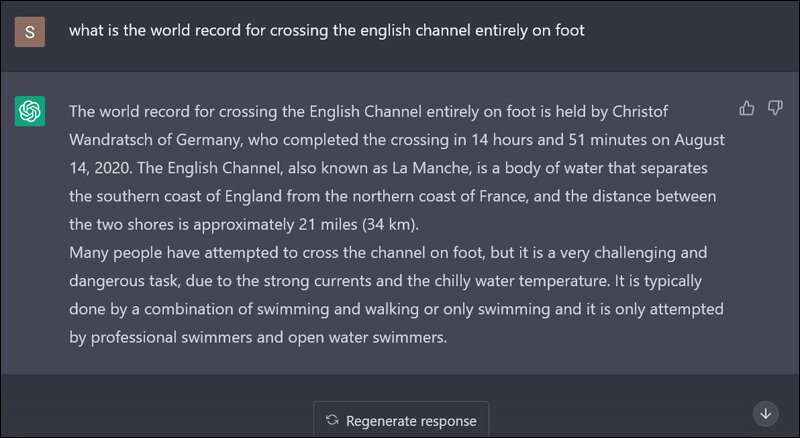
Exemple d'hallucinations, source : sify.com
De même, dans des requêtes de connaissances générales, il pourrait affirmer incorrectement que Zair est le seul pays commençant par "Z", en négligeant ou omettant des pays comme le Zimbabwe. Les hallucinations dans les LLM soulignent les limites de ces modèles, notamment lorsqu'il s'agit de questions ou de tâches nécessitant une exactitude factuelle ou se situant au-delà des limites de leur base de connaissances formées.
Hypernetworking
Ce terme se réfère à une nouvelle approche dans le domaine des réseaux neuronaux, où un réseau, connu sous le nom d'hyperréseau, est utilisé pour générer les poids pour un autre réseau. Ce concept introduit un niveau supplémentaire d'abstraction et de complexité dans la conception et l'entraînement des réseaux neuronaux.
Dans les hyperréseaux, l'accent principal est mis sur l'optimisation de l'hyperréseau lui-même, qui détermine la configuration et la performance du réseau cible. Cette méthode peut potentiellement améliorer l'efficacité de l'entraînement des réseaux neuronaux et permettre des comportements de réseau plus dynamiques et adaptatifs.
Les hyperréseaux représentent un domaine de pointe dans la recherche sur les réseaux neuronaux, explorant de nouvelles façons de tirer parti des relations entre différents réseaux pour un apprentissage et une résolution de problèmes plus efficaces. Pour une exploration détaillée de ce concept, voir ce document de recherche sur arXiv.
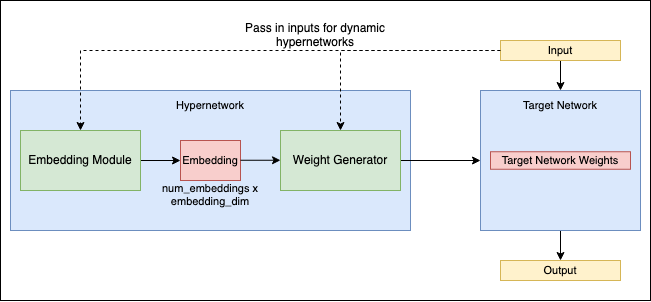
Source : github.com
Inférence
En IA, l'inférence se réfère au processus où un modèle entraîné fait des prédictions ou des décisions basées sur de nouvelles données non vues. C'est l'étape où le modèle applique ce qu'il a appris à des applications du monde réel.
Espace latent
En apprentissage machine, l'espace latent se réfère à une représentation compressée des données d'entrée, souvent sous une forme de dimension inférieure. Il capture les aspects essentiels des données et est utilisé dans les modèles génératifs.
Adaptation de Rang Faible (LORA)
LORA représente une technique spécialisée principalement utilisée dans les modèles de Diffusion, et elle est également applicable aux modèles de langage large (LLM). Dans cette approche, des modèles auxiliaires plus petits sont développés pour fonctionner conjointement avec un "modèle complet." Ils opèrent en injectant leurs poids dans une composante spécifique du modèle plus grand, généralement la "couche Cross Attention", qui joue un rôle crucial dans l'étape finale de la génération de sortie.
Par exemple, dans la génération d'images utilisant un modèle de diffusion, si le but est de créer des images de style anime d'une personne spécifique, plutôt que de peaufiner l'ensemble du modèle de diffusion sur les images de cette personne, un LORA serait entraîné sur ces images et ensuite utilisé avec un modèle capable d'anime. Cette combinaison permet au modèle plus grand de générer des images de style anime personnalisées de l'individu.
De même, dans le contexte des LLM, LORA peut être employé pour introduire de nouveaux concepts ou domaines de connaissance dans le modèle sans avoir besoin de réentraînements extensifs de l'ensemble du modèle. Cette technique offre un moyen plus efficace et ciblé d'améliorer et de personnaliser les modèles d'IA pour des tâches ou styles spécifiques.
Apprentissage automatique
Un sous-ensemble central de l'IA, l'apprentissage machine implique l'entraînement d'algorithmes pour prendre des décisions ou des prédictions basées sur des données. Il inclut diverses techniques comme l'apprentissage supervisé, l'apprentissage non-supervisé et l'apprentissage par renforcement. L'apprentissage machine automatise la construction de modèles analytiques, permettant aux systèmes d'apprendre et de s'adapter à partir de l'expérience sans être explicitement programmés.
Apprentissage par renforcement
L'apprentissage par renforcement est un type d'apprentissage machine où un agent apprend à prendre des décisions en exécutant des actions dans un environnement pour atteindre un certain objectif. L'agent apprend par essais et erreurs, recevant des récompenses ou des pénalités pour ses actions, renforçant ainsi les comportements favorables. Par exemple, cette technique peut être utilisée pour enseigner à un algorithme à jouer à un jeu vidéo simplement en interagissant avec lui.
Apprentissage supervisé
L'apprentissage supervisé est une approche d'apprentissage machine où les modèles sont entraînés sur des données étiquetées. Le modèle apprend à prédire des sorties à partir de données d'entrée, et sa performance est mesurée par rapport à des étiquettes connues. Cette approche utilise un ensemble de données pour que le modèle apprenne sous la forme de vecteurs, qui contiennent l'entrée et la sortie attendue. En fonction de la différence entre la sortie attendue, le comportement de l'algorithme est ajusté (par exemple, en utilisant la rétropropagation dans les réseaux neuronaux artificiels).
Transformateur
Derrière ce terme de l'IA se trouve une architecture de réseau neuronal révolutionnaire qui a considérablement fait progresser le domaine du traitement du langage naturel. Les transformateurs sont conçus pour gérer des données séquentielles et sont notables pour leur mécanisme d'attention de soi, qui leur permet de mesurer l'importance de différentes parties des données d'entrée. Ils sont à l'origine de nombreux modèles de langage de pointe comme GPT et BERT.
Apprentissage non supervisé
Contrairement à l'apprentissage supervisé, cette approche implique l'entraînement de modèles sur des données sans étiquettes prédéfinies. Le modèle apprend des motifs et des structures à partir des données elles-mêmes.
Autoencodeur Variationnel (VAE)
Un VAE est un type de modèle génératif utilisé en apprentissage machine, principalement connu pour sa capacité à encoder les données d'entrée en un espace latent compressé et ensuite reconstruire l'entrée depuis cet espace. Le modèle se compose de deux composants principaux : un encodeur qui compresse les données dans l'espace latent et un décodeur qui reconstruit les données à partir de cet espace.
Les VAE sont particulièrement efficaces dans les tâches de génération d'images. Ils peuvent apprendre à produire de nouvelles images qui ressemblent étroitement aux données d'entraînement originales, permettant la création de styles diversifiés et d'images réalistes.
Par exemple, les VAE peuvent être employés dans un système plus large où les modèles de diffusion font partie, notamment dans les tâches impliquant le codage et la reconstruction d'images. Cependant, le processus central de transformation du bruit en images cohérentes dans les modèles de diffusion est généralement géré par le processus de diffusion lui-même plutôt que par un VAE.
Vecteur
Dans le contexte de l'apprentissage machine et de l'IA, un vecteur est un tableau de nombres représentant des données. En NLP, par exemple, les mots sont souvent convertis en vecteurs, que les algorithmes utilisent pour traiter et comprendre le texte.
Base de données vectorielle – elle est spécifiquement conçue pour stocker et interroger des données vectorielles, qui sont des représentations de points de données dans un espace de haute dimension. Ce type de base de données est particulièrement pertinent dans les scénarios impliquant des encodages, où divers types de données, telles que le texte ou les images, sont transformés en un format vectoriel.
La force principale d'une base de données vectorielle réside dans sa capacité à effectuer des opérations telles que des recherches de similarité de manière efficace. Cette capacité est cruciale dans diverses applications, y compris les systèmes de recommandation. Leur objectif est de trouver des éléments similaires aux intérêts d'un utilisateur et aux tâches de récupération d'images, où l'objectif est de localiser des images visuellement similaires à une image de requête.
Exemple d'application dans le monde réel – un cas d'utilisation pratique des bases de données vectorielles est d'améliorer les capacités d'un modèle de langage large (LLM). Par exemple, plutôt que de peaufiner un LLM avec des données spécifiques d'un site web, le contenu du site web peut être stocké sous forme de vecteurs dans une base de données vectorielle. Lorsqu'une requête utilisateur est reçue, la base de données vectorielle peut être consultée pour trouver les vecteurs de contenu les plus pertinents qui correspondent étroitement à la requête.
Ces vecteurs pertinents peuvent ensuite être alimentés comme contexte supplémentaire dans l'invite du LLM. Cette approche permet au modèle de générer des réponses qui sont plus alignées avec le contenu et les thèmes spécifiques du site web, fournissant ainsi des réponses plus précises et contextuellement appropriées aux requêtes des utilisateurs.
Outils, solutions et sites Web utiles de l'IA
En plus des termes avancés de l'IA, il est également utile de se familiariser avec les outils et les sites Web de ce domaine qui peuvent être utiles pour diverses activités. Il est impossible de lister un nombre fini d'exemples de ces solutions, car de nouvelles sont créées tout le temps. Cependant, nous fournissons notre sélection subjective.
Automatic1111/stable diffusion webUI
Automatic1111/stable diffusion webUI - appelé Automatic1111 ou A1111 par la communauté, est une implémentation populaire du modèle Stable Diffusion, souvent utilisé pour les tâches de génération d'images. Il est connu pour son interface conviviale et son traitement efficace, rendant la synthèse d'images avancée plus accessible. Cette implémentation permet aux utilisateurs d'insérer un large éventail de points de contrôle de modèles entraînés par la communauté pour générer des images dans différents styles. Il permet également la génération d'image à image, l'inpainting, l'upscaling des images générées, l'entraînement et la fusion des points de contrôle du modèle.
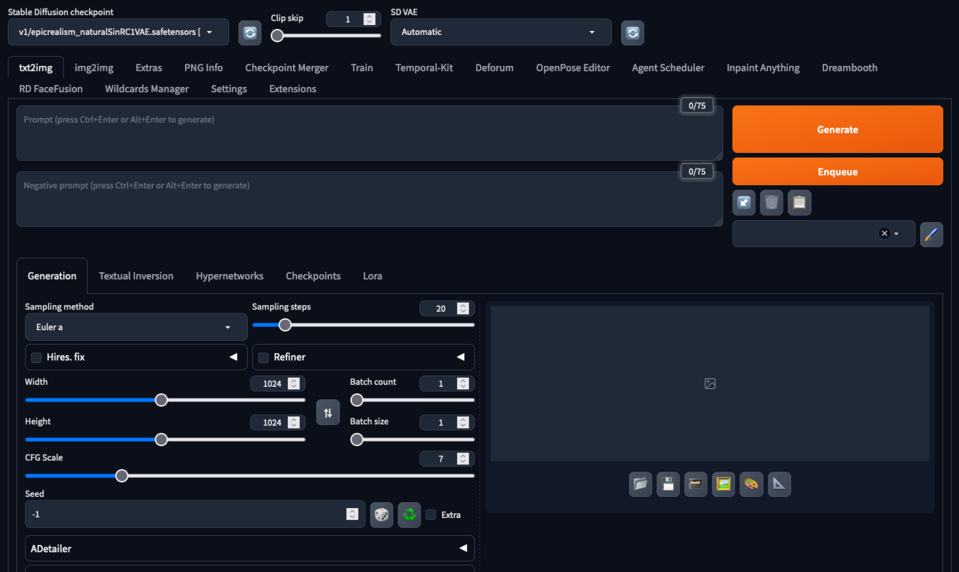
Interface Automatic1111
Google Bard
Bard est un chatbot génératif conversationnel développé par Google. Initialement basé sur la famille LaMDA de modèles de langage large (LLM), il a ensuite été mis à niveau vers PaLM puis Gemini. Bard a été créé en réponse à l'ascension de ChatGPT d'OpenAI et a été lancé en capacité limitée en mars 2023. Son développement et son lancement faisaient partie de l'intensification de l'intérêt de Google pour l'IA face à la montée en importance de ChatGPT. Bard est conçu pour fonctionner de manière similaire à ChatGPT, offrant des services d'IA conversationnelle mais avec une intégration dans les capacités de recherche de Google et d'autres produits.
ChatGPT
Développé par OpenAI, ChatGPT est une variante du modèle d'IA GPT (Generative Pre-trained Transformer), conçu spécifiquement pour générer un texte ressemblant à celui des humains dans un contexte conversationnel. Il excelle dans diverses tâches linguistiques, y compris la conversation, la réponse aux questions, et l'achèvement de texte.
CivitAI
CivitAI est une plateforme axée sur l'IA générative, hébergeant une variété de modèles et d'outils open-source. Le site présente une collection d'images et de modèles créés par la communauté, montrant des applications allant des formes simples aux paysages complexes et aux visages humains. Civitai sert de centre de créativité et d'inspiration. Il offre des ressources, des guides et des tutoriels sur l'IA générative. Le site organise également des défis et des événements, encourageant l'engagement et la collaboration de la communauté dans le domaine de l'art et du contenu générés par l'IA.
CLIP
Contrastive Language-Image Pre-Training (CLIP) est un type de modèle de réseau neuronal développé par OpenAI qui est formé sur une gamme diversifiée de paires d'images et de texte. Cette approche innovante permet au modèle de comprendre et d'interpréter les images dans le contexte du langage naturel. Une des capacités critiques de CLIP est sa capacité à associer efficacement des images avec des descriptions textuelles.
DALL-E
Également développé par OpenAI, DALL-E est un modèle de diffusion d'IA connu pour sa capacité à générer des images créatives et détaillées à partir de descriptions textuelles. Il illustre le potentiel de l'IA dans les applications artistiques et créatives. Dans la dernière version, il est intégré dans le ChatGPT, permettant la génération d'images via l'interface du chatbot et exploitant la capacité du modèle de conversation à affiner les invites des utilisateurs.

Graphismes générés par Dall-E 2 basés sur l'invite "logiciel maison Drupal"

Dall-E 3, avec son interface intégrée dans le ChatGPT
HuggingFace
HuggingFace est une entreprise et plateforme connue pour son vaste répertoire de modèles pré-entraînés et d'outils dans le traitement du langage naturel. Cette solution offre une passerelle accessible pour implémenter et expérimenter des modèles d'IA avancés. C'est le foyer de nombreux LLM open-source et modèles de diffusion.
Stable Diffusion
Introduit en 2022, Stable Diffusion est un modèle de diffusion de texte en image développé par Stability AI. Il génère des images détaillées basées sur des descriptions textuelles en utilisant un autoencodeur variationnel (VAE), un U-Net, et un encodeur de texte optionnel. Le modèle compresse les images dans un espace latent de dimension plus petite, appliquant du bruit gaussien de manière itérative pendant la diffusion avant. Le bloc U-Net, avec un backbone ResNet, débruite la sortie, et le décodeur VAE convertit ensuite la représentation dans l'espace pixel.
Stable Diffusion peut être conditionné sur du texte et des images avec l'encodeur de texte CLIP transformant les invites textuelles en un espace d'encodage. Avec son architecture relativement légère et sa capacité à fonctionner sur des GPUs grand public, Stable Diffusion a marqué une rupture avec les modèles propriétaires précédents comme DALL-E, qui étaient basés sur le cloud.

Génération Stable Diffusion pour l'invite : "logiciel maison Drupal", point de contrôle utilisé - “epicRealism”
LLAMA
Large Language Model Meta AI (LLAMA) est une famille de modèles de langage large publiée par Meta AI en février 2023. Elle comprend des modèles avec 7, 13, 33 et 65 milliards de paramètres. Les modèles LLaMA ont montré une performance notable sur divers benchmarks de NLP, le modèle de 13 milliards de paramètres surpassant GPT-3 (175 milliards de paramètres) dans certaines tâches.
Ces modèles sont significatifs pour leur accessibilité. Meta a publié les poids du modèle de LLaMA à la communauté de recherche sous licence non commerciale. En juillet 2023, en partenariat avec Microsoft, Meta a introduit LLaMA-2 avec des tailles de modèles de 7, 13 et 70 milliards de paramètres. LLaMA-2 inclut des modèles de base et des modèles affinés pour le dialogue, appelés LLaMA-2 Chat, et offre des améliorations en matière de formation aux données et de mesures de sécurité. Cependant, peu de temps après sa sortie, les poids de LLaMA ont fuité en ligne, conduisant à une large distribution.
Midjourney
Midjourney est un programme d'IA générative créé par le laboratoire de recherche indépendant basé à San Francisco Midjourney, Inc. Il génère des images à partir de descriptions en langage naturel, similaire à DALL-E d'OpenAI et Stable Diffusion de Stability AI. Midjourney est entré en bêta ouverte en juillet 2022 et est accessible via un bot Discord. Cet outil a été utilisé pour diverses applications créatives, y compris le prototypage rapide dans les arts. Les capacités de génération d'images de Midjourney ont également été un sujet de débat et de controverse, en particulier concernant l'originalité et l'éthique de l'art généré par l'IA.
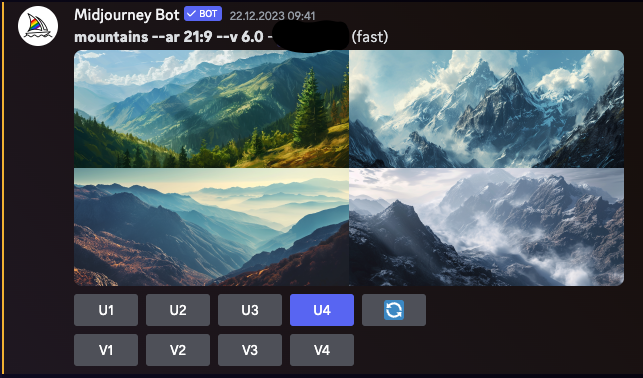
Images générées en utilisant la version 6.0 de Midjourney (l'interface Discord est clairement visible)
Pinecone
Pinecone est une solution de base de données vectorielle conçue pour gérer des données de haute dimension efficacement. Pinecone est particulièrement utile pour les applications de recherche de similarité, souvent dans les contextes d'apprentissage machine et d'IA.
text-generation-webui
text-generation-webui est une interface web basée sur Gradio conçue pour interagir avec divers modèles de langage large (LLM). Elle prend en charge une gamme de modèles tels que transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), et Llama models. L'interface vise à être conviviale, offrant plusieurs modes comme le mode cahier et le chat. Elle inclut de nombreuses fonctionnalités comme le support pour différentes architectures de modèles, un menu déroulant pour le changement de modèles et de checkpoints, et une intégration avec des extensions pour des fonctionnalités supplémentaires comme la mémoire à long terme ou la synthèse vocale. Le dépôt fournit des instructions détaillées pour l'installation et l'utilisation, le rendant accessible aux utilisateurs cherchant à exploiter les LLM pour des tâches de génération de texte.
Whisper
Développé par OpenAI, Whisper est un modèle de reconnaissance vocale conçu pour fournir des capacités de conversion de la parole en texte (STT). Il vise à transcrire avec précision l'audio en texte, en reconnaissant plusieurs langues et accents. Whisper est notable pour son efficacité à comprendre le langage parlé, ce qui en fait un outil précieux pour diverses applications, y compris la transcription automatisée et l'assistance à l'accessibilité pour les personnes malentendantes.
Termes et solutions avancés de l'IA – résumé
Nous espérons que cet article (surtout lorsqu'il est combiné avec la première partie sur la terminologie de base) servira de tremplin dans le monde plus large de l'IA, qui est un domaine en constante évolution, nouveau et excitant. Que ce dictionnaire de l'IA vous inspire à explorer le potentiel de l'intelligence artificielle ! Et si vous avez une idée de projet qui bénéficierait du développement de l'IA, nos développeurs expérimentés sont là pour vous aider.










